PyTorch深度学习框架60天进阶学习计划 - 第28天:多模态模型实践(一)
PyTorch深度学习框架60天进阶学习计划 - 第28天:多模态模型实践(一)
引言:跨越感知的边界
欢迎来到我们的PyTorch学习旅程第28天!今天我们将步入AI世界中最激动人心的领域之一:多模态学习。想象一下,如果你的模型既能"看"又能"读",并且能够理解图像与文字之间的联系,这将为我们打开怎样的可能性?
今天我们将专注于构建图文匹配系统,学习如何使用CLIP(Contrastive Language-Image Pre-training)架构来实现跨模态特征空间对齐。这就像教会模型同时精通两种"语言"——图像语言和文本语言,并在它们之间建立翻译桥梁。
让我们开始这段精彩的旅程吧!
1. 多模态学习与CLIP架构概述
1.1 什么是多模态学习?
多模态学习是指同时处理和理解来自不同感知渠道(模态)的信息,如视觉、语言、音频等。就像人类能够同时理解看到的图像和听到的声音一样,多模态学习使AI能够整合和处理来自不同源的信息。
1.2 CLIP架构简介
CLIP(Contrastive Language-Image Pre-training)是由OpenAI开发的一种革命性架构,它通过对比学习的方式将文本和图像投影到同一特征空间。CLIP的核心思想是:
- 使用两个独立的编码器:一个处理图像,一个处理文本
- 通过对比学习将相关的图像-文本对拉近,将不相关的推远
- 创建一个统一的特征空间,使得语义相似的图像和文本在该空间中靠近
1.3 CLIP架构的优势
| 优势 | 描述 |
|---|---|
| 零样本迁移能力 | 训练后无需额外微调即可应用于多种下游任务 |
| 强大的泛化能力 | 能够泛化到训练中未见过的视觉概念 |
| 跨模态检索 | 能够使用文本查找图像,或使用图像查找相关文本 |
| 开放词汇识别 | 不受预定义类别限制,可以识别任意文本描述的内容 |
| 多语言潜力 | 可扩展到多语言场景,实现跨语言图像理解 |
2. CLIP架构详解
CLIP架构由以下核心组件构成:
2.1 CLIP架构组件
| 组件 | 功能 |
|---|---|
| 图像编码器 | 将图像转换为特征向量(通常使用Vision Transformer或ResNet) |
| 文本编码器 | 将文本转换为特征向量(通常使用Transformer架构) |
| 投影层 | 将两种模态的特征映射到共同的多模态空间 |
| 对比损失函数 | 优化模型使得匹配的图文对在特征空间中靠近 |
| 温度参数 | 控制特征分布的"软硬程度",影响对比学习的难度 |
2.2 CLIP训练流程
- 收集大量图像-文本对(如图像及其描述)
- 图像通过图像编码器生成图像特征
- 文本通过文本编码器生成文本特征
- 计算批次内所有可能图像-文本对的相似度矩阵
- 使用对比损失优化模型,使匹配对的相似度高,不匹配对的相似度低
- 不断迭代上述过程,直到模型收敛
2.3 CLIP训练与推理流程图
┌───────────────┐ ┌─────────────────┐
│ 图像数据 │ │ 文本数据 │
└───────┬───────┘ └────────┬────────┘
│ │
▼ ▼
┌───────────────┐ ┌─────────────────┐
│ 图像编码器 │ │ 文本编码器 │
│ (ResNet/ViT) │ │ (Transformer) │
└───────┬───────┘ └────────┬────────┘
│ │
▼ ▼
┌───────────────┐ ┌─────────────────┐
│ 图像特征向量 │ │ 文本特征向量 │
└───────┬───────┘ └────────┬────────┘
│ │
▼ ▼
┌──────────────────────────────┐
│ 特征空间对齐(投影) │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ 对比损失计算 │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ 模型优化 │
└──────────────────────────────┘
3. 构建图文匹配系统:实战时间
现在让我们使用PyTorch实现一个简化版的CLIP模型,用于图文匹配。我们将使用预训练的ResNet作为图像编码器,使用预训练的BERT作为文本编码器。
3.1 环境准备
首先,我们需要安装必要的库:
# 安装所需库
# pip install torch torchvision transformers pillow matplotlib tqdm
3.2 导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision import models, transforms
from transformers import BertModel, BertTokenizer
from PIL import Image
import matplotlib.pyplot as plt
import os
import json
import random
from tqdm import tqdm
import numpy as np
3.3 定义我们的CLIP模型
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
from transformers import BertModel
class ImageEncoder(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
# 使用预训练的ResNet50作为图像编码器
self.model = models.resnet50(pretrained=True)
# 移除最后的分类层
self.model.fc = nn.Identity()
# 添加投影层,将特征映射到指定维度
self.projection = nn.Linear(2048, embed_dim)
def forward(self, x):
features