转:https://segmentfault.com/a/1190000011164489
一、MySQL 锁概述
MySQL 两种锁特性归纳 :
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率最低,并发度也最高。
MySQL 不同的存储引擎支持不同的锁机制。
myisam 和 memory 存储引擎采用的是 表级锁;
innodb 存储引擎既支持行级锁,也支持表级锁,但默认情况下采用行级锁。
表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如 web 应用;
而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用。
二、 myisam 表锁
1. 查询表级锁争用情况
可以通过检查 table_locks_waited 和 table_locks_immediate 状态变量来分析系统上的表锁定争夺:
MySQL [sakila]> show status like 'table_locks%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Table_locks_immediate | 100 |
| Table_locks_waited | 0 |
+-----------------------+-------+
如果 table_locks_waited 的值比较高,则说明存在着较严重的表级锁争用情况。
2. MySQL 表级锁的锁模式
MySQL 的表级锁有两种模式,表共享读锁(table read lock)和表独占写锁(table write lock)。
对 myisam 表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;对 myisam 表的写操作,则会阻塞其他用户对同一表的读和写操作;myisam 表的读操作和写操作之间,以及写操作之间时串行的。
当一个线程获得对一个表的写锁户,只有持有锁的线程可以对表进行更新操作,其他线程的读、写操作都会等待,直到锁被释放。
3. 加锁
myisam 在执行查询语句(select)前,会自动给涉及的所有表加读锁,在执行更新操作(update、delete、insert等)前,会自动给涉及的表加写锁,这个过程并不需要直接用 lock table 命令给 myisam 表显示加锁。给 myisam 表显式加锁,一般是为了在一定程度模拟事务操作
myisam 在自动加锁的情况下,总是一次获得 sql 语句所需要的全部锁,所以显示锁表的时候,必须同时取得所有涉及表的锁,这也正是 myisam 表不会出现死锁(deadlock)的原因。
注意:在使用 lock tables 时,不仅需要一次锁定用到的所有表,而且,同一个表在 sql 语句中出现多少次,就要通过与 sql 语句中相同的别名锁定多少次,否则会报错。
4. 并发插入(concurrent inserts)
myisam 表的读和写是串行的,但这是就总体而言的。在一定条件下,myisam 表也支持查询和插入操作的并发进行。
myisam 存储引擎有一个系统变量 concurrent_insert , 专门用以控制其并发插入的行为,其值分别可以为0,1,2。
- 当 concurrent_insert 设置为 0 时,不允许并发插入。
- 当 concurrent_insert 设置为 1 时,如果 myisam 表中没有空洞(即表的中间没有被删除的行),myisam 允许在一个进程读表的同时,另一个进程从表尾插入记录。这也是 MySQL 的默认设置。
- 当 concurrent_insert 设置为 2 时,无论 myisam 表中有没有空洞,都允许在表尾并发插入记录。
5. myisam 的锁调度
myisam 存储引擎的读锁和写锁是互斥的,读写操作时串行的。当一个进程请求某个 myisam 表的读锁,同时另一个进程也请求同一表的写锁时,写进程会先获得锁。不仅如此,即使读请求先到锁等待队列,写请求后到,写锁也会插到读锁请求之前,这是因为 mysql 认为写请求一般比读请求重要。这也正是myisam 表不太适合有大量更新操作和查询操作应用的原因,因为,大量的更新操作会造成查询操作很难获得读锁,从而可能永远阻塞。
通过一些参数设置可以调节 MySQL 的默认调度行为:
- 通过指定启动参数 low-priority-updates, 使 myisam 引擎默认给予读请求以优先的权利。
- 通过执行命令 set low_priority_updates = 1, 使该连接发出的更新请求优先级降低。
- 通过指定 insert、update、delete 语句的 low_priority 属性,降低该语句的优先级。
上述方式都是要么更新优先,要么查询优先,MySQL 也提供了一种折中的办法调节读写冲突:
给系统参数 max_write_lock_count 设置一个合适的值,当一个表的读锁达到这个值后,MySQL 就暂时将写请求的优先级降低,给读进程一定获得锁的机会。
三、 InnoDB 锁
innodb 与 myisam 的最大不同有两点,一是支持事务(transaction),二十采用了行级锁。
1. 并发事务处理存在的问题
相对于串行处理来说,并发事务处理能力大大增加数据库资源的利用率,提高数据库系统事务吞吐量,从而可以支持更多的用户,但并发事务处理也会带来一些问题:
更新丢失(lost update)
当两个或多个事务选择同一行,然后基于最初选定的值更新该行时,由于每个事务都不知道其他事务的存在,就会发生丢失更新问题,最后的更新覆盖了由其他事务所做的更新。
脏读(dirty reads)
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此作进一步的处理,就会产生未提交的数据依赖关系。
不可重复读(non-repeatable reads)
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变或某些记录已经被删除了!这种现象就是“不可重复读”。
幻读(phantom reads)
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象称为“幻读”。
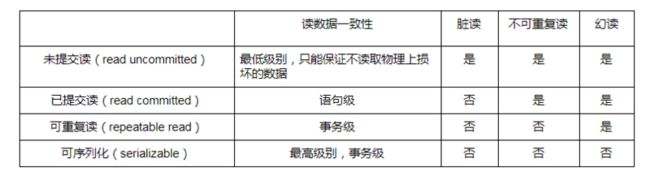
2. 事务隔离级别
并发事务处理带来的问题中,“更新丢失”,通常是可以避免的,需要应用程序对要更新的数据加必要的锁来解决。
“脏读”,“不可重复读”和“幻读”, 其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。
数据库实现事务隔离的方式,基本可以分为两种:
- 在读取数据前,对其加锁,阻止其他事务对数据进行修改
- 不加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照,这种方式叫做数据多版本并发控制。
数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。为了解决“隔离”与“并发”的矛盾,ISO/ANSI SQL92 定义了 4 个事务隔离级别,MySQL 实现了这四种级别,应用可以根据自己的业务逻辑要求,选择合适的隔离级别来平衡“隔离”与“并发”的矛盾。
3. 查看 Innodb 行锁争用情况
可以通过检查 innodb_row_lock 状态变量来分析系统上的行锁的争夺情况:
MySQL [sakila]> show status like 'innodb_row_lock%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 0 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 0 |
| Innodb_row_lock_waits | 0 |
+-------------------------------+-------+
5 rows in set (0.00 sec)
如果发现锁争用比较严重,如 Innodb_row_lock_waits 和 Innodb_row_lock_time_avg 的值比较高,可以通过查询 information_schema 数据库中相关的表来查看锁情况,或者通过设置 innodb monitors 来进一步观察。
(1)查询 information_schema 数据库中的表了解锁等待
MySQL [sakila]> use information_schema
Database changed
MySQL [information_schema]> select * from innodb_locks \G;
(2) 通过设置 innodb monitors 观察锁冲突情况
MySQL [sakila]> create table innodb_monitor (a int) engine=innodb;
Query OK, 0 rows affected (0.05 sec)
show engine innodb status \G;
4. innodb 的行锁模式及加锁方法
Innodb 实现了两种类型的行锁:
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务获取相同数据集的共享读锁和排他写锁。
另外,为了允许行锁和表锁共存,事项多粒度锁机制,innodb 还有两种内部使用的意向锁,这两种意向锁都是表锁:
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排它锁(IX): 事务打算给数据行加行排它锁,事务在给一个数据行加排它锁前必须先取得该表的 IX 锁。

