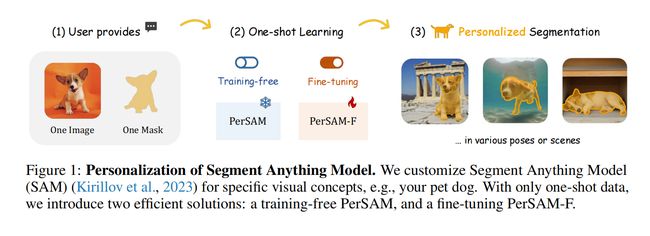
【论文阅读】PERSONALIZE SEGMENT ANYTHING MODEL WITH ONE SHOT
PERSONALIZE SEGMENT ANYTHING MODEL WITH ONE SHOT
- 原文摘要
- 研究背景与问题:
- SAM是一个基于大规模数据预训练的强大提示框架,推动了分割领域的发展。
- 尽管 SAM 具有通用性,但在无需人工提示的情况下,针对特定视觉概念(如自动分割用户宠物狗)的定制化研究尚不充分。
- 方法提出:
- 提出了一种无需训练的 SAM 个性化方法,称为 PerSAM。
- 仅需单次数据(一张带参考掩码的图像),即可在新图像中获取目标概念的正负位置先验。
- 通过目标视觉语义,提出了两种技术增强 SAM 的个性化分割能力:目标引导注意力和目标语义提示。
- 优化与扩展:
- 提出了一个高效的单次微调变体 PerSAM-F(缓解分割尺度的模糊性),通过尺度感知微调来聚合多尺度掩码,仅需调整 2 个参数并在 10 秒内完成,提升性能。
- 冻结 SAM 的整个模型结构,避免大规模训练。
- 实验与评估:
- 构建了一个新数据集 PerSeg,用于评估个性化目标分割。
- 在多个单次图像和视频分割基准上测试了方法的有效性。
- 应用扩展:
- 提出将 PerSAM 用于改进 DreamBooth,提升个性化文本到图像生成的效果。
- DreamBooth 是一种用于个性化文本到图像生成的技术,由 Google Research 在 2022 年提出。它的核心目标是通过少量用户提供的图像(通常只需 3-5 张),训练一个能够生成特定主体(如个人宠物、特定物体或个人肖像)的定制化文本到图像生成模型。
- 通过减少训练集背景的干扰,实现了更好的目标外观生成和更高的文本提示保真度。
- 提出将 PerSAM 用于改进 DreamBooth,提升个性化文本到图像生成的效果。
- 研究背景与问题:

1. 介绍
1.1 研究背景与动机
- 基础模型(如视觉、语言和多模态领域)在大规模数据集和计算资源的支持下取得了显著进展,它们展示了强大的零样本泛化能力和交互性。
- Segment Anything Model (SAM) 提出了一个可提示的分割框架,能够通过手工提示分割任意对象。
- 然而,SAM 缺乏对特定视觉概念(如用户宠物或特定物体)的自动分割能力,需要大量人工干预,效率低下。
1.2 方法提出
- 提出了 PerSAM,一种无需训练的 SAM 个性化方法,仅需单次数据(一张用户提供的参考图像和粗略掩码)。
- 核心步骤:
- 通过特征相似性生成目标对象的位置置信度图----考虑了每一个前景像素的样子
- 根据置信分数,选择正负位置先验点,并将其编码为提示符输入 SAM 的解码器。
- 关键技术----为了释放SAM的特定分割能力,在decoder中用两种方法加入了目标视觉语义:
- 目标引导注意力:通过位置置信度图引导 SAM 解码器中的 token-to-image 交叉注意力层,聚焦于目标区域。
- 目标语义提示:为了清晰地提供高层次的目标语义(指抽象特征或类别、形状等语义信息),将目标对象的嵌入与原始提示符融合,这样能够为低级位置提示(指用户提供的具体位置信息)提供额外的视觉语义信息。
1.3 优化与扩展:
- 提出了 PerSAM-F,一种高效的微调变体,仅需在 10 秒内微调 2 个参数,解决掩码尺度模糊问题。
- 核心设计:
- 冻结 SAM 的预训练参数,保留其通用知识。
