1. 论文相关
ICME 2019
2.摘要
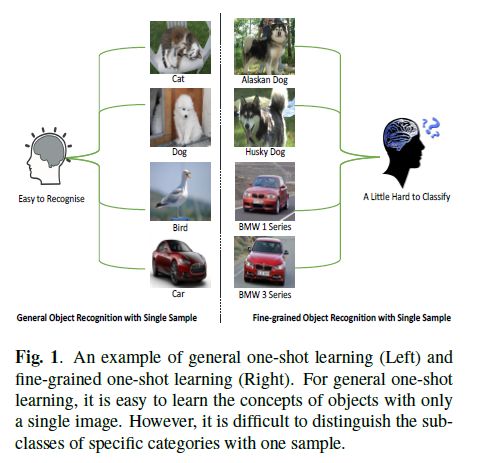
人类的认知能力是在循序渐进的方式。通常,孩子们学会辨别对象从粗到细,具有有限的监督。在这个学习过程的启发下,我们提出了一个简单的然而,对于少量细粒度(fsfg)的有效模型识别,试图解决具有挑战性的细粒度问题使用元学习的识别任务。建议的方法,名为“成对对齐双线性网络”(pabn),是一个端到端深度神经网络。不同于传统的深双线性用于细粒度分类的网络,采用自双线性池捕捉图像的细微特征,该模型使用了一种新的成对双线性池。比较基础图像之间的细微差别并查询图像以学习深度距离度量。整齐为了使基本图像特征与查询图像特征相匹配,我们设计特征对准损失双线性池。四种细粒度分级试验结果数据集和一个通用的少数镜头数据集演示所提出的模型优于-艺术少丸细颗粒和一般少丸方法。
3. 思想
为了克服在[16]中提取特征不发达和[18]中幼稚的自双线性池的不足,我们提出一个新的端到端的FSFG框架,该框架捕获不同类之间的细粒度关系。这个细微差别我们模型的比较能力天生就更智能,而不仅仅是对数据分布进行建模。整个框架如图2所示。更具体地说,基础图像和查询图像以一种成对的方式同时输入PABN,随后由编码器网络生成嵌入式配对特征。然后用双线性池化操作从成对图像中提取细微特征。对于每对,提出的特征对齐损失(feature alignment losses)为保证基础图像特征的位置匹配查询的图像。最后,成对双线性特征通过非线性比较器,将查询图像分类到相应的类别中。
3.2 主要贡献
总之,这项工作的主要贡献如下:
(1)我们提出了一个新的FSFG模型,它模仿人类先进的学习过程。我们提议一种新的成对双线性池化操作捕获基类图像和查询图像之间的细微差别。
(2)为了获得精确的成对双线性特征,我们采用校准损失来调整嵌入特征。
(3)与一般的小样本学习和FSFG方法相比,所提出的方法达到了最先进的性能。
4.方法
4.1 问题定义
给一个细粒度的目标数据集:
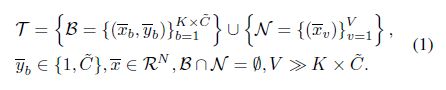
对于FSFG任务,目标数据集包含两部分:有标签的子集B和无标签的子集N。模型需要根据来自B的少量标记数据(其中表示图像,是该图像的标签),对N(表示原始图像)中无标签的数据进行分类。如果目标数据集中的有标签数据包含个不同类别,每个类别有K个带标签图像,则此问题称为C-way-K-shot问题。
为了得到一个能够从目标数据集N中识别无标签图像的完美模型,小样本学习通常使用一个完全注释的数据集,该数据集具有和类似的属性或数据分布,作为辅助数据集:
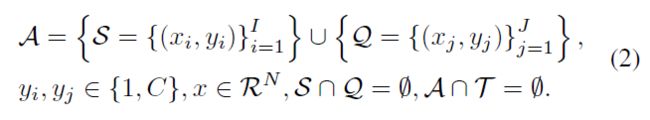
其中和表示图像,和表示图像标签。在每一轮的训练中,辅助数据集A随机分为两部分:支持数据集S和查询数据集Q。设置,可以模拟每次迭代中目标数据集的组成。然后利用A学习元学习器,将知识从A迁移到目标数据。一旦元学习器接受了训练,就可以使用有标签的目标数据集B对其进行微调。最后,元学习器可以将无标签数据集N中的样本分类为相应的类别。这种模拟目标问题的小样本的训练设置在元学习器训练中得到了广泛应用[14,16,18]。
4.2 框架
