本文介绍的文章题目为《Learning and Transferring IDs Representation in E-commerce》,下载地址为:https://arxiv.org/abs/1712.08289
本文介绍了一种ID类特征的表示方法。该方法基于item2vec方式,同时考虑了不同ID类特征之间的连接结构,在盒马鲜生app上取得了不错的应用效果,我们来一探究竟。
1、背景
在推荐系统特别是电商领域的推荐中,ID类特征是至关重要的的特征。传统的处理方式一般是one-hot编码。但是这种处理方式存在两个主要的弊端:
1)高维稀疏问题:对于高维稀疏问题,若有N个物品,那么用户交互过的物品的可能情况共2^N种情况,为了使我们的模型更加具有可信度,所需要的样本数量是随着N的增加呈指数级增加的。
2)它无法反映ID之间的关系:对于同质信息来说,比如不同的物品,假设是iphon5和iphone6,以及iphone5和华为,在转换成one-hot编码后,距离是一样的,但是实际上,iphon5和iphone6的距离应该更近。对于异质信息,如物品ID和商铺ID,它们的距离甚至无法衡量,但实际上,一家卖苹果手机的商铺和苹果手机之间,距离应该更近。
对于上述问题,出现了word2vec以及item2vec的解决方案,将ID类特征转换为一个低维的embedding向量,这种方式在电商领域的推荐中取得了不错的效果。
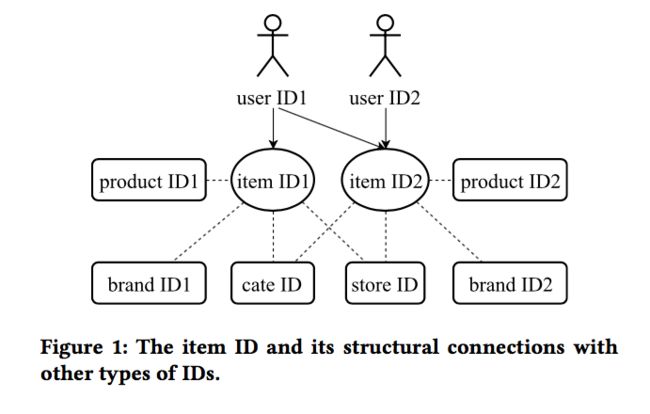
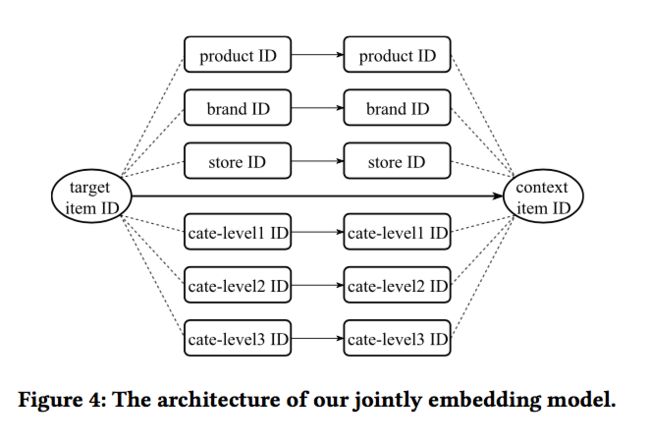
本文提出的方式,基于item2vec,同时还考虑了不同ID类特征之间的连接结构,通过这些连接,在ItemID序列中的信息可以传播到其它类型的ID特征,并且可以同时学习这些ID特征的表示,框架如下图所示:
上面的学习方式在盒马app中有以下几方面的应用:
1)Measuring the similarity between items:建模物品之间的相似度
2)Transferring from seen items to unseen items:将已知物品的向量迁移到位置物品上
3)Transferring across different domains:将不同领域的向量进行迁移
4)Transferring across different tasks.:从不同的应用场景中进行迁移。
上面的几个应用我们在后文中会详细介绍。接下来,我们首先来介绍一下本文如何对ID类特征进行处理。
2、学习ID的表征方式
2.1 Skip-gram on User’s Interactive Sequences
在电商领域,我们可以通过用户的隐式反馈,整理得到用户的一个交互序列。如果把每一个交互序列认为是一篇文档,那么我们可以通过Skip-Gram的方法来学习每一个item的向量。Skip-Gram的方法是最大化下面的对数概率:
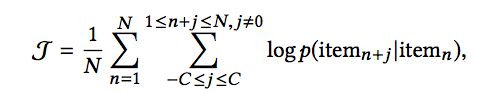
其中,C是我们的上下文长度,假设长度是2,那么下图中梨的上下文就是前后的两个item:

有关Skip-Gram模型的相关知识,可以参考:https://www.cnblogs.com/peghoty/p/3857839.html
在基本的Skip-Gram模型中,概率计算方式定义为如下的softmax方程:

其中,每个物品都有两套向量表示,分别是目标向量表示和上下文向量表示。D表示item的总数量。
2.2 Log-uniform Negative-sampling
当item的总数量十分巨大时,求解Skip-Gram的方法通常是负采样的方式,此时概率计算如下:

这里使用的负采样方式是Log-uniform Negative-sampling。简单介绍一下其流程:首先将D个物品按照其出现的频率进行降序排序,那么排名越靠前的物品,其出现的频率越高。采样基于Zipfian分布,每个物品采样到的概率如下:
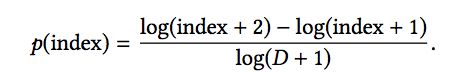
由于分母都是一样的,分子依次为log(2/1),log(3/2)...log(D+1/D),是顺次减小的,同时求和为1。那么排名越靠前即出现频率越高的商品,被采样到的概率是越大的。
那么,该分布的累积分布函数为:
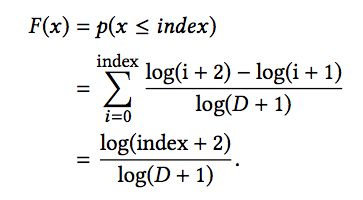
这样,当随机产生一个(0,1]之间的随机数r时,可以通过下面的转换快速得到对应的index:

2.3 IDs and Their Structural Connections
实际应用中,有许多组不同的ID,但是可以归结为两组:
1)物品ID及其属性ID:物品item ID是电商领域的核心,每一个物品有对应的属性ID,比如产品product ID,店铺store ID,品牌brand ID,品类category ID等。举个简单的例子,xxx店卖的哈登篮球鞋是一个物品item ID,其对应的产品是哈登篮球鞋,对应一个product ID,另一家店卖的同款哈登篮球鞋是另一个item ID。xxx店对应的是一个store ID,addias是哈登篮球鞋对应的品牌brand ID,而篮球鞋是其对应的category ID。品类ID可能有分一级品类、二级品类和三级品类。
2)用户ID:用户身份可以通过ID进行识别,这里的ID可以有多种形式,如cookie、uuid、用户昵称等等。
2.4 Jointly Embedding Attribute IDs
如何将上面所说的属性ID加入到物品ID的表示上来呢?结构如下:
这里,定义itemi的ID组IDs(itemi)如下:

这里,id1(itemi)代表物品本身,id2(itemi)代表产品ID,id3(itemi)代表店铺ID等等。那么,Skip-gram的概率计算变为如下的方式:
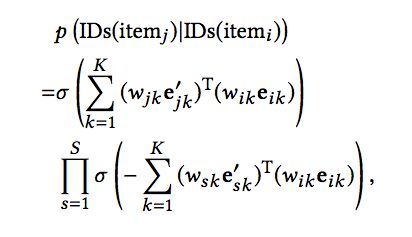
这里,每一种ID的向量长度可以是不同的,也就是说不通的ID类映射到不同的语义空间中。而权重的定义方式如下:
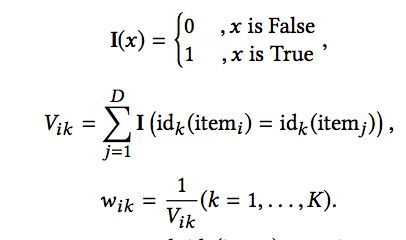
比如,wi1=1,因为itemi是唯一的,而如果itemi对应的产品有10种item的话,那么wi2=1/10。
除了上面计算的item之间的共现概率外,我们还希望,属性ID和itemID之间也要满足一定的关系,简单理解就是希望itemID和其对应的属性ID关系越近越好,于是定义:
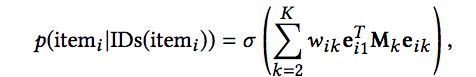
其中Mk将item ID对应的向量转换成跟每个属性ID对应向量长度一样的向量。
结合两部分的对数概率,加入正则项,则我们期望最大化的式子变为:
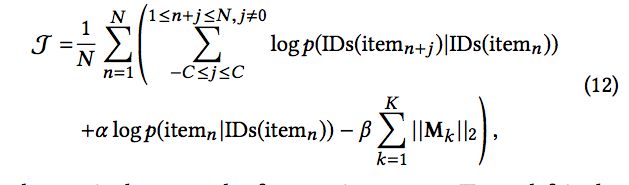
2.5 Embedding User IDs
用户ID的Embedding通常通过其交互过的item表示,比如通过一个RNN模型或者简单的取平均的方式,这里我们将用户最近交互过的T个物品对应向量的平均值,来代表用户的Embedding:

这里提到的是用平均值法代表用户的Embedding,后文还提到了一种加权法,主要根据用户的不同行为对T个物品进行加权,比如,购买过的物品要比只点击不购买的物品获得更高的权重。
2.6 Model Learning
模型的训练具体参数如下:

3、应用
本节我们来介绍一下上述方法的四种应用。在应用中,上述的框架我们将其定义为一种ITEM2VEC的方法。下文中ITEM2VEC便指代本文提出的新方法。
3.1 Measuring Items Similarity
在电商领域中,一种简单却有效的方式就是推荐给用户其喜欢的相似物品。通常使用cosine相似度来计算物品之间的相似度。那么应用上面的框架,基于得到的物品向量,便可以计算其相似度,进而推荐相似度最高的N个物品。
我们将其与协同过滤方法进行了对比,结果如下:

可以看到,点击率超过了协同过滤模型。
3.2 Transferring from Seen Items to Unseen Items
对于新的物品,无法得到其向量表示,这导致了许多推荐系统无法对新物品进行处理。但本文提出的方法可以在一定程度上解决冷启动问题。在模型训练时,我们添加了约束,即希望itemID和其对应的属性ID关系越近越好,如下式:
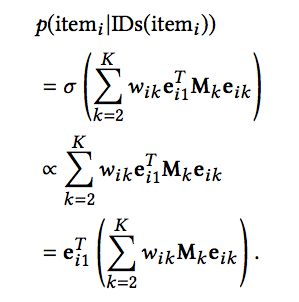
我们期望上面的式子越接近于1越好,因此:
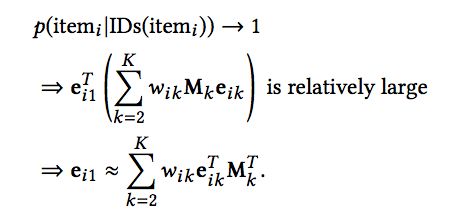
那么对于新的物品,其对应的属性ID我们往往是知道的,基于其属性ID对应的向量,我们便可以近似计算新物品的向量。上面最后一个地方可以好好理解一下,为什么可以表示成近似?
我的思考如下(不一定正确,望指正):如果我们把括号里面的向量表示成另一个向量e的话,当两个向量长度固定的时候,什么时候内积取得最大值?是二者同向且共线的时候,那么ei1和e应该是线性关系,即使e是真实的ei1的n倍的话,在计算该物品与其他物品的相似度的时候,是不会产生影响的,因此ei1可近似用e来代替。
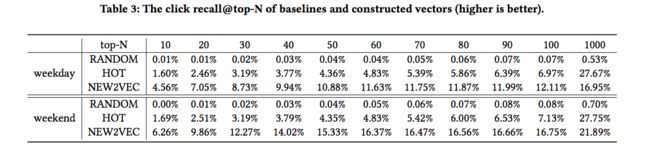
实验结果也表明,这种代替方式是十分有效的。下面的表格展示了实验结果:
3.3 Transferring across Different Domains
第三个应用主要是针对用户冷启动,在盒马平台上,相对于淘宝平台用户数量还是少很多的。那么对于盒马平台上的新用户,我们如何进行推荐呢?过程如下:

这里,用Us表示淘宝的用户,Ut表示盒马的用户,Ui表示既是淘宝又是盒马的用户,那么进行推荐的过程如下:
1)计算淘宝用户Us之间的相似度,相似度的计算基于用户最近在淘宝交互过的T个商品的向量。可以是简单的平均,可以是加权平均。权重取决于人工的设定,比如购买是5,点击是1;
2)基于计算的用户相似度,对Ui中的用户进行k-均值聚类,这里聚成1000个类别;
3)对于每个类别,选择N个最受欢迎的盒马上的物品,作为候选集;
4)对于盒马上的一个新用户,如果它在淘宝上有交互记录,那么就取得他在淘宝上对应的用户向量,并计算该向量所属的类别;
5)基于得到的类别,将经过筛选和排序后的该类别的候选集中物品中推荐给用户。
我们对比了三种不同策略的PPM(Pay-Per-Impression)值,三种策略为:
1)推荐给新用户最热门的物品,该组为Base
2)基于简单平均的方式计算用户向量
3)基于加权平均的方式计算用户向量
实验结果表明,采用简单平均的方式,PPM提升71.4%,采用加权平均的方式,PPM提升141.8%。
3.4 Transferring across Different Tasks
这里,我们主要对每个店铺第二天每个30分钟的配送需求进行预测,这里有三种不同的输入:
1)仅使用过去7天每三十分钟的店铺配送量作为输入
2)使用使用过去7天每三十分钟的店铺配送量作为输入 + 店铺ID的one-hot encoding
3)使用使用过去7天每三十分钟的店铺配送量作为输入 + 店铺ID对应的向量。
输入经过全联接神经网络得到配送需求的预测值,并通过RMAE指标来计算误差,结果如下:

4、总结
本文介绍了一种处理ID类特征的方式,该方式基于Skip-Gram方法,并考虑了多种不同ID类特征之间的联系。本文介绍了该方法的详细过程,以及在盒马app上的具体应用,具有一定的参考价值。