如果一个事务请求的锁模式与当前的锁兼容,innodb 就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
意向锁是 innodb 自动加的,不需要用户干预。对于 update、delete 和 insert 语句,innodb 会自动给涉及数据集加排它锁(X);对于普通 select 语句,innodb 不会加任何锁。
事务可以通过以下语句显式给记录集加共享锁或排它锁。
- 共享锁(S):select * from table_name where ... lock in share mode.
- 排它锁(X): select * from table_name where ... for update.
用 select... in share mode 获得共享锁,主要用在需要数据依存关系时来确认某行记录是否存在,并确保没有人对这个记录进行 update 或者 delete 操作。但是如果当前事务也需要对该记录进行更新操作,则有可能造成死锁,对于锁定行记录后需要进行更新操作的应用,应该使用 select... for update 方式获得排他锁。
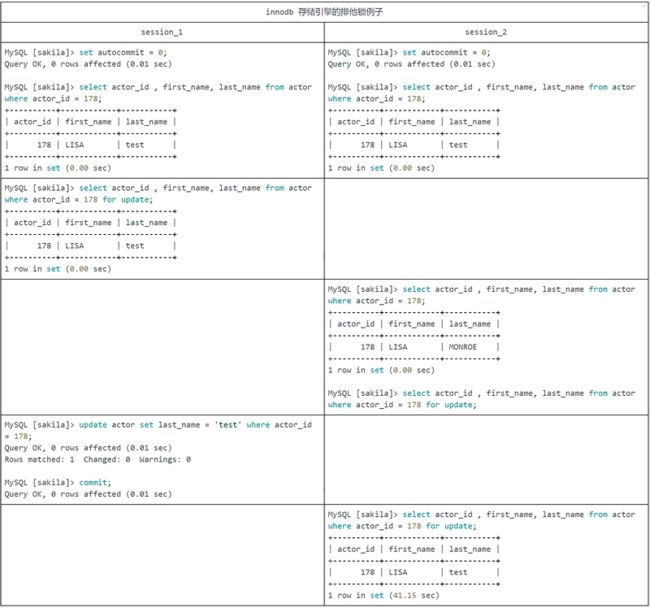
innodb 存储引擎共享锁例子(更新时死锁)

