lvs的核心就是调度器,所有客户端请求的数据都需要经过调度器进行转发,如果单一的调度器出现故障,整个集群系统将全部崩溃。所以需要使用keepalived来实现集群的高可用、高负载。
keepalived实现高可用集群的核心是VRRP协议。
VRRP协议:虚拟路由冗余协议。在keepalived正常工作时,主master会不断的通过多播方式向备节点Backup发送心跳信息,用以告诉备节点自己还活着,仍然在提供服务。当主节点故障时,无法发送信息,备节点收不到来自主节点的心跳信息,认为主节点故障,将根据优先级调用自身的接管程序接管主Master的IP资源及服务,当主节点恢复时,备节点又会释放自己接管的IP资源及服务,恢复到原来的备用角色。
VRRP选举机制:优先级越大,选举几率越高。/etc/keepalived/keepalived.conf配置priority参数。
测试环境如下:
keepalived主机: 192.168.6.142
keepalived备机: 192.168.6.152
http服务器1: 192.168.6.147
http服务器2: 192.168.6.151
VIP : 192.168.6.148两台http服务器的安装
1、 两台机均安装httpd
# yum install -y httpd2、 添加首页
Realserver1设置
# echo “RS1” >/var/www/html/index.html
Realserver2设置
# echo “RS2” >/var/www/html/index.html3、 启动并设置开机启动httpd
# service httpd start两台keepalived主机的设置
1、 两台机均安装keepalived
安装依赖文件与keepalive
# yum install -y openssl openssl-devel keepalived2、 keepalived主机配置
# vim /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER #指定该节点为主节点,备用节点设置为BACKUP(必须)
interface eth1 #绑定虚拟IP的网络接口 (必须)
virtual_router_id 51 #VRRP组名,两个节点设置一样,以指明同属一VRRP组
priority 101 #主节点的优先级,数值在1~254,注意从节点必须比主节点的优先级别低(必须)
advert_int 1 #组播信息发送间隔,两个节点需一致
authentication{
auth_type PASS
auth_pass 1111
} #设置验证信息,两个节点需一致
virtual_ipaddress{
192.168.6.148/24 dev eth1 label eth1:0
} #指定虚拟IP,两个节点需设置一样(必须),别名可设可不设,不设置别名不会显示
}
#虚拟IP服务
virtual_server 192.168.6.148 80 {
delay_loop 6 #设定检查间隔
lb_algo rr #指定LVS算法(必须)
lb_kind DR #指定LVS模式(必须)
nat_mask 255.255.255.0 (必须)
persistence_timeout 50 #持久连接设置,会话保持时间
protocol TCP #转发协议为TCP
#后端实际TCP服务配置
real_server 192.168.6.147 80 {
weight 1
# HTTP监测,RS上下线
HTTP_GET {
url {
path /
status_code 200
}
connet_timeout 2
nb_get_retry 3
delay_before_retry 1
}
}
real_server 192.168.6.151 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connet_timeout 2
nb_get_retry 3
delay_before_retry 1
}
}
