目录
- 背景
- 一、 对 oplog 的影响
- oplog 原理
- 二、主备倒换
- 小结
声明:本文同步发表于 MongoDB 中文社区,传送门:
http://www.mongoing.com/archives/26201
背景
在生产环境的部署中,由于各种不确定因素的存在(比如机器掉电、网络延迟等),各节点上的系统时间很可能会出现不一致的情况。
对于MongoDB来说,时间不一致会对数据库的运行带来一些不可预估的风险,比如主从复制、定时调度都或多或少依赖于时间的取值及判断。
因此,在MongoDB集群中保持节点间的时间同步是一项重要的任务,这通常会使用一些NTP协调服务来实现。
通过人工执行的时间设定操作,或是NTP同步触发的校准,都会使当前的系统时间发生变化,这称之为时间跳变。
时间跳变对于正在运作的流程是存在影响的,尤其是副本集的复制、心跳机制。
接下来,将针对这些影响做一些分析。
一、 对 oplog 的影响
oplog 原理
oplog 是主从数据复制的纽带,主节点负责将写入数据变更记录写入到 oplog 集合,备节点则负责从oplog 中拉取增量的记录进行回放。
一个 典型的 oplog如下所示:
{
"ts" : Timestamp(1560861342, 2),
"t" : NumberLong(12),
"h" : NumberLong("7983167552279045735"),
"v" : 2,
"op" : "d",
"ns" : "app.T_AppInfo",
"o" : {
"_id" : ObjectId("5d08da9ebe3cb8c01ea48a25")
}
}
字段说明
| 字段名 | 字段描述 |
|---|---|
| ts | 记录时间 |
| h | 记录的全局唯一标识 |
| v | 版本信息 |
| op | 操作类型(增删改查等) |
| ns | 操作的集合 |
| o | 操作内容 |
| o2 | 待更新的文档,仅 update 操作包含 |
关于 oplog 的结构可以参考这篇文章
其中,ts字段 实现日志拉取的关键,这个字段保证了 oplog是节点有序的,它的构成如下:
- 当前的系统时间,即UNIX时间至现在的秒数,32位
- 整数计时器,不同时间值会将计数器进行重置,32位
ts字段属于Bson的Timestamp类型,这种类型一般在 MongoDB内部使用。
既然 oplog 保证了节点有序,备节点便可以通过轮询的方式进行拉取,我们通过 db.currentOp()命令可以看到具体的实现:
db.currentOp({"ns" : "local.oplog.rs"})
>
{
"desc" : "conn611866",
"client" : "192.168.138.77:51842",
"clientMetadata" : {
"driver" : {
"name" : "NetworkInterfaceASIO-RS",
"version" : "3.4.10"
}
},
"active" : true,
"opid" : 20648187,
"secs_running" : 0,
"microsecs_running" : NumberLong(519601),
"op" : "getmore",
"ns" : "local.oplog.rs",
"query" : {
"getMore" : NumberLong("16712800432"),
"collection" : "oplog.rs",
"maxTimeMS" : NumberLong(5000),
"term" : NumberLong(2),
"lastKnownCommittedOpTime" : {
"ts" : Timestamp(1560842637, 2),
"t" : NumberLong(2)
}
},
"originatingCommand" : {
"find" : "oplog.rs",
"filter" : {
"ts" : {
"$gte" : Timestamp(1560406790, 2)
}
},
"tailable" : true,
"oplogReplay" : true,
"awaitData" : true,
"maxTimeMS" : NumberLong(60000),
"term" : NumberLong(2),
"readConcern" : {
"afterOpTime" : {
"ts" : Timestamp(1560406790, 2),
"t" : NumberLong(1)
}
}
},
"planSummary" : "COLLSCAN",
}
可见,副本集的备节点是通过 ts字段不断进行增量拉取,来达到同步的目的。
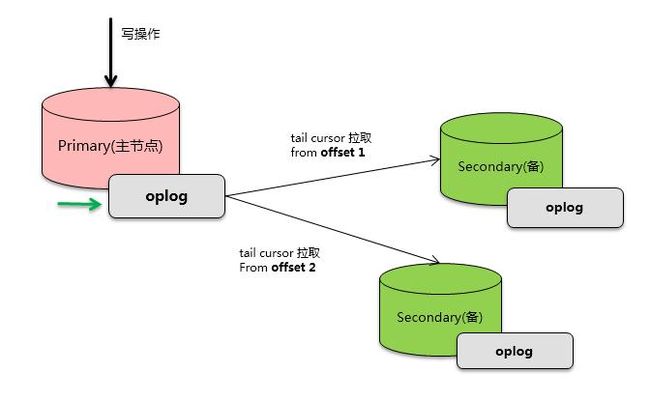
图-oplog 拉取