innodb 存储引擎排它锁例子
5. innodb 行锁实现方式
innodb 行锁是通过给索引项加锁来实现的,如果么有索引,innodb 将通过隐藏的聚簇索引来对记录加锁。innodb 行锁分为 3 种情形:
- record lock: 对索引项加锁
- gap lock: 对索引项之间的“间隙”、第一条记录前的“间隙”或最后一条记录的“间隙”加锁。
- next-key lock: 前两种的结合,对记录及其前面的间隙加锁。
innodb 这种行锁实现特点意味着:如果不通过索引条件检索数据,那么 innodb 将对表中的所有记录加锁,实际效果和表锁一样!
在实际应用中,要特别注意 innodb 行锁的这一特性,否则可能导致大量的锁冲突,从而影响并发性能。
(1) 在不通过索引条件查询时,innodb 会锁定表中的所有记录。
创建测试表:
MySQL [sakila]> create table tab_no_index (id int, name varchar(10)) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
MySQL [sakila]> insert into tab_no_index values (1,'1'),(2,'2'),(3,'3'),(4,'4');
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0

看起来 session_1 只给一行加了排他锁,但 session_2 在请求其他行的排他锁时,却出现了锁等待!原因就是在没有索引的情况下,Innodb 会对所有记录都加锁。当给其增加一个索引后,innodb 就只锁定了符合条件的行
创建测试表:
MySQL [sakila]> create table tab_with_index (id int , name varchar(10)) engine = innodb;
Query OK, 0 rows affected (0.01 sec)
MySQL [sakila]> alter table tab_with_index add index id(id);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
MySQL [sakila]> insert into tab_with_index values (1,'1'),(2,'2'),(3,'3'),(4,'4');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0

(2) 由于 MySQL 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。
创建测试表,id字段有索引,name字段没有索引:
MySQL [sakila]> create table tab_with_index (id int , name varchar(10)) engine = innodb;
Query OK, 0 rows affected (0.01 sec)
MySQL [sakila]> alter table tab_with_index add index id(id);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
MySQL [sakila]> insert into tab_with_index values (1,'1'),(1,'4');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0

(3) 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,不论是使用主键索引、唯一索引或普通索引,innodb 都会使用行锁对数据加锁。
创建测试表,id 字段和 name 字段都有索引:
MySQL [sakila]> create table tab_with_index (id int , name varchar(10),index id (id),index name (name)) engine = innodb;
Query OK, 0 rows affected (0.00 sec)
MySQL [sakila]> insert into tab_with_index values (1,'1'),(1,'4'),(2,'2');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0