PABN的整个框架如图2所示。与传统的小样本嵌入结构[14,15,16]不同,我们添加了细粒度图像特征抽取器,如虚线框所示,这是我们的主要贡献。此外,我们修改了非线性比较器[16]并将其应用于我们的细粒度任务。细粒度特征抽取器可以分为两种结构:对齐损失正则化(alignment loss regularization)和成对双线性池化层(pair-wise bilinear pooling layer)。前者旨在匹配嵌入图像特征中相同位置的特征。例如,目标数据集B中的鸟头特征应与Q中的查询鸟头特征匹配。后面的成对双线性池化层旨在从一对基图像(B中的样本)和查询图像(N中的样本)中提取二阶比较特征(second-order comparative features)。
双线性池化层是PABN模型的核心组成部分,它捕获图像对的细微的比较特征,从而决定了基图像和查询图像之间的关系,这对分类器至关重要。然而,如果这对图像不匹配,这对双线性混合特征就不能产生最大的分类性能增益。因此,我们提出了两个特征对齐损失,以保证图像对之间的配准。在下一节中,我们将首先介绍成对双线性池化层,然后介绍具有两个对齐损失的特征对齐正则化。
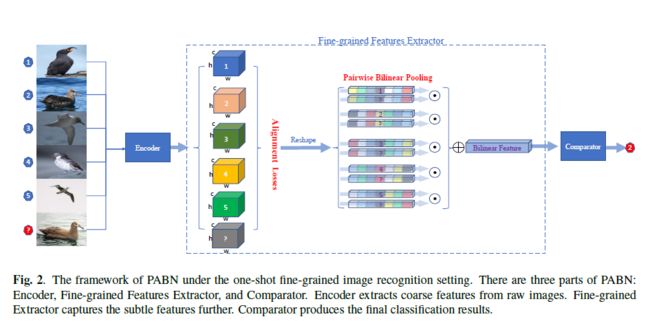
4.3 成对双线性池化层(Pairwise Bilinear Pooling Layer)
最初的双线性CNN图像识别可以定义为四个:
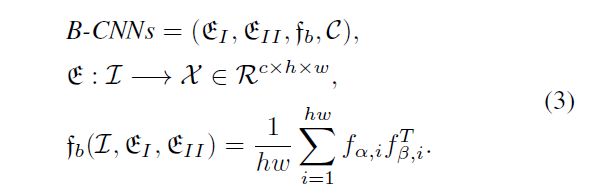
和是两个编码器。是自双线性池化,表示分类器。是一个高度为H、宽度为W和颜色通道为C的图像。通过编码器,将输入图像转换成具有c个特征通道的张量,显示嵌入特征图的高度为h和宽度为c。给定两个特定函数:
用和表示每个特征矩阵和中特定位置的特征向量,。池化特征是一个的向量。是一个自双线性特征与图像标签之间具有交叉熵训练损失的全连接层。
自双线性对来自同一图像的嵌入式特征进行操作。然而,在我们的成对双线性池化中,给定一对图像(例如,)和图像(例如,),编码器,成对双线性池定义为:
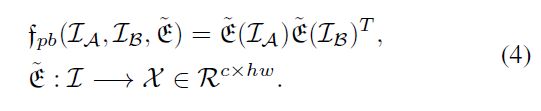
在获得这对双线性向量后,使用sigmoid激活来生成比较对的关系分数。然后将关系分数传递给最终的比较器。
请注意,在我们的成对双线性池化中,我们只有一个共享的嵌入函数。与在同一输入图像上运行的自双线性池化不同,成对双线性池在两个不同的样本上使用矩阵外积。我们的双线性比较器中的训练损失是均方误差(MSE)损失,它将关系分数回归到图像标签相似性,如[16]所述。这样,我们就可以以成对的方式捕获细粒度的二阶比较特征。
4.4 Feature Alignment Loss
在等式3中,自双线性池化在同一图像上运行,这意味着在嵌入特征图的任何位置,操作特征都应对齐。然而,我们提出的成对双线性池化在不同的样本上进行,因此编码的特征可能并不总是匹配的。为了克服这个问题,我们设计了两个特征对齐损失,如下所示:
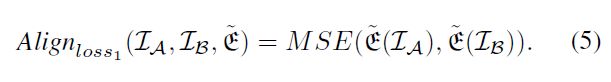
第一个对齐损失是两个嵌入图像描述符的粗略近似,它将两个特征的所有元素的欧几里得距离最小化。
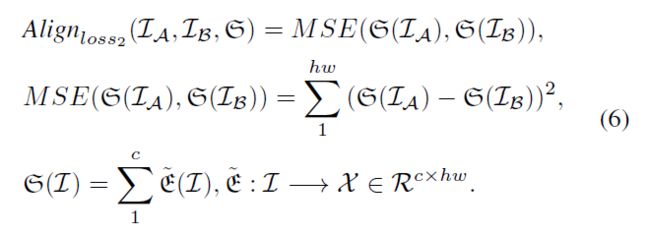