接下来,看一下oplog与系统时间的对应关系,先通过mongo shell 写入一条数据,查看生成的oplog
shard0:PRIMARY> db.test.insert({"justForTest": true})
shard0:PRIMARY> db.getSiblingDB("local").oplog.rs.find({ns: "test.test"}).sort({$natural: -1}).limit(1).pretty()
{
"ts" : Timestamp(1560842490, 2),
"t" : NumberLong(2),
"h" : NumberLong("-1966048951433407860"),
"v" : 2,
"op" : "i",
"ns" : "test.test",
"o" : {
"_id" : ObjectId("5d088723b0a0777f7326df57"),
"justForTest" : true
}
}此时的 ts=Timestamp(1560842490, 2),将它转换为可读的时间格式:
shard0:PRIMARY> new Date(1560842490*1000)
ISODate("2019-06-18T07:21:30Z")同时,我们查看系统当前的时间,可以确定 oplog的时间戳与系统时间一致。
# date '+%Y-%m-%d %H:%M:%S'
2019-06-18 07:21:26接下来,测试时间跳变对于oplog的影响
由于 oplog 是主节点产生的,下面的测试都基于主节点进行
A. 时间向后跳变
在主节点上将时间往后调整到 9:00,如下:
# date -s 09:00:00
Tue Jun 18 09:00:00 UTC 2019写入一条测试数据,检查oplog的时间戳:
shard0:PRIMARY> db.test.insert({"justForTest": true})
shard0:PRIMARY> db.getSiblingDB("local").oplog.rs.find({ns: "test.test"}).sort({$natural: -1}).limit(1).pretty()
{
"ts" : Timestamp(1560848723, 1),
"t" : NumberLong(4),
"h" : NumberLong("-6994951573635880200"),
"v" : 2,
"op" : "i",
"ns" : "test.test",
"o" : {
"_id" : ObjectId("5d08a953b9963dbc8476d6b7"),
"justForTest" : true
}
}
shard0:PRIMARY> new Date(1560848723*1000)
ISODate("2019-06-18T09:05:23Z")可以发现,随着系统时间往后调整之后,oplog的时间戳也发生了同样的变化。
B. 时间向前跳变
继续这个测试,这次在主节点上将时间往前调整到 7:00,如下:
host-192-168-138-148:~ # date -s 07:00:00
Tue Jun 18 07:00:00 UTC 2019写入一条测试数据,检查oplog的时间戳:
shard0:PRIMARY> db.test.insert({"justForTest": true})
shard0:PRIMARY> db.getSiblingDB("local").oplog.rs.find({ns: "test.test"}).sort({$natural: -1}).limit(1).pretty()
{
"ts" : Timestamp(1560848864, 92),
"t" : NumberLong(4),
"h" : NumberLong("3290816976088149103"),
"v" : 2,
"op" : "i",
"ns" : "test.test",
"o" : {
"_id" : ObjectId("5d088c1eb9963dbc8476d6b8"),
"justForTest" : true
}
}
shard0:PRIMARY> new Date(1560848864*1000)
ISODate("2019-06-18T09:07:44Z")问题出现了,当时间向前跳变的时候,新产生的oplog时间戳并没有如预期一样和系统时间保持一致,而是停留在了时间跳变前的时刻!
这是为什么呢?
我们在前面提到过,oplog需要保证节点有序性,这分别是通过Unix时间戳(秒)和计数器来保证的。
因此,当系统时间值突然变小,就必须将当前时刻冻结住,通过计数器(Term)自增来保证顺序。
这样就解释了oplog时间戳停顿的问题,然而,新问题又来了:
计数器是有上限的,如果时间向前跳变太多,或者是一直向前跳变,导致计数器溢出怎么办呢?