(4) 即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 innodb 也会对所有记录加锁。因此,在分析锁冲突时,别忘了检查 sql 的执行计划,以确认是否真正使用了索引。
6. next-key 锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,innodb 会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(gap)”,innodb 也会对这个“间隙”加锁,这种锁机制就是所谓的 next-key 锁。
举例来说,假如 emp 表中只有 101 条记录,其 id 的值分别是1、2、...、100、101,下面的 sql:
# 这是一个范围条件的检索,innodb 不仅会对符合条件的 id 值为 101 的记录加锁,也会对 id 大于 101(这些记录并不存在)的“间隙”加锁。
select * from emp where id > 100 for update;
为什么使用 next-key 锁
innodb 使用 next-key 锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了 id 大于 100 的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另一方面,是为了满足其恢复和复制的需要。
在使用范围条件检索并锁定记录时,innodb 这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际开发中,尤其是并发插入比较多的应用,应该尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
innodb 除了通过范围条件加锁时使用 next-key 锁外,如果使用相等条件请求给一个不存在的记录加锁,innodb 也会使用 next-key 锁!
7. 恢复和复制的需要,对 innodb 锁机制的影响
MySQL 通过 binlog 记录执行成功的 insert、update 、delete 等更新数据的 sql 语句,并由此实现 MySQL 数据库的恢复和主从复制。
MySQL 5.6 支持 3 种 日志格式,即基于语句的日志格式 sbl,基于行的日志格式 rbl 和混合格式。它还支持 4 种复制模式:
- 基于 sql 语句的复制 sbr:这也是 MySQL 最早支持的复制模式。
- 基于 行数据的复制 rbr: 这是 MySQL5.1 以后喀什支持的复制模式,主要优点是支持对非安全 sql 的复制模式。
- 混合复制模式:对安全的 sql 语句采用基于 sql 语句的复制模式,对于非安全的 sql 语句采用局于行的复制模式。
- 使用全局事务id(gtids)的复制:主要是解决主从自动同步一致的问题。
对基于语句日志格式(sbl)的恢复和复制而言,由于 MySQL 的 binlog 是按照事务提交的先后顺序记录的,因此要正确恢复或复制数据,就必须满足:
在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录,也就是不允许出现幻读。这已经超过了“可重复读”隔离级别的要求,实际上是要求事务要串行化。这也是许多情况下,innodb 要用 next-key 锁的原因。
8. 什么时候使用表锁
对于 innodb 表,在绝大部分情况下都应该使用行级锁,因为事务和行锁往往是我们选择 innodb 表的理由,但在个别特殊任务中,也可以考虑使用表级锁:
- 事务需要更新大部分或全部数据,表又比较大,如果使用默认的行锁,不仅这个事务执行效率低,而且可能造成其他事务长时间锁等待和锁冲突,这种情况下可以考虑使用表锁
- 事务涉及多个表,比较复杂,很可能引起死锁,造成大量事务回滚。这种情况也可以考虑一次性锁定多个表,从而避免死锁,减少数据库因事务回滚带来的开销。
当然,应用中这两种事务不能太多,否则,就应该考虑使用 myisam 表了。
在 innodb 下,使用表锁要注意以下两点:
- 使用 lock tables 虽然可以给 innodb 加表级锁,但必须说明的是,表锁不是由 innodb 存储引擎管理的,而是由其上一层———— MySQL server 负责的,
仅当 autocommit=0、innodb_table_locks=1(默认设置)时,innodb 层才知道 MySQL 加的表锁,MySQL server 也才能够感知 innodb 加的行锁,这种情况下,innodb 才能自动识别涉及到的锁。 - 在用 lock_tables 对 innodb 表加锁时要注意,要将 autocommit 设为 0,否则 MySQL 不会给表加锁;事务结束前,不要用 unlock tables 释放表锁,因为 unlock tables 会隐含的提交事务;commit 或 rollback 并不能释放用 lock tables 加的表锁,必须用 unlock tables 释放表锁
set autocommit = 0;
lock tables ti write, t2 read, ...;
[do something with tables t1 and t2 here];
commit;
unlock tables;
9. 关于死锁
myisam 表锁是 deadlock free 的,这是因为 myisam 总是一次获取所需的全部锁,要么全部满足,要么等待,因此不会出现死锁。但在 innodb 中,除单个 sql 组成的事务外,锁是逐步获得的,这就决定了在 innodb 中发生死锁是可能的。

上面的例子中,两个事务都需要获得对方持有的排他锁才能继续完成事务,这种循环锁等待就是典型的死锁。
发生死锁后,innodb 一般都能自动检测到,并使一个事务释放锁回退,另一个事务获得锁,继续完成事务。但在涉及外部锁或表锁的情况下,innodb 并不能完全自动检测到死锁,只需要通过设置锁等待超时参数 innodb_lock_wait_timeout 来解决。需要说明的是,这个参数并不是只用来解决死锁问题,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重的性能问题,甚至拖垮数据库。
通常来说,死锁都是应用设计的问题,通过调整业务流程,数据库对象设计、事务大小、以及访问数据库的 sql 语句,绝大部分死锁都可以避免。
几种避免死锁的方法:
(1) 在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
下面的例子中,由于两个 session 访问两个表的顺序不同,发生死锁的机会就非常高!但如果以相同的顺序来访问,死锁就可以避免。

如果 session_2 以相同的顺序执行 sql 语句,会造成锁等待,但不会死锁。
(2) 在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。

(3) 在事务中,如果要更新记录,应该申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
(4) 在 repeatable-read 隔离级别下,如果两个线程同时对相同条件记录用 select ... for update 加排他锁,在没有符合该条件记录情况下,两个线程过会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成 read committed ,就可避免问题。
(5) 当隔离级别为 read committed 时,如果两个线程都先执行 select ... for update, 判断是否存在符合条件的记录,如果没有,就插入记录。此时,只有一个线程能插入成功,另一个线程会出现锁等待,当第 1 个线程提交后,第 2 个线程会因主键重出错,但虽然这个线程出错了,却会获得一个排他锁,如果有第 3 个线程又来申请排他锁,也会出现死锁。对于这种情况,可以直接做插入操作,然后再捕获主键重异常,或者在遇到主键重错误时,总是执行 rollback 释放获得的排他锁
尽管通过上面介绍的设计和 sql 优化等措施,可以大大减少死锁,但死锁很难完全避免。因此,在程序设计中总是捕获并处理死锁异常是一个很好的编程习惯
如果出现死锁,可以用 show innodb status 命令来确定最后一个死锁产生的原因。返回结果中包括死锁相关事务的详细信息,如引发死锁的 sql 语句,事务已经获得的锁,正在等待什么锁,以及被回滚的事务等。可以据此分析产生死锁的原因。