经过了3个月的开发,MXNet 0.11版本终于发布了,其中也发布了最为重要的一个更新,动态图接口Gluon,李沐大神也在CVPR17上面介绍了Gluon接口,足以看出MXNet对这次新发布的Gluon接口的重视。
下面我就以一个PyTorch使用者的角度为大家介绍一个我对Gluon这个接口的看法。
为何要开发Gluon
很多人说MXNet将战线拉得太大了,发布了两年,api处于极速的更新状态,非常不稳定。这一点我赞同,我认为一个成熟的框架必须要具有非常稳定的api,试想几个月前写的代码现在想做一些修改,结果发现好多api不能用了,这无疑会让人非常崩溃。而且我认为目前MXNet的api也存在一些问题,有很多可以改进的空间,但是我认为最为重要的问题是没有规范的教程和文档,同时官方没有建立讨论的社区,大家有问题就去github上提issue,这样效率是非常底下的,这也给很多想使用MXNet的用户造成了极大的困难。
既然说到了MXNet的这么多可以改进的问题,当然dmlc他们自己肯定是意识到了,但是因为精力和时间的关系没有很快去改进,反而他们将他们的重心放到了开发一个全新的动态图接口Gluon上。对于这个工作量并不小的工程,我想他们肯定是经过了深思熟虑才做出的解决,下面我就谈一谈我个人的感受。
先放上一张沐神在CVPR17 tutorial上的一张图片吧。
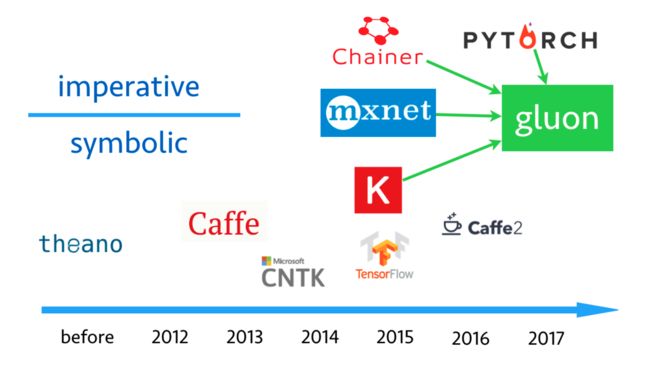
图片上不仅从时间上,还从编程方式上将目前主流的框架做了一下区分,可以明显看出2015年之前框架都是符号式编程,tensorflow继承theano的特点出现,因为Google的背书,强力地吸引了很多人去使用,很快成为了最流行的框架。但是tensorflow真的很好用吗?就我自己的使用情况而言,答案是否定的,一是因为tensorflow是由一群Google的工程师开发的,他们一方面希望工程能力很强,有希望tensorflow可以做科研,这样必定顾此失彼;二是因为tensorflow是符号式编程方式,继承了theano一大堆缺点,不仅写法麻烦,而且bug难调;三是暂时只能用于静态图,现在很多深度学习的研究希望能够使用动态图。上面是我自己使用时感觉的问题,知乎上专门有一个问题来吐槽tensorflow,有兴趣的读者可以去看看。虽然说了这么多tensorflow的不好,但是毫无疑问tensorflow仍然是深度学习框架的霸者地位。
我一直认为越新的东西就会越满足用户的需求,所以随后Facebook新出的PyTorch的用户体验就感觉非常的好,一是因为其是命令式编程的方式,随时能够运行结果,跟我们写python程序几乎一模一样,不用像tensorflow一样要先定义graph,然后一个session去运行;二是因为bug非常好找,那里出了问题就能够直接定位;三是因为文档非常清楚,干净整洁,同时源码非常清晰,容易看懂和修改;四是因为其支持动态图,非常灵活,能够随意取出其中的tensor进行操作和查看;五是因为其有非常非常清晰的教程和官方论坛,Soumith等主要开发者都会经常在论坛上面解答问题,而且一般遇到了问题去论坛上搜都能够很容易搜到之前有人提过,所有能够很方便地找到解答方法。
正是由于这些优点,使得PyTorch才刚刚发布半年的时间就被大量的人推崇和使用,最新的cs231n都推出了PyTorch版本的作业,可想而知PyTorch是多么简单易用。
说了这么多tensorflow和PyTorch,这跟Gluon有什么关系呢?我想MXNet正是看到了以PyTorch为首的命令式编程框架的潜力,对于新用户特别友好,易于上手,所以他们决定模仿PyTorch开发一个动态图接口Gluon。Gluon还邀请了CMU的两位教授来联手写教程,也是一本书,我想也是因为他们发现PyTorch良好的教程对于吸引用户实在是太有帮助了。但是目前还是没有官方的社区和论坛,希望MXNet的开发者能够看到这个问题,拥有一个官方的论坛能够留住很多使用者。
其实PyTorch也是仿照Chainer开发的,其后端也是调用的torch的运算,定位比keras低,但是又比tensorflow高。所以Gluon也可以看作这样一个接口,调用底层的MXNet,但是前端使用符号式编程的方式。
Gluon的定位
PyTorch定位于科研,在Facebook内部使用Caffe2作为产品的部署和应用,那么Gluon是如何定位的呢?