从保证有序的角度上看,这是不被允许的,也就是当计数器(Term)溢出后将再也无法保证有序了。
从MongoDB 3.4的源码中,可以看到对应的实现如下:
global_timestamp.cpp
//获取下一个时间戳
Timestamp getNextGlobalTimestamp(unsigned count) {
//系统时间值
const unsigned now = durationCount(
getGlobalServiceContext()->getFastClockSource()->now().toDurationSinceEpoch());
...
// 对当前上下文的Timestamp 自增计数
auto first = globalTimestamp.fetchAndAdd(count);
auto currentTimestamp = first + count; // What we just set it to.
unsigned globalSecs = Timestamp(currentTimestamp).getSecs();
// 若上下文时间大于系统时间,且同一时刻的计数器 超过2^31-1(2147483647)时,进行报错
if (MONGO_unlikely(globalSecs > now) && Timestamp(currentTimestamp).getInc() >= 1U << 31) {
mongo::severe() << "clock skew detected, prev: " << globalSecs << " now: " << now;
fassertFailed(17449);
} 从代码上看,计数器在超过21亿后会发生溢出,该时间窗口的计算参考如下:
假设数据库吞吐量是1W/s,不考虑数据均衡等其他因素的影响,每秒钟将需要产生1W次oplog,那么窗口值为:
(math.pow(2,31)-1)/10000/3600 = 59h
也就是说,我们得保证系统时间能在59个小时内追赶上最后一条oplog的时间。
二、主备倒换
在副本集的高可用架构中,提供了一种自动Failover机制,如下:
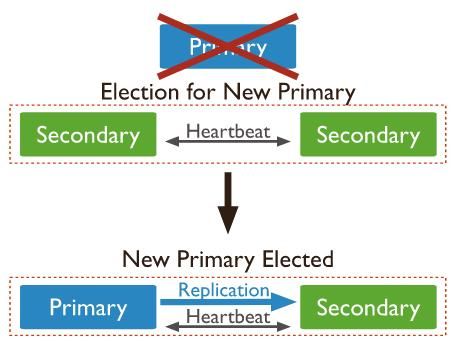
图-Failover
简单说就是节点之间通过心跳感知彼此的存在,一旦是备节点感知不到主节点,就会重新选举。
在实现上,备节点会以一定间隔(大约2s)向其他节点发送心跳,同时会启动一个选举定时器,这个定时器是实现故障转移的关键:
- 选举定时器的预设时间被设为10s(实际值为10-12s之间),
- 在定时器时间到达时会触发一个回调函数,这个函数中备节点会主动发起选举,并接管主节点的角色。
- 每次向主节点心跳成功后都会取消选举定时器的执行,并重新发起新的选举定时器
因此,在正常情况下主节点一直是可用的,选举定时器回调会被一次次的取消,而只有在异常的情况下,备节点才会主动进行"夺权",进而发生主备切换。
那么,接着上面的问题,系统时间的跳变是否会影响这个机制呢?我们来做一下测试:
自动Failover的逻辑由备节点主导,因此下面的测试都基于备节点进行
A. 时间向前跳变
我们在备节点上将时间调前一个小时,如下:
# date
Tue Jun 18 09:00:12 UTC 2019
# date -s 08:00:00
Tue Jun 18 08:00:00 UTC 2019然后通过db.isMaster()检查主备的关系:
shard0:SECONDARY> db.isMaster()
{
"hosts" : [
"192.168.138.77:30071",
"192.168.138.148:30071",
"192.168.138.55:30071"
],
"setName" : "shard0",
"setVersion" : 1,
"ismaster" : false,
"secondary" : true,
"primary" : "192.168.138.148:30071",
"me" : "192.168.138.55:30071",
...
"readOnly" : false,
"ok" : 1
}
=== 没有发生变化,仍然是备节点
shard0:SECONDARY>结果是在时间往前调整后,主备关系并没有发生变化,从日志上也没有发现任何异常。
B. 时间向后跳变
接下来,在这个备节点上将时间往后调一个小时,如下:
# date
Tue Jun 18 08:02:45 UTC 2019
# date -s 09:00:00
Tue Jun 18 09:00:00 UTC 2019
这时候进行检查则发现了变化,当前的备节点成为了主节点!
shard0:SECONDARY> db.isMaster()
{
"hosts" : [
"192.168.138.77:30071",
"192.168.138.148:30071",
"192.168.138.55:30071"
],
"setName" : "shard0",
"setVersion" : 1,
"ismaster" : true,
"secondary" : false,
"primary" : "192.168.138.55:30071",
"me" : "192.168.138.55:30071",
"electionId" : ObjectId("7fffffff0000000000000008"),
...