- 为了灵活地选择不同的目标的最佳尺寸,作者使用了可学习的相关权重对不同尺度的掩码进行加权求和,自适应选择最佳分割结果。
1.4 改进 DreamBooth:
-
给定包含特定视觉概念的少量图像(例如你的宠物猫或背包),DreamBooth 会学习将这些图像转换为词嵌入空间中的标识符 [V]。然而,这一过程可能会同时包含背景信息(例如楼梯或森林),这会覆盖新提示的背景,并干扰目标外观的生成。因此,我们提出利用 PerSAM 对训练图像中的目标对象进行分割,并仅对 DreamBooth 进行前景区域的监督,从而实现更高质量的文本到图像合成。
- 核心改进:
- 利用 PerSAM 分割训练图像中的目标对象,仅对前景区域进行监督。
- 减少背景干扰,生成更高保真度的目标外观图像。
- 核心改进:
2. 方法
2.1 个性化目标分割
2.1.1 SAM的回顾
-
SAM的三个主要组件
-
Prompt Encoder (EncP):编码用户提供的提示(如点、框或粗略掩码)。
-
Image Encoder (EncI):提取输入图像的特征。
-
Mask Decoder (DecM):基于注意力机制的特征交互,生成最终的分割掩码。
-
-
SAM的工作流程
-
输入:一张图像 I 和一组提示 P(如点、框或粗略掩码)。
-
图像特征提取:通过图像编码器 EncI 提取图像特征 FI。
-
提示编码:通过提示编码器 EncP 将提示 P 编码为提示符 TP 。
-
解码器输入:将可学习的掩码符 TM 与提示符 TP 拼接(前者作为后者的前缀),作为解码器的输入的一部分。
-
掩码生成:通过掩码解码器 DecM 进行特征交互,生成最终的分割掩码 M。
-
公式:
M = D e c M ( F I , Concat ( T M , T P ) ) M = Dec_M\left(F_I, \text{Concat}(T_M, T_P)\right) M=DecM(FI,Concat(TM,TP))
-
-
2.1.2 任务定义
-
尽管 SAM 通过提示能够分割任意对象,但它缺乏自动分割特定目标实例的能力。
-
任务输入与目标:
-
输入:用户提供一张参考图像和一个指示目标视觉概念的掩码(可以是精确分割或粗略草图)。
-
目标:定制化 SAM,使其能够在无需额外人工提示的情况下,在新图像或视频中分割指定目标。
-
-
评估数据集:
-
构建了一个新数据集 PerSeg,用于评估个性化分割任务。
-
数据来源:从主题驱动的扩散模型相关工作中收集的原始图像。
-
数据集特点:包含不同类别、姿态和场景的视觉概念。
-
-
方法提出:
- 针对该任务,提出了两种高效的解决方案,并在后文中详细阐述。
2.2 Training-free PerSAM
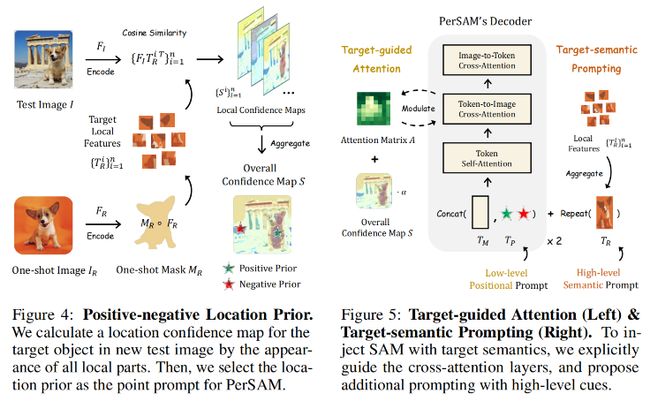
2.2.1 位置置信图
-
位置置信图的生成
- 基于用户提供的参考图像 IR 和掩码 MR ,PerSAM 生成一个置信图,用于指示目标对象在新测试图像 I 中的位置。
-
特征提取
-
使用图像编码器(默认采用 SAM 的图像编码器 EncI )提取参考图像 **IR**和测试图像 I 的视觉特征:
F I = Enc I ( I ) , F R = Enc I ( I R ) F_I = \text{Enc}_I(I), \quad F_R = \text{Enc}_I(I_R) FI=EncI(I),FR=EncI(IR)
- 其中 FI 和 FR 形状都为**(H,W,C)**,C为特征纬度
-
-
前景特征裁剪
-
利用参考掩码 **MR **∈ **Rh×w×1 **裁剪参考图像特征 FR 中的前景像素特征,得到一组局部特征:
