Hadoop生态系统为大数据领域提供了开源的分布式存储和分布式计算的平台,这一章我们进行Hadoop生态系统的入门学习,介绍其中分布式文件系统HDFS、分布式资源调度YARN、分布式计算框架MapReduce(包含Spark的入门以及和MapReduce的比较),最后通过Spring Boot集成Hadoop来访问文件系统。
大数据的应用
本人喜欢体育运动,以体育中来举列子。
足球点球大战
2006年世界杯中德国队和阿根廷队的点球大战中,德国队守门员教练科普克,给了门将莱曼一张纸条,莱曼看过纸条将计就计。阿根廷队的每个点球,几乎都被莱曼判断对了方向,并成功扑出坎比亚索和阿亚拉的点球,帮助德国队打进四强。而这张纸条就是根据数据分析记录了阿根廷队员点球的习惯方向。
金州勇士的崛起
如今越来越多的篮球队开始重视和应用篮球大数据,比如NBA中的金州勇士队。勇士队曾长期以来一直是NBA里最烂的球队之一,2009年它的成绩排名倒数第二。没有任何执教NBA经验的史蒂夫·科尔,因突出的投篮优势被委任为教练。科尔在执掌勇士队之后,坚持用数据说话而不是凭经验。他根据数据工程师对历年来NBA比赛的统计,发现最有效的进攻是眼花缭乱的传球和准确的投篮,而不是彰显个人能力的突破和扣篮。在这个思想的指导下,勇士队队员苦练神投技。这其中最亮眼的新打法是尽可能地从24英尺(大约7.3米)外的三分线投篮,这样可以得3分。于是开发了小球时代,在2015-2018摘下三枚总冠军,成功成为NBA的霸主。
大数据的基本概率
有人说大数据的特点就是数据量大,这个不是非常的正确,数据量大不是关键,通过数据分析在数据中提取出价值,最终带来商业上的利益,这才是大数据分析的最终目标。大数据有4个特点,一般我们称之为4V,分别为:
- Volume(大量):随着信息技术的高速发展,数据开始爆发性增长。社交网络(微博、推特、脸书)、移动网络、各种智能工具,服务工具等,都成为数据的来源。数据的存储也从过去的GB到TB,乃至现在的PB、EB级别。
- Variety(多样):广泛的数据来源,决定了大数据形式的多样性。任何形式的数据都可以产生作用。
- Velocity(高速):大数据的产生非常迅速,主要通过互联网传输。大数据对处理速度有非常严格的要求,服务器中大量的资源都用于处理和计算数据,很多平台都需要做到实时分析。数据无时无刻不在产生,谁的速度更快,谁就有优势。
- Value(价值):这也是大数据的核心特征。通过从大量不相关的各种类型的数据中,挖掘出对未来趋势与模式预测分析有价值的数据,并通过机器学习方法、人工智能方法或数据挖掘方法深度分析,发现新规律和新知识,并运用于农业、金融、医疗等各个领域,从而最终达到改善社会治理、提高生产效率、推进科学研究的效果。
大数据涉及到的技术
- 数据采集:把海量数据收集到数据平台上来,才能做后续的数据分析。
- 数据存储:数据的存储位置。由于数据量巨大,一般为分布式存储系统,较通用用的为。
- 数据分析:对数据进行有效性分析(数据分析框架MapReduce,spark等)。
- 可视化:把分析结果可视化展示。
分布式文件系统HDFS
HDFS概述及设计目标
HDFS源于Google的GFS论文,设计目标为
- 非常巨大的分布式文件系统。
- 运行在普通廉价的硬件上。
- 易扩展、为用户提供性能不错的文件存储服务。
HDFS架构
HDFS是一种master/slave的架构。一个HDFS集群包含一个唯一的NameNode(NN),这个master server管理着整个文件系统的命名空间并且调节客户端对文件的访问。同时,还拥有一系列的DataNode(DN),每个都管理着他们运行的对应节点的数据存储。HDFS提供了一个文件系统的命名空间同时允许用户将数据存在这些文件上。通常,一个文件被拆分成一个或多个数据块,并且这些数据块被保存在一系列的DataNode上。NameNode执行文件系统的命名空间的相关操作比如打开、关闭、重命名目录或者文件。同时决定了数据块到DataNode的映射。DataNode为客户端的读取写入需求提供服务,同时处理NameNode发来的数据块的创建、删除、复制等需求。

HDFS副本机制
在前面说过HDFS使用相对廉价的计算机,那么宕机就是一种必然事件,我们需要让数据避免丢失,就只有采取冗余数据存储,而具体的实现就是副本机制。具体为把一个文件分为很多的块,一个块默认为128M,而这些块是以多副本的形式存储。比如存储三个副本:
- 第一副本:如果上传节点是DataNode(DN),则上传该节点;如果上传节点是NameNode(NN),则随机选择DataNode(DN) 。
- 第二副本:放置在不同机架的DataNode(DN)上 。
-
第三副本:放置在与第二副本相同机架的不同DataNode(DN)上。