}3、 keepalived备机的keepalived.conf的配置,不同之处如下:
state BACKUP
priority 100
#其它配置跟keepalived主机相同/etc/keepalived/keepalived.conf为keepalived的主配置文件。以上配置state
表示主节点为192.168.6.142,副节点为192.168.6.152。虚拟为
IP192.168.6.148。后端的真实服务器为192.168.6.147和192.168.6.151,当通过192.168.6.148访问web服务器时,自动转到后端真实服务器,后端节点的权重相同,类似轮询的模式。
keepalived的启动与测试
1、 启动keepalived
# service keepalived start2、 查看keepalived主机的IP
# ipconfig测试结果
1、 测试前查看keepalived主机和备机的IP,eth1:0无任何配置信息
2、 主备机均启动keepalived后,eth1:0配置在主机Master上。当主机上的Keepalived服务down后,eth1:0漂移到备机Backup上。
3、查看节点信息,手动down掉RS1的httpd服务,再看节点信息
# ipvsadm -L -n以上测试结果说明,当keepalived备机在keepalived主机宕机的情况会自动接管了资源。但待keepalived主机恢复正常的时候,主机会重新接管资源。
问题思考
1、外部浏览器无法访问192.168.6.148内容
此故障原因可能是lvs模式选择的DR模式,但是并未配置RS的lo:0口及未添加route2、所有RS服务器均Down后,如何处理
配置文件keepalived.conf中的real_server 项配置后面添加一配置项 sorry_server 127.0.0.1 80 同时启动主备机的httpd服务,添加index提示页面。如“Under test....”等等3、自写监测脚本,完成维护模式切换。
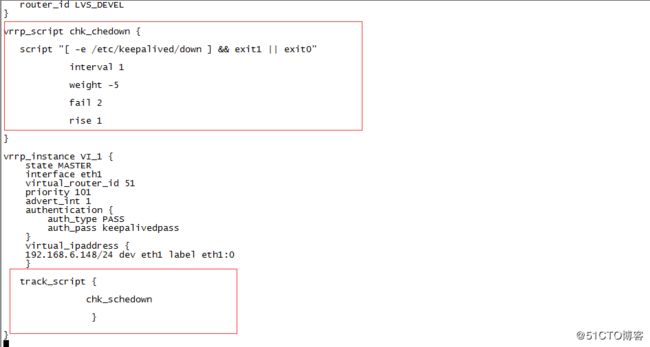
该脚本主要是编辑配置文件keepalived.conf通过权重weight来控制主备的切换。
4、前端vip地址192.168.6.148发生漂移时,怎样通知管理员。
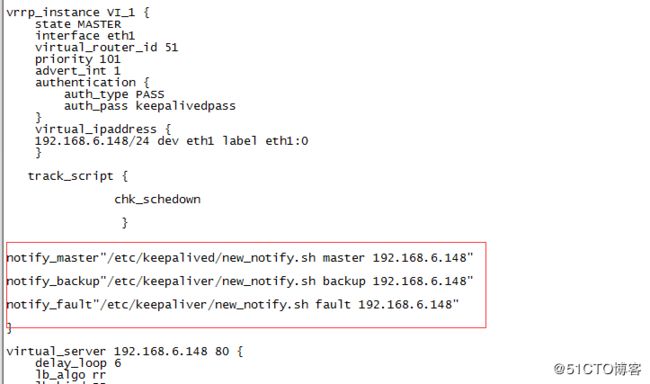
# vim new_notify.sh
#!/bin/bash
contact='root@localhost'
Usage() {
echo "Usage:`basename $0` {master|backup|fault} VIP"
}
notify() {
subject="`hostname`'s state changed to $1"
mailbody="`date`:`hostname`'s state change to $1,$VIP floating."
echo $mailbody | mail -s "$subject" $contact
}
[ $# -lt 2 ] && Usage && exit
VIP=$2
case $1 in
master)
notify master
;;
backup)
notify backp
;;
fault)
notify fault
;;
*)
Usage
exit1
;;
esac切换主备机查看邮件
# mail5.脑裂
高可用系统架构中,当连接主备节点的心跳线故障时,本来正常提供服务的两个节点就成为相互的个体。由于相互失去联系,均以为对方出现故障。两个节点像脑裂人一样争夺资源,最终导致共享资源被瓜分,或者两边服务都起不来或者同时读写共享存储,导致数据被损坏。
防止脑裂的方式:
1.两个节点间添加冗余的心跳线,即双心跳线。
2.当相互收不到信息时,强行关闭其中一个节点。比如,备节点接收不到心跳消患,通过单独的线路发送关机命令关闭主节点的电源。此功能需要特殊设备的支持,比如Stonith
3.设置仲裁机制。当两个节点相互不通时,可以参考ping一下网关,ping不通网关的一方主动放弃竞争。
4.节点数最好为奇数。