{ T R i } i = 1 n = M R ∘ F R \{T_R^i\}_{i=1}^n = M_R \circ F_R {TRi}i=1n=MR∘FR
-
TRi 的形状为(1,C),∘ 表示空间逐元素乘法
- 空间逐元素乘法(Element-wise Multiplication)是一种矩阵或张量运算,其特点是对两个形状相同的矩阵或张量的对应元素进行逐个相乘。在图像处理或深度学习领域,这种操作通常用于对特征图或掩码进行逐像素的调整或过滤
-
-
置信图计算
- 计算每个前景像素特征 T R i T_R^i TRi 与测试图像特征 F I F_I FI 的余弦相似度,生成 n n n个局部置信图:
{ S i } i = 1 n = { F I T R i T } i = 1 n \{S^i\}_{i=1}^n = \{F_I {T_R^i}^T\}_{i=1}^n {Si}i=1n={FITRiT}i=1n
> 其中, S i ∈ R h × w S^i \in \mathbb{R}^{h \times w} Si∈Rh×w, F I F_I FI和 T R i T_R^i TRi 均已进行逐像素 L2 归一化
> S i S^i Si 表示目标对象不同局部部分在测试图像中的分布概率。
-
全局置信图聚合
-
对 n n n 个局部置信图进行平均池化,生成目标对象的全局置信图:
S = 1 n ∑ i = 1 n S i ∈ R h × w S = \frac{1}{n} \sum_{i=1}^n S^i \in \mathbb{R}^{h \times w} S=n1i=1∑nSi∈Rh×w
-
通过考虑每个前景像素的置信度,全局置信图能够综合目标对象不同部分的视觉外观,获得更全面的位置估计
-
2.2.2 Positive- negative Location Prior
-
在测试图像上,选择两个点:
- 正点 Ph:置信值最高的点,表示目标对象最可能的中心位置。
- 负点 Pl :置信值最低的点,表示背景区域。
-
将正点和负点作为正负点提示输入到prompt encoder中,作为 T p T_p Tp
T P = Enc P ( P h , P l ) ∈ R 2 × c T_P = \text{Enc}_P(P_h, P_l) \in \mathbb{R}^{2 \times c} TP=EncP(Ph,Pl)∈R2×c
- SAM 倾向于分割围绕正点 P h P_h Ph 的连续区域,同时丢弃负点 P l P_l Pl 所在的背景区域。
2.2.3 目标引导注意力
-
提出了一种更明确的语义指导方法,用于 SAM 解码器中的交叉注意力操作,以集中在前景目标区域内的特征聚合。
-
整体置信度地图S
- S 用于指示测试图像中目标视觉概念的粗略区域,颜色越热表示得分越高
-
一般的注意力地图
-
注意力地图(Attention Map)是一种在图像处理和计算机视觉中用于表示模型关注区域的可视化工具。它能够显示模型在处理图像时,对不同区域的关注程度或权重分布。具体来说,注意力地图通过颜色强度(如热力图)来指示模型对图像中某些区域的关注程度,颜色越“热”(如红色)表示关注度越高,颜色越“冷”(如蓝色)表示关注度越低。
-
计算
A = softmax ( Q K T / d ) A= \text{softmax}(QK^T/ \sqrt{d}) A=softmax(QKT/d)
- Q 是查询矩阵(Query),通常由提示符 $ T_P$ 生成。
- K 是键矩阵(Key),通常由图像特征 $ F_I$ 生成。