这种方式可以极大程度上避免了宕机所造成的数据丢失。而数据库的存储的元数据是存储在NameNode(NN)中,在数据读取是可以知道在那些节点上读取文件。下面是官方架构图。
 image.png
image.png
HDFS环境搭建
Apache Hadoop 有版本管理混乱,部署过程繁琐、升级过程复杂,兼容性差等缺点,而CDH是Hadoop众多分支中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop构建。使用CDH可以避免在使用过程中的依赖包冲突问题,对版本的升级也很方便,所以我们使用Hadoop-2.6.0-cdh5.7.0版本进行安装。本人是使用虚拟机进行伪分布式模式的搭建,即在一台机器上安装,集群模式其实和伪分布式模式差不太多。
- 第一步安装JDK
//把压缩包jdk-8u181-linux-i586.tar.gz上传到虚拟机
rz 选择文件上传
//在根目录下建立解压文件夹
mkdir apps
//解压jdk到apps目录
tar -zxvf jdk-8u181-linux-i586.tar.gz -C ~/apps/
//添加环境变量
vi ~/.bash_profile
//在编辑模式添加以下内容
export JAVA_HOME=/root/apps/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
//编辑完成后,保存退出
//使配置生效
source ~/.bash_profile
//验证
java -version
//若出现版本信息表示安装成功
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode)
- 第二步安装SSH
//安装SSH
sudo yum install ssh
//生成密钥文件
ssh-keygen -t rsa
//配置免密钥登录:复制公钥到authorized_keys,因为NameNode(NN)需要连接访问DataNode(DN),配置后可直接访问不用登录,在集群环境下需要复制到其它节点。
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
- 安装hadoop
下载:直接去cdh网站下载 [http://archive.cloudera.com/cdh5/cdh/5/]
//解压
tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ~/app
//配置环境变量
export HADOOP_HOME=/root/apps/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
//hadoop配置文件的修改(hadoop_home/etc/hadoop/)
hadoop-env.sh:
export JAVA_HOME=/root/apps/jdk1.8.0_181
core-site.xml:
fs.defaultFS
hdfs://192.168.30.130:8092 //配置NameNode(NN)地址
hadoop.tmp.dir
/home/hadoop/app/tmp //因为HDFS默认是存储在零时文件中,关机后会丢失,这个配置持久化文件
hdfs-site.xml:
dfs.replication //设置副本系数,这里因为只有一个节点,所以设置为1
1
slaves:
localhost
在里面配置节点,现配置为虚拟机本地。如果为集群模式,则需要在里面配置其它节点的地址。
启动hdfs:
//格式化文件系统(仅第一次执行即可,不要重复执行)
hdfs/hadoop namenode -format
//启动
hdfs: sbin/start-dfs.sh
//验证是否启动成功:
jps //该命令会有以下三个进程
DataNode
SecondaryNameNode
NameNode
浏览器访问方式: http://虚拟机地址:50070 有hdfs主界面
//停止hdfs
sbin/stop-dfs.sh
HDFS shell
HDFS shell的命令有很多,输入hadoop fs回车,会有有多命令的提示。
Usage: hadoop fs [generic options]
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] ... ]
[-copyToLocal [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] [-h] [-v] ...]