"readOnly" : false,
"ok" : 1
}
=== 发生变化,切换为主节点
shard0:PRIMARY>在数据库日志中,同样发现了发起选举的行为,如下:
I REPL [ReplicationExecutor] Starting an election, since we've seen no PRIMARY in the past 10000ms
I REPL [ReplicationExecutor] conducting a dry run election to see if we could be elected
I REPL [ReplicationExecutor] VoteRequester(term 7 dry run) received a yes vote from 192.168.138.77:30071; response message: { term: 7, voteGranted: true, reason: "", ok: 1.0 }
I REPL [ReplicationExecutor] dry election run succeeded, running for election
I REPL [ReplicationExecutor] VoteRequester(term 8) received a yes vote from 192.168.138.77:30071; response message: { term: 8, voteGranted: true, reason: "", ok: 1.0 }
I REPL [ReplicationExecutor] election succeeded, assuming primary role in term 8
I REPL [ReplicationExecutor] transition to PRIMARY
I REPL [ReplicationExecutor] Entering primary catch-up mode.
I REPL [ReplicationExecutor] Caught up to the latest optime known via heartbeats after becoming primary.
I REPL [ReplicationExecutor] Exited primary catch-up mode.
I REPL [rsBackgroundSync] Replication producer stopped after oplog fetcher finished returning a batch from our sync source. Abandoning this batch of oplog entries and re-evaluating our sync source.
I REPL [SyncSourceFeedback] SyncSourceFeedback error sending update to 192.168.138.148:30071: InvalidSyncSource: Sync source was cleared. Was 192.168.138.148:30071
I REPL [rsSync] transition to primary complete; database writes are now permitted
I REPL [ReplicationExecutor] Member 192.168.138.148:30071 is now in state SECONDARY确实,在备节点的系统时间往后跳变时,发生了主备切换!
那么问题出在哪里? 是不是只要是时间往后调整就一定会切换呢?
下面,我们尝试从3.4的源代码中寻求答案:
选举定时器是由 ReplicationCoordinatorImpl这个类实现的,看下面这个方法:
代码位置:db/repl/replication_coordinator_impl_heartbeat.cpp***
void ReplicationCoordinatorImpl::_cancelAndRescheduleElectionTimeout_inlock() {
//如果上一个定时器回调存在,则直接取消
if (_handleElectionTimeoutCbh.isValid()) {
_replExecutor.cancel(_handleElectionTimeoutCbh);
..
}
...
//触发调度,when时间点为 now + electionTimeout + randomOffset
//到了时间就执行_startElectSelfIfEligibleV1函数,发起选举
_handleElectionTimeoutCbh =
_scheduleWorkAt(when,
stdx::bind(&ReplicationCoordinatorImpl::_startElectSelfIfEligibleV1,this,
StartElectionV1Reason::kElectionTimeout));
}ReplicationExecutor::_scheduleWorkAt 是定时器调度的入口,负责将定时器回调任务写入队列,如下:
代码位置:db/repl/replication_executor.cpp
StatusWith ReplicationExecutor::scheduleWorkAt(
Date_t when, const CallbackFn& work) {
stdx::lock_guard lk(_mutex);
WorkQueue temp;
StatusWith cbHandle = enqueueWork_inlock(&temp, work);
...
WorkQueue::iterator insertBefore = _sleepersQueue.begin();
//根据调度时间找到插入位置
while (insertBefore != _sleepersQueue.end() && insertBefore->readyDate <= when)
++insertBefore;
//将任务置入_sleepersQueue队列
_sleepersQueue.splice(insertBefore, temp, temp.begin());
...
return cbHandle;
}
对于队列任务的处理是在主线程实现的,通过getWork方法循环获取任务后执行:
//运行线程 -- 持续获取队列任务
void ReplicationExecutor::run() {
...
//循环获取任务执行
while ((work = getWork()).first.callback.isValid()) {
//发起任务..