- d 是特征维度。
-
-
PerSAM中的注意力地图的调制
-
利用 S 指导解码器中每个 token-to-image 交叉注意力层的注意力地图。
-
对注意力地图 A ∈ Rh*×w 进行调制,公式为:
A g = softmax ( A + α ⋅ softmax ( S ) ) A^g = \text{softmax}(A + \alpha \cdot \text{softmax}(S)) Ag=softmax(A+α⋅softmax(S))
- 其中, α \alpha α 是平衡因子
-
-
注意力偏置的作用
- 通过注意力偏置,掩码和提示符能够捕捉与目标主题相关的更多视觉语义,而不是不重要的背景区域。
- 这种方法在注意力机制中实现了更有效的特征聚合,从而提高了 PerSAM 在无训练情况下的最终分割精度。
2.2.4 目标语义提示
-
通过利用目标概念的视觉特征作为额外的高层次语义提示,以增强解码器的性能
-
全局嵌入 T R T_R TR 的获取
-
通过平均池化不同局部特征,获得参考图像中目标对象的全局嵌入 $ T_R $
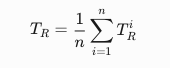
-
-
目标语义的融合
- 将全局嵌入 $ T_R $ 元素级地添加到测试图像的所有输入标记中,然后送入解码器块。
- 通过重复操作和拼接,形成新的输入标记 $ T^g $:
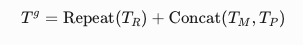
- repeat即可以是 T R T_R TR与后者维度一样,又可以使目标语义出现多次,增强解码器对目标的理解
- $ T^g $是目标语义引导的解码器输入token
2.2.5 Cascaded Post-refinement
- 通过上述技术,用户可从SAM解码器中获得初始mask,但会有粗糙边缘和背景的孤立噪声
- 为此,对初始mask再送回SAM中进行后两步处理
- 第一步,用初始分割掩码和之前的正负位置先验来提示 SAM 解码器
- 第二步,计算出第一步中掩码的边界框,并用这个边界框提示解码器,以实现更精确的目标定位
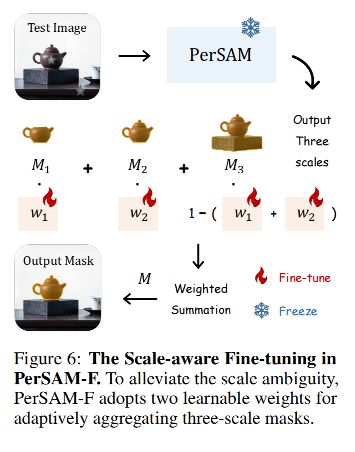
2.3 Fine-Tuning of PerSAM-F
-
分割尺寸的模糊性
- 如上图所示,平台顶部的茶壶由壶盖和壶身两部分组成。如果正先验(用绿星表示)位于壶身,而负先验(用红星表示)并不排除类似颜色的平台,那么 PerSAM 在分割时就会产生歧义
- 而在SAM中会生成三个结果,让用户自己选,这样会消耗额外的人力
-
Scale-aware Fine-tuning
- PerSAM-F 通过 PerSAM 获取位置优先级,并参考 SAM 的原始解决方案,输出三个尺度的掩码,分别记为 M1、M2 和 M3
- 采用两个可学习的权重,通过加权求和计算出最终掩码的输出
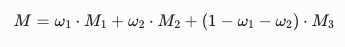
- 初始w1和w2设置为1/3
- 一次性fine-tuning
- 在参考图像上进行一次性 fine-tuning,将给定的掩码作为 ground truth,学习最优权重 ω1 和 ω2。
- 冻结整个 SAM 模型以保留其预训练知识,仅 fine-tune 两个参数 ω1 和 ω2。
2.4 PerSAM优化后的DREAMBOOTH
- 原始DreamBooth
- DreamBooth 通过少量特定对象的图片(如宠物猫)微调预训练的扩散模型,以生成特定对象的图像。