[-cp [-f] [-p | -p[topax]] ... ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ ...]]
[-du [-s] [-h] ...]
[-expunge]
[-find ... ...]
[-get [-p] [-ignoreCrc] [-crc] ... ]
[-getfacl [-R] ]
[-getfattr [-R] {-n name | -d} [-e en] ]
[-getmerge [-nl] ]
这里介绍HDFS shell常用命令的使用(其实和Linux命令相似)
//查看文件目录ls
hadoop fs -ls / 查看根目录
//建立目录mkdir
hadoop fs -mkdir 文件目录
//上传文件 put
hadoop fs -put 本地文件路径 hdfs文件路径
//get 下载文件到本地
hadoop fs -get hdfs文件路径
//删除文件/文件夹rm
hadoop fs -rm 文件
hadoop fs -rm -R 文件夹 //级联删除
Java API操作HDFS
IDEA+Maven创建Java工程
添加HDFS相关依赖
1.8
2.6.0-cdh5.7.0
org.apache.hadoop
hadoop-client
${hadoop.version}
junit
junit
4.10
cloudera
http://repository.cloudera.com/artifactory/cloudera-repos/ //hadoop仓库
开发Java Api操作HDFS文件使用Junit测试的方式,代码如下
public class JunitTest {
FileSystem fileSystem = null;
Configuration configuration = null;
public static final String URL = "hdfs://192.168.30.130:8092";
@Before
public void setUp() throws IOException, InterruptedException {
//初始化配置
configuration = new Configuration();
//初始化FileSystem,其中包含了文件操作的函数,其中root为虚拟机用户名
fileSystem = FileSystem.get(URI.create(URL),configuration,"root");
}
@Test
public void mkdir() throws IOException {
//创建目录
fileSystem.mkdirs(new Path("/test"));
}
@Test
public void create() throws IOException {
//创建文件,得到输出流对象
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path("/test/test.txt"));
//写入文件内容
fsDataOutputStream.write("hello dzy".getBytes());
//关闭流
fsDataOutputStream.close();
}
@After
public void setDown() throws IOException {
configuration.clear();
fileSystem.close();
}
}
在以上只是实验了几个API还有很多其它的API,感兴趣的可以继续学习。
HDFS文件读写流程
三个角色的交互 客户端/NameNode/DataNode
HDFS写流程
- 客户端向NameNode发出写文件请求。
- 检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功) - client端按128MB的块切分文件。
- client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
(注:并不是写好一个块或一整个文件后才向后分发) - 每个DataNode写完一个块后,会返回确认信息。
- 写完数据,关闭输输出流。
- 发送完成信号给NameNode。
(注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性)
HDFS读流程
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流
HDFS优缺点
优点
- 支持超大文件。
- 检测和快速应对硬件故障:在集群的环境中,硬件故障是常见的问题。因为有上千台服务器连接在一起,这样会导致高故障率。因此故障检测和自动恢复是hdfs文件系统的一个设计目标。
- 流式数据访问:Hdfs的数据处理规模比较大,应用一次需要访问大量的数据,同时这些应用一般都是批量处理,而不是用户交互式处理。应用程序能以流的形式访问数据集。主要的是数据的吞吐量,而不是访问速度。
- 简化的一致性模型:在hdfs中,一个文件一旦经过创建、写入、关闭后,一般就不需要修改了。这样简单的一致性模型,有利于提高吞吐量。
缺点
- 低延迟数据访问:如和用户进行交互的应用,需要数据在毫秒或秒的范围内得到响应。由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟来说,不适合用hadoop来做。
