背景
- 项目组缺乏完善的监控告警系统,无法保证服务稳定性
- 开发人员相对紧缺,大部分工作时间只能跟进产品需求,缺少对非功能性指标的关注,也没有精力和经验开发监控告警系统
- 目前云服务的监控功能和各种开源工具非常丰富,可以组合利用作为解决方案快捷实施
监控告警系统的设计原则
- 全面性。
每一个环节的异常都可能对整个线上系统的运行产生威胁。所以监控告警需要全方位覆盖到系统链路上的每一个环节,如:
- 最底层的云主机、数据库、消息队列等中间件的运行指标
- 网关的QPS/RT/http status的实时统计
- 链路上所有服务的可用性
- 业务系统异常日志
- 在线活跃用户数、支付订单TPS等关键业务数据
- 实时性。
一方面是数据采集监控的实时性,这个无论是云厂商的方案还是各种开源系统都可以解决。另一方面是告警的实时性,告警需要实时甚至提前将消息通知到位,方便开发/运维人员提前介入,避免系统不可用导致用户使用受到影响后才发现问题,降低故障持续时间,保证系统高可用性。
- 精确性。
每天底层服务和业务系统产生海量数据,缺少告警肯定无法保证系统稳定性,但如果告警过多,告警也失去了关键问题的提醒意义,所以要对海量告警进行过滤、去重、合并,做到不误告警,不漏告警,不多告警。告警主要功能需要包括:
- 过滤:对某些可预知的告警进行过滤,不进入告警统计的数据,如少量爬虫访问导致的http响应500错误,业务系统自定义异常信息等。
- 去重:当一个告警通知负责人后,在这个告警恢复之前,不会继续收到相同的告警。
- 抑制:为了减少由于系统抖动带来的干扰,还需要实现抑制,例如服务器瞬间高负载,可能是正常的,只有持续一段时间的高负载才需要得到重视。
- 恢复:开发/运维人员不仅需要收到告警通知,还需要收到告警恢复正常通知。
- 合并:对同一时刻产生的多条相同告警进行合并,如某个微服务集群同一时刻出现多个子服务负载过高的告警,需要合并成为一条告警。
- 相关性收敛:有时某个告警产生时,往往会伴随着其它告警。这时可以只对根本原因产生告警,其它告警收敛为子告警一并发送通知。如云服务器出现CPU负载告警时往往伴随其搭载的所有系统的可用性告警。
- 易用性。
作为业务系统的支撑,监控告警系统自身需要保持高可用性,无需开发/运维过多关注和维护。目前云厂商方案更容易做到这点。同时要具备良好的可扩展性,新系统能够快捷无侵入式地接入告警,新的告警类型也可以快速配置。
阿里云监控告警配置参考
基于以上几个原则,同时考虑到维护成本和部署成本,Java项目可以考虑采用阿里云提供的功能(主要包括云监控、负载均衡和日志服务)作为监控告警服务的系统支撑,以及Cat(美团点评开源系统)作为Java Springboot微服务的监控告警。
阿里云自带监控告警服务的优势:
- 无需自建系统,节省开发和维护成本;
- 对系统各链路都可以部署监控;
- 数据实时采集,且指标数据非常全面;
- 可用性高,可以放心依赖监控和告警处理问题;
- 配置简单易用,新系统可以快速接入,扩展性强。
精确性要求的功能方面:
- 沉默通道时间配置,可以实现同一种告警去重功能和合并功能;
- 指标持续时间和分级阈值配置,可以实现抑制干扰告警的功能;
- 指标恢复正常后会自动发送恢复通知;
- 对于过滤功能,需要在日志告警中自定义配置(下面会给出实例);
缺点:
- 部分中间件的监控告警没有统一的管理配置入口,需要单独配置告警接收者;
- 对于相关性收敛,没有还没有直接可用的配置,可能会存在同时受到多条相关性告警的情况。
下面以阿里云为例,列出常用的关键指标监控告警配置:
云主机基础监控告警
可以首先在云监控>应用分组中创建告警联系人组、告警模板,方便对监控告警资源进行统一管理