官方称Gluon不仅定位于科研,同时也可用于产品。这无疑比PyTorch更好,因为这样不需要再重写代码,而且两个框架之间转化也容易丢掉一些细节,从而模型达不到之前的精度,能够有一套统一的框架,不仅能做科研,同时能够用于产品部署无疑是最好的解决方案。我相信以dmlc的实力肯定能做出了,毕竟MXNet的设计理念是非常领先的。
Gluon的优势
大致看完Gluon的api,和PyTorch非常非常像,开发者也说了Gluon学习了Keras,Chainer和PyTorch的优点并加以改进,相似的api无疑是一个优势。之前我是PyTorch使用者,这两天我尝试着将之前的PyTorch教程移植到Gluon下面,发现非常方便,几乎大体的框架都不用改动,只需要该一些小的api就可以了,所以非常方便用户迁移过来,这是我的PyTorch教程和移植的Gluon教程。
第二个优势是MXNet的优势,就是速度快,省显存,并行效率高,分布式简单等等。这些优势并不是Gluon带来的,而是MXNet一直以来的优势。
第三个优势就是静态图和动态图的转换,PyTorch只有动态图的模式,有的时候我们的网络结构其实是一个静态图,但是通过PyTorch每次都会重新构建动态图,而Gluon提供了一个静态图和动态图之间切换的方式。Gluon中的模块gluon.nn.Sequential和gluon.Block分别与PyTorch中的torch.nn.Sequential和torch.nn.Module对应,他们都是动态图的构建,而Gluon中还提供了gluon.nn.hybridSequential和gluon.HybridBlock,这两个模块就可以在动态图和静态图之间转换,使用者可以先用imperatvie的方式写网络,debug,最后跑通网络之后,如果网络是一个静态图结构,就可以用net.hybridize()的方式将其转换成静态图,众所周知静态图的运算会比动态图快,所以这是Gluon比PyTorch更好的地方,具体可以看看这个教程。
第四个优势就是前面提到过的,科研和工业界可以都用同一个框架开发,避免的代码的重写,减少劳动效率,避免出现问题。
Gluon与PyTorch的对比
Gluon和PyTorch非常相似,比如PyTorch中的torch.Tensor()可以对应Gluon中的mx.nd.array(),PyTorch中tensor.cuda()可以对应Gluon中ndarray.as_in_context(mx.gpu())等等,大家在使用中就会慢慢发现很多相似的地方,我就不一一列举了。除了这些相似之处,还有一些不同的地方具体说一下。
首先,Gluon和PyTorch在网络定义的部分有一个不同点,PyTorch定义网络的时候必须要明确的网络输入和输出的维度,所以我们需要自己去算,或者让网络向前传播一次print出维度。而Gluon并不需要这样做,其能够根据网络定义自动去判断维度,避免了我们自己运算的麻烦,可以说是变得更加方便了。
由此带来了另外一点的不同,就是lazy loading。定义好网络之后其实里面的权重并没有真实存在,这和PyTorch不同,PyTorch定义好网络之后就能够将每一层的权重print出来,而Gluon定义好网络之后是没有办法print出来的。但是想像PyTorch一样print出具体的权重数值也可以做到,就是定义一个输入,然后feed进网络做一次前向传播,这样网络中的参数就真实存在了,可以print出里面的具体数值了。这就是lazy loading,在使用的时候才会去真正地赋值,而不是定义的时候就赋值,究其原因,还是因为Gluon希望在定义的时候能够尽量方便,不需要人为去推断输入的维度,这带来的问题就是需要网络前向传播一次才能够真正赋予网络中的参数。这和PyTorch对比到底哪个更好了,这就见仁见智了。
最后一点不同之处就是PyTorch在网络定义的时候就会默认初始化,而且初始化的api并没有暴露出来,如果你想要自己重新初始化就需要手动提取出里面的tensor进行赋值。而Gluon有点像tensorflow,需要在定义网络之后进行一次参数的初始化,net.collect_params().initialize(ctx=mx.gpu()),而且PyTorch中可以使用model.cuda()将网络放到GPU上,而Gluon需要在初始化中指明ctx=mx.gpu()或者ctx=mx.cpu()。同时Gluon还可以在网络定义的时候就定义当前层的初始化方式,比如gluon.nn.Dense(weight_initializer=mx.init.Normal()),我感觉这比PyTorch方便一些。
Gluon的不足
最后说一说Gluon的不足吧,毕竟Gluon是刚刚上线的产品,所以难免存在一些bug,api偏少,线上部署不成熟,同时ndarray存在一些奇怪的问题,比如a = mx.nd.array([2, 3, 4]),我想取最后一位,a[-1]就会报错,但是我用a[2]就没有问题,虽然说影响不是很大,但是感觉用着有点烦。另外ndarray的操作也没有PyTorch中tensor多,比如squeeze这个操作我就没有在ndarray中找到类似,也许是我没有发现,知道的同学可以告诉我一下。
总结
说了这么多,最后总结一下,Gluon的出现是现在深度学习框架发展的趋势,目前刚刚上线,虽然不成熟,但是提供了一套从科研到工业的简单的、统一的框架。对于使用PyTorch的用户比较友好,迁移成本比较低,同时还能够保证性能,如果是使用tensorflow等框架的用户,也强烈建议感受一下imperative框架的魅力。
最后,希望dmlc的开发者们能够好好去更新和维护Gluon,如果真的能够将科研和工业界统一起来,那么一定会有很多人来使用Gluon的。
欢迎查看我的知乎专栏,深度炼丹
欢迎访问我的博客