- 大量的小文件:Hdfs的NameNode中存储了文件分块的元数据信息,如果有大量的小文件,导致元数据信息增加,增加NameNode负荷。
- 不支持超强的事务:没有像关系型数据库那样,对事务有强有力的支持。
资源调度框架YARN
YARN概述
YARN是Hadoop 2.0中的资源管理系统,可以让不同计算框架(MapReduce\Spark等)可以共享同一个HDFS集群上的数据,享受整体的资源调度。
YARN架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
- ResourceManager是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等。
- NodeManager是Slave上一个独立运行的进程,负责上报节点的状态,处理单个节点的资源管理 、处理来自ResouceManager的命令 、处理来自ApplicationMaster的命令。
- ApplicationMaster和Container是运行在Slave上的组件,为应用程序申请资源,并分配给内部任务 ,任务的监控和容错等。
- Container是yarn中分配资源的一个单位,包涵内存、CPU等等资源,yarn以Container为单位分配资源。
YARN执行流程
YARN总体上仍然是master/slave结构,在整个资源管理框架中,resourcemanager为master,nodemanager是slave。Resourcemanager负责对各个nademanger上资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。
流程:
- 客户端向RM中提交程序
- RM向NM中分配一个container,并在该container中启动AM
- AM向RM注册,这样用户可以直接通过RM査看应用程序的运行状态(然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束)
- AM采用轮询的方式通过RPC协议向RM申请和领取资源,资源的协调通过异步完成
- AM申请到资源后,便与对应的NM通信,要求它启动任务
- NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务
- 各个任务通过某个RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务
-
应用程序运行完成后,AM向RM注销并关闭自己
 image.png
image.png
YARN环境搭建
使用的版本为hadoop-2.6.0-cdh5.7.0
//修改配置文件,配置如下(配置文件在/etc/hadoop下)
mapred-site.xml,在默认情况下是没有mapred-site.xml文件的,只有mapred-site.xml.template文件,所以在修改配置之前需要复制一份
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
//添加配置
mapreduce.framework.name
yarn //配置计算框架运行在yarn之上,为固定配置
yarn-site.xml:
vi yarn-site.xml
//添加配置
yarn.nodemanager.aux-services
mapreduce_shuffle //nodemanager的services,目前为固定配置,当学习Spark时,其中有动态资源调度,这里才需要修改
//启动YARN相关的进程
sbin/start-yarn.sh
//验证
jps
ResourceManager
NodeManager
可访问http://虚拟机IP:8088可以看到YARN的主界面。
//停止YARN相关的进程
sbin/stop-yarn.sh
提交作业到YARN上执行
在 share目录为我们提供了MapReduce作业的案例,我们可以使用其中的作业在YARN上执行。
提交mr作业到YARN上运行,我的作业jar包路径为:
/root/apps/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar
//使用hadoop jar命令可提交作业到YARN,具体命令为
hadoop jar jar包路径 有效的程序名字 有效程序的参数
// 选用其中PI程序进行运行,在执行之前要记到启动hdfs和yarn
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar pi 2 3
//访问yarn主界面可看到作业的执行情况
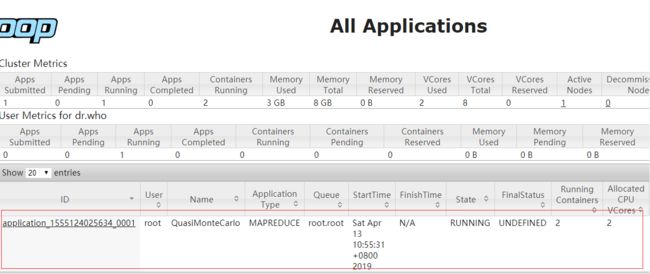
分布式处理框架MapReduce/Spark
MapReduce概述
源于Google的MapReduce论文,Hadoop MapReduce是Google MapReduce的一个克隆版。MapReduce用于大规模数据集(通常大于1TB)的并行运算,实现了Map和Reduce两个功能。MapReduce的思想是“分而治之”。“分”是把复杂的任务分解为若干个“简单的任务”执行,由map负责。“简单的任务”指数据或计算规模相对于原任务要大大缩小;就近计算,即会被分配到存放了所需数据的节点进行计算;这些小任务可以并行计算,彼此间几乎没有依赖关系。Reducer负责对map阶段的结果进行汇总。
特点:
- 海量数据离线处理
- 横向扩展,而非纵向扩展,平滑无缝的可扩展性。