}
}
//获取可用的任务
ReplicationExecutor::getWork() {
stdx::unique_lock lk(_mutex);
while (true) {
//取当前时间
const Date_t now = _networkInterface->now();
//将_sleepersQueue队列中到时间的任务置入_readyQueue队列(唤醒)
Date_t nextWakeupDate = scheduleReadySleepers_inlock(now);
//存在任务执行,跳出循环
if (!_readyQueue.empty()) {
break;
} else if (_inShutdown) {
return std::make_pair(WorkItem(), CallbackHandle());
}
lk.unlock();
//没有合适的任务,继续等待
if (nextWakeupDate == Date_t::max()) {
_networkInterface->waitForWork();
} else {
_networkInterface->waitForWorkUntil(nextWakeupDate);
}
lk.lock();
}
//返回待执行任务
const WorkItem work = *_readyQueue.begin();
return std::make_pair(work, cbHandle);
}
//将到时间的任务唤醒,写入_readyQueue队列
Date_t ReplicationExecutor::scheduleReadySleepers_inlock(const Date_t now) {
WorkQueue::iterator iter = _sleepersQueue.begin();
//从头部开始,找到最后一个调度时间小于等于当前时间(需要执行)的任务
while ((iter != _sleepersQueue.end()) && (iter->readyDate <= now)) {
auto callback = ReplicationExecutor::_getCallbackFromHandle(iter->callback);
callback->_isSleeper = false;
++iter;
}
//转移队列
_readyQueue.splice(_readyQueue.end(), _sleepersQueue, _sleepersQueue.begin(), iter);
if (iter == _sleepersQueue.end()) {
// indicate no sleeper to wait for
return Date_t::max();
}
return iter->readyDate;
}
从上面的代码中,可以看到 scheduleReadySleepers_inlock 方法是关于任务执行时机判断的关键,在它的实现逻辑中,会根据任务调度时间与当前时间(now)的比对来决定是否执行。
关于当前时间(now)的获取则来自于AsyncTimerFactoryASIO的一个方法,当中则是利用 asio库的system_timer获取了系统时钟。
至此,我们基本可以确定了这个情况:
由于系统时间向后跳变,会导致定时器的调度出现误判,其中选举定时器被提前执行了!
更合理的一个实现应该是采用硬件时钟的周期而不是系统时间。
那么,剩下的一个问题是,系统时间是不是一旦向后跳就会出现切换呢?
根据前面的分析,每次心跳成功后都会启用这个选举定时器,触发的时间被设定在10-12s之后,而心跳的间隔是2s,
于是我们可以估算如下:
如果系统时间往后跳的步长能控制在 8s以内则是安全的,而一旦超过12s则一定会触发切换。
下面是针对步长测试的一组结果:
//往后切2s
date -s `date -d "2 second" +"%H:%M:%S"`
>> 结果:主备不切换
//往后切5s
date -s `date -d "5 second" +"%H:%M:%S"`
>> 结果:主备不切换
//往后切7s
date -s `date -d "7 second" +"%H:%M:%S"`
>> 结果:主备不切换
//往后切10s
date -s `date -d "10 second" +"%H:%M:%S"`
>> 结果:主备偶尔切换
//往后切13s
date -s `date -d "13 second" +"%H:%M:%S"`
>> 结果:主备切换
//往后切20s
date -s `date -d "20 second" +"%H:%M:%S"`
>> 结果:主备切换
小结
经过上面的一些测试和分析,我们知道了时间跳变对于副本集确实会造成一些问题:
- 对于oplog复制的影响,时间向前跳变会导致出现"计时器堆积",如果未及时处理,将导致溢出从而引发错误;
- 对于自动Failover的影响,时间向后跳变则会造成干扰,很可能导致主备切换及业务的抖动。
尤其是第二点,MongoDB 3.4及以下版本都会存在该问题,而3.6/4.0 版本经验证已经解决。
那么,为了最大限度降低影响,提供几点建议:
- 分布式集群中务必采用可靠的NTP服务保证各节点上的时间同步,对于时间同步做好告警检测并保证能及时解决异常;
- 重大的时间校准,采用小步长(比如1分钟内3-5s)的方式逐步渐渐达到最终同步,这样可以避免主备切换产生的业务影响。
- 升级到3.6/4.0 或更新的版本来规避时间跳变导致选举的问题。