- 它通过文本提示(如 “a [V] cat”)生成目标对象,并在整个重建图像上计算损失。
- 存在的问题
- DreamBooth 在训练过程中会将背景信息注入标识符 [V],导致生成图像时背景信息覆盖新提示的背景,干扰目标外观的生成。
- 改进后的DreamBooth
- 引入 PerSAM 方法,利用目标对象的掩码分割前景目标,并丢弃背景区域的梯度反向传播。
- 通过仅微调目标对象的视觉外观,减少背景干扰,提升生成图像的质量和背景多样性。
3. 实验
3.1 个体化评估
以下是基于图片内容的分点总结:
-
PerSeg 数据集:
-
为了测试个性化分割能力,构建了一个新的分割数据集 PerSeg。
-
数据来源:从主题驱动的扩散模型(如 Ruiz et al., 2022; Gal et al., 2022; Kumari et al., 2022)的训练数据中收集。
-
数据集内容:包含 40 个对象,涵盖日用品、动物和建筑等类别。
-
数据格式:每个对象在不同姿态或场景下包含 5~7 张图像和掩码,固定其中一张图像-掩码对作为用户提供的一次性数据。
-
-
评估指标:
- 采用 mIoU(平均交并比)和 bIoU(边界交并比)进行评估。
3.2 已存在的分割基准
-
视频对象分割:
-
PerSAM 和 PerSAM-F 在没有视频训练的情况下,表现优于其他方法(如 Painter 和 SegGPT)。
-
在复杂场景中,PerSAM-F 甚至优于一些完全基于视频数据训练的方法(如 Lin et al., 2019; Liang et al., 2020)。
-
结果表明,PerSAM 和 PerSAM-F 在时间序列数据和复杂场景中具有强大的泛化能力。
-
-
一次性语义及部分分割:
-
在四个数据集(FSSS-1000、LVIS-92、PASCAL-Part 和 PACO-Part)上的评估显示,PerSAM-F 优于 Painter,与 SegGPT 表现相当。
-
对于某些领域内训练的方法(如 Min et al., 2021; Hong et al., 2022),PerSAM-F 也能取得更高的分数。
-
实验证明,PerSAM-F 不仅适用于对象级别的分割,还可用于类别和部分个性化分割。
-
3.3 优化后的DreamBooth

3.4 消融实验
-
主要组件分析:
-
基线:仅采用正点位置先验(positive location prior)作为基础。
-
负点提示:增加负点提示(negative point prompt),提升 mIoU 3.6%。
-
级联后处理:引入级联后处理(cascaded post-refinement),进一步提升 mIoU 11.4%。
-
目标语义提示:将高层次目标语义引入 SAM 解码器,用于注意力引导和语义提示,分别提升 mIoU 1.9% 和 3.5%。
-
尺度感知微调:通过高效的尺度感知微调(scale-aware fine-tuning),PerSAM-F 进一步提升 mIoU 6.0%,展示了卓越的准确性。
-
-
不同微调方法比较:
-
比较了多种参数高效微调(PEFT)方法,包括提示微调(prompt tuning)、Adapter 和 LoRA。
-
提示微调和 Adapter:容易过拟合一次性数据,严重降低准确性。
-
尺度感知微调:在 PerSAM-F 中表现最佳,同时微调最少的可学习参数。
-
-
使用框作为参考:
-
放宽输入限制,允许使用边界框(bounding box)作为参考,而非精确掩码。
-
对 PerSAM 和 PerSAM-F 的性能影响较小,但对其他方法影响较大。
-