- 易开发:用户不用考虑进程间的通信和套接字编程,已经为我们封装好框架。这一点只是相对于传统来讲,现在主流的Spark框架更为简单(Spark为本人知识盲区,后续学习)。
- 易运行:可运行在廉价的硬件之上。
MapReduce编程模型
MapReduce编程模型给出了分布式编程方法的5个步骤:
- 迭代,遍历输入数据,将其解析成key/value对;
- 将输入key/value对映射map成另外一些key/value对;
- 根据key对中间结果进行分组(grouping);
- 以组为单位对数据进行归约;
- 迭代,将最终产生的key/value对保存到输出文件中。
MapReduce架构
和HDFS一样,MapReduce也是采用Master/Slave的架构
MapReduce包含四个组成部分,分别为Client、JobTracker、TaskTracker和Task
- Client 客户端
每一个 Job 都会在用户端通过 Client 类将应用程序以及配置参数 Configuration 打包成 JAR 文件存储在 HDFS,并把路径提交到 JobTracker 的 master 服务,然后由 master 创建每一个 Task(即 MapTask 和 ReduceTask) 将它们分发到各个 TaskTracker 服务中去执行。 - JobTracker
JobTracke负责资源监控和作业调度。JobTracker 监控所有TaskTracker 与job的健康状况,一旦发现失败,就将相应的任务转移到其他节点;同时,JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的调度器。 -
TaskTracker
TaskTracker 会周期性地通过Heartbeat 将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。TaskTracker 使用"slot"等量划分本节点上的资源量。"slot"代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空闲slot分配给Task 使用。slot分为Map slot 和Reduce slot 两种,分别供Map Task 和Reduce Task 使用。TaskTracker 通过slot 数目(可配置参数)限定Task 的并发度。
-Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动。HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。但需要注意的是,split 的多少决定了Map Task 的数目,因为每个split 只会交给一个Map Task 处理。
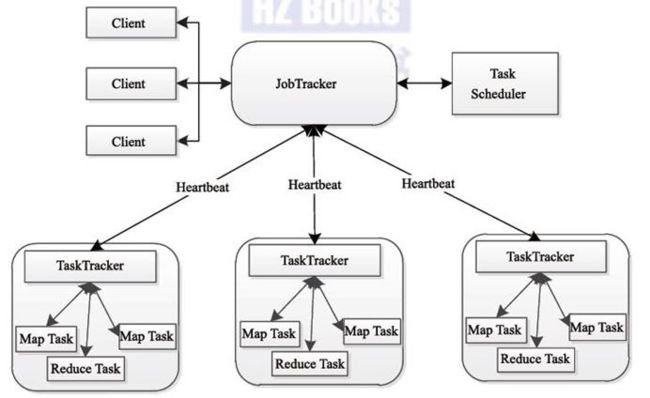 image.png
image.png
MapReduce编程
通过wordcount词频统计分析案例入门。
这个程序能够计算一个文本中相同单词出现的次数。
我们在之前演示用Java API操作HDFS的项目上编写代码。具体代码及解释如下
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* WordCount统计单词数量
*
* @author zhiying.dong 2019/04/09 20:50
*/
public class WordCountApp {
/**
* 第一步是对文件进行Map操作,继承Mapper类复写它的map方法即可
* 参数是4个,前两个LongWritable表示文件偏移量,Text表示文件的数量
* 后两个Text表示每一个单词,LongWritable为给每一个单词做一个赋值1的操作,而相同单词出现次数的累加在Reduce中
*/
public static class MyMapper extends Mapper {
LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//把文件内容转换为字符串
String line = value.toString();
//通过空格分割文件文本(本人实验的文本单词之间是以空格分开)
String[] words = line.split(" ");
for (String word : words) {
//为每个单词进行赋值操作,以map的形式输出
context.write(new Text(word), one);
}
}
}
/**
* 第二步是对文件进行Reduce操作,继承Reducer类复写它的reduce方法即可
* 参数是4个,前两个Text表示输入map的key,在这里为单词字符串,LongWritable表示输入map的value,这里表示在上一步为每个单词的赋值
* 后两个Text为输出map的key,这里表示每一个单词,LongWritable为输出map的value,这里表示每一个单词出现次数的累加
*/
public static class MyReduce extends Reducer {
//注意这里reduce输入map的value为Iterable 类型,
MapRedece为我们自动根据相同key进行了分类
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long sum = 0;
//相同key出现次数的叠加
for (LongWritable value : values) {
sum += value.get();
}