第二个损失是一个更为简洁的特征对齐损失,我们首先对第三个通道上的所有原始特征进行求和,然后如等式6所示测量求和特征的MSE。
通过对提出的对齐损失进行训练,我们鼓励网络自动学习匹配特性,以生成更好的成对双线性特征。
5. 实验
在本节中,我们用四个广泛使用的细粒度数据集和一个通用的小样本数据集上评估了提出的PABN。四个细粒度数据集的类拆分。首先,我们将简要介绍这些数据集。然后详细介绍了实验设置。最后,我们分析了所提出的模型的实验结果,并与其他几种小样本学习方法进行了比较。
5.1 数据集
在我们的实验中,我们使用五个数据集来研究所提出的模型:
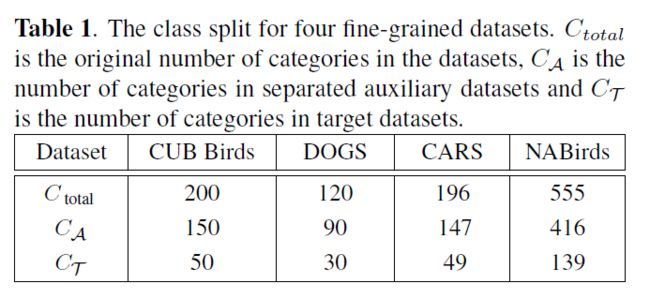
(1)CUB Birds[1]包含200种鸟类,共11788张图片。
(2)DOGS包含120种狗,共20580张图片。
(3)CARS[3]包含196种汽车和总共16185张图片。
(4)NABirds[4]包含555种北美鸟类,共48562张图片。
(5)MiniImageNet[14]包含100类60000张图像。每个类有600个例子。
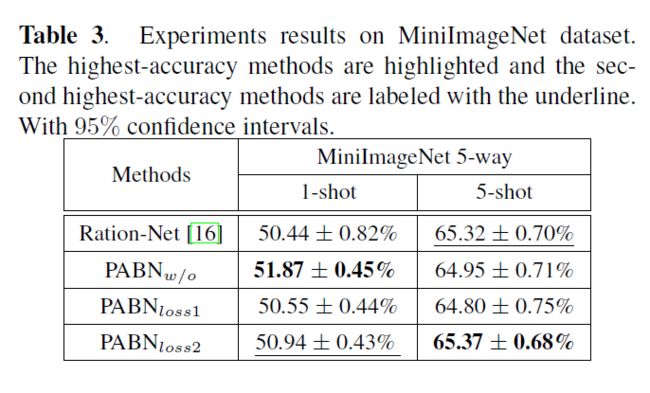
在第2.1节中,我们将这些数据集随机分为两个不相交的(disjoint)子数据集:辅助数据集A和目标数据集T,如表1所示。对于CUB Birds、DOGS和CARS的数据集,我们遵循魏的[18]分割方法。对于MiniImageNet数据集,我们采用论文[16]中的分离方法,分别采用64、16和20个类作为训练集、验证集和测试集。请注意,验证集仅用于监视泛化性。
5.2 实验设置
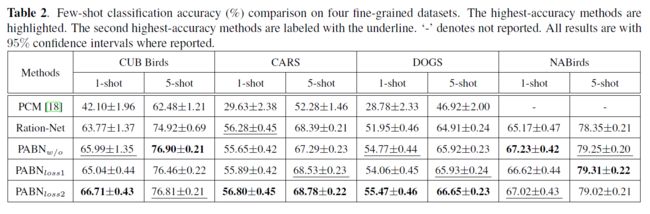
在每一轮的训练和测试中,对于单样本图像识别,每个类中的基本样本数等于1(在B和S中,K=1)。因此,我们使用这些基本样本的嵌入特征作为类的特征()。对于小样本图像识别,我们通过对每个类别中所有嵌入的特征进行求和来提取类的特征。我们比较了提出的PABN模型的四个变量:、和。给出了在嵌入式对上不使用对齐损失的模型。和表示模型在对齐层中的分别采用对齐损失和。在成对双线性池化之后,我们像论文[7]一样对成对双线性特征进行规范化(normalization)操作。
在我们所有的PABN模型和Rational网络中,我们进行5-way-1-shot 和 5-way-5-shot设置。5-way-1-shot 和 5-way-5-shot实验都有15个查询图像,即每小批量5-way-1-shot 和 5-way-5-shot分别有15×5+1×5=80个图像和15×5+5×5=100个图像。我们将所有数据集中的输入图像调整为84×84大小。所有实验均采用Adam optimize优化方法,初始学习率为0.001,所有模型均从头到尾进行训练。我们随机初始化所有网络,不涉及其他数据集。
论文
[1] COMPARE MORE NUANCED: PAIRWISE ALIGNMENT BILINEAR NETWORK
FOR FEW-SHOT FINE-GRAINED LEARNING
参考资料
[1] Cross-modal Hallucination for Few-shot Fine-grained Recognition