入口:配置云监控>主机监控:
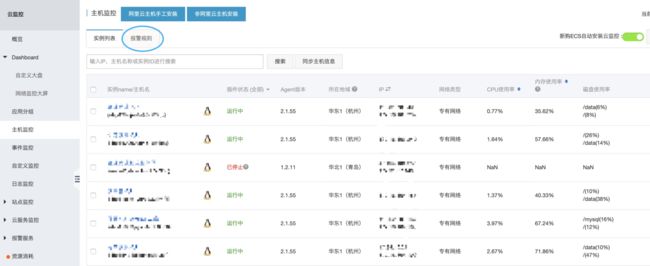
配置云主机指标告警规则,主要关注CPU使用率,内存使用率,磁盘使用率:

可用性监控告警
入口:云监控>站点监控,各系统需要开发健康检查接口用于可用性检测:

MYSQL基础指标监控告警
入口:云监控>云服务监控>云数据库RDS版

配置Mysql指标告警规则:

主要关注CPU使用率、内存使用率、磁盘使用率、连接数使用率、IOPS使用率,如果有主从架构的话需要加入从库同步延迟监控
Redis基础指标监控告警
入口:云监控>云服务监控>云数据库Redis版
和mysql类似,主要关注连接数使用率和内存使用率
消息队列基础指标监控告警
以消息队列RocketMQ为例,可以配置消息堆积量阈值和消费延迟阈值告警

网关基础指标监控告警
入口:云监控>云服务监控>负载均衡
可选的指标比较多,可以选取关键指标进行告警,如7层协议QPS、RT、http 5xx status数据等。如果需要过滤无效url等可预见的请求,可以在日志服务中配置告警过滤规则,如:

Mysql慢查询告警
慢查询sql往往是系统性能和可用性的首要威胁,能够实时了解慢查询情况是监控系统的刚需。但是目前阿里云RDS只有查看功能,没有告警功能,这里只能通过在业务系统层面监控上报数据实现监控告警。
如果业务系统开发基于Java框架,可以使用druid连接池实现慢查询数据采集和上报:
- 引入阿里云日志服务相关jar包
com.google.protobuf
protobuf-java
2.5.0
com.aliyun.openservices
aliyun-log-logback-appender
0.1.13
ch.qos.logback
logback-core
1.2.3
参考来源:https://github.com/aliyun/aliyun-log-logback-appender/blob/master/README_CN.md
- druid相关配置
springboot配置中加入
spring.datasource.druid.filter.stat.enabled=true
spring.datasource.druid.filter.stat.log-slow-sql=true
# 单位毫秒 超过该时间则记录
spring.datasource.druid.filter.stat.slow-sql-millis=1000
# 合并参数化统计sql
spring.datasource.druid.filter.stat.merge-sql=true
- logback配置
cn-hangzhou-intranet.log.aliyuncs.com
xxxxxx
xxxxxxxx
xxxxxx
druid-slow-query
日志服务相关信息参考:https://help.aliyun.com/document_detail/29008.html?spm=5176.2020520112.108.2.3d6a34c0YhmO5s
正确配置后,可以在日志查询中看到类似如下信息:

在云监控>日志服务中,可以对该日志配置按写入行数告警:

业务系统异常监控告警
业务系统异常日志采集并上传到日志服务后,需要对信息进行过滤和抑制,否则告警会过于频繁。
首先需要在相应日志查询页面选择开启索引,在配置页关闭全文索引并根据业务系统异常日志格式配置字段,以springboot系统日志为例,我们这里配置了2个字段:

然后选择创建告警,例如我们在查询语句中过滤掉自定义异常和可预见的异常,每分钟扫描1次日志,如果某1分钟内系统发生5次异常就产生告警,可以按下面配置创建:

业务关键指标监控告警
和异常信息配置类似,通过采集关键数据指标并配置好告警规则即可实现
参考资料:
https://cloud.tencent.com/developer/article/1037231