context.write(key, new LongWritable(sum));
}
}
public static void main(String[] args) throws Exception {
//初始化配置
Configuration configuration = new Configuration();
//定义job
Job job = Job.getInstance(configuration, "wordcount");
//设置job的执行类
job.setJarByClass(WordCountApp.class);
//设置需要统计的文件路径,在执行时传入
FileInputFormat.setInputPaths(job, new Path(args[0]));
//设置map操作时的相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce操作时的相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置输出文件的路径,在执行时传入
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
开发完成后
编译:mvn clean package -DskipTests
上传到服务器然后运行(根据自己上传的路径进行命令参数的调整)
hadoop jar /root/hadoop/lib/hadoop-train-1.0.jar WordCountApp hdfs://192.168.30.130:9020/hello.txt hdfs://192.168.30.130:9020/output/wc
运行完毕后可在输出文件中查看统计的结果(亲测可以成功)
注意:
相同的代码和脚本再次执行,会报错
security.UserGroupInformation:
PriviledgedActionException as:hadoop (auth:SIMPLE) cause:
org.apache.hadoop.mapred.FileAlreadyExistsException:
Output directory hdfs://92.168.30.130:9020/output/wc already exists
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException:
Output directory hdfs:/92.168.30.130:9020/output/wc already exists
在MR中,输出文件是不能事先存在的。有两种解决方式
1)先手工通过shell的方式将输出文件夹先删除
hadoop fs -rm -r /output/wc
2) 在代码中完成自动删除功能: 推荐大家使用这种方式
Path outputPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(configuration);
if(fileSystem.exists(outputPath)){
fileSystem.delete(outputPath, true);
System.out.println("output file exists, but is has deleted");
}
Spark简单入门
Spark概述
MapReduce框架局限性
- 仅支持Map和Reduce两种操作,提供给用户的只有这两种操作
- 处理效率低效:Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据
- 任务调度和启动开销大:mr的启动开销一,客户端需要把应用程序提交给resourcesManager,resourcesManager去选择节点去运行,快的话几秒钟,慢的话1分钟左右,开销二,maptask和reducetask的启动,当他俩被resourcesManager调度的时候,会先启动一个container进程,然后让他俩运行起来,每一个task都要经历jvm的启动,销毁等,这两点就是mr启动开销
- 无法充分利用内存
- Map端和Reduce端均需要排序:map和Reduce是都需要进行排序的,但是有的程序完全不需要排序(比如求最大值求最小值,聚合等),所以就造成了性能的低效
- 不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘)和流式处理(点击日志分析):因为任务调度和启动开销大,所以不适合交互式处理,比如你启动要一分钟,任务调度要几分钟,我得等半天,这不适合
- MapReduce编程不够灵活:map和reduce输入输出类型格式限制死了,可尝试scala函数式编程语言
- MapReduce采用了多进程模型,而Spark采用了多线程模型:运行更快,更加节约资源。
Spark特点
- 高效(比MapReduce快10~100倍)
- 内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销;DAG引擎,这种引擎的特点是,不同任务之间互相依赖,减少多次计算之间中间结果写到HDFS的开销;使用多线程池模型来减少task启动开稍(特指MR中每个task都要经历JVM启动运行销毁操作,Spark的做法是,启动一些常驻的进程,在进程内部会有多个线程去计算task,来一个task,计算task,并回收线程,以此循环,这样就没有JVM的开销),shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
- 易用:提供了丰富的API,支持Java,Scala,Python和R四种语言
代码量比MapReduce少2~5倍 - 与Hadoop集成:读写HDFS/Hbase与YARN集成
环境搭建
//在安装之前先要安装maven和scala环境。由于在之前本人虚拟机上已经安装了maven所以跳过maven的安装。
// 解压scala安装包
tar -zxvf scala-2.11.8.tgz -C ../apps/
//配置环境变量
pwd //查看路径
/root/apps/scala-2.11.8
vi ~/.bash.profile
//添加配置
export SCALA_HOME=/root/apps/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH
//使配置生效
source ~/.bash.profile
//检验是否安装成功
scala -version
//出现以下信息,说明安装成功
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
//解压spark
tar -zxvf spark-2.1.0-bin-2.6.0-cdh5.7.0.tgz -C ../apps
//进入安装目录的bin目录,通过spark-shell可运行spark
//若不熟悉命令,可用以下方式
./spark-shell --help
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
//表示在本地以两个线程启动
./spark-shell --master local[2]
local:默认一个线程
local[n]:n个线程
local[*]:全部线程
Spark编程
这里重新实现在上文实现的wordcount程序,代码如下
sc.textFile("file://root/data/hello.txt").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_ + _).collect
没有看错,只是一行代码。因为Spark封装了很多方便的函数,相比于MapReduce开发更为方便。这也是它成为主流的原因。
Hadoop整合Spring-boot的使用
Spring Hadoop概述
Spring for hadoop提供了统一的配置模式以简化Apache Hadoop的开发,并也易于调用HDFS、Mapreduce、Pig和Hive的API。它还提供了与Spring生态圈的其他项目集成的能力,例如Spring Intergration 和Spring Batch,让你可以优雅地开发大数据的提取/导出和Hadoop工作流项目。
Spring Hadoop开发环境搭建及访问HDFS
第一步加入依赖
1.8
2.6.0-cdh5.7.0
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
org.apache.hadoop
hadoop-client
${hadoop.version}
org.springframework.data
spring-data-hadoop-boot
2.5.0.RELEASE
cloudera
http://repository.cloudera.com/artifactory/cloudera-repos/
在配置文件中配置HDFS地址
spring:
hadoop:
fs-uri: hdfs://192.168.30.130:8092
在代码中访问HDFS
import org.apache.hadoop.fs.FileStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.data.hadoop.fs.FsShell;
import org.springframework.stereotype.Component;
/**
* Spring Boot操作HDFS
* @author zhiying.dong 2019/04/13 16:32
*/
@Component
public class SpringBootHadoopTest implements CommandLineRunner {
//自动注入FsShell,其中封装了HDFS的访问函数
@Autowired
private FsShell fsShell;
@Override
public void run(String... strings) throws Exception {
System.out.println("=========run start============");
//获取根目录下的文件列表
for (FileStatus fileStatus : fsShell.lsr("/")) {
System.out.println(">" + fileStatus.getPath());
}
System.out.println("===========run end===========");
}
}
执行代码后发现没有权限访问HDFS,本人解决的方式为在项目启动时模拟用户,网上有多种解决方式,可自行选择
VM options:
-DHADOOP_USER_NAME=虚拟机用户名
总结
大数据已经涉及到生活的方方面面,所以学习和了解大数据知识是很有必要的。Hadoop生态系统为大数据提供了开源的分布式存储和分布式计算的平台,而这一章只是对其中基础的知识进行了入门,后续还需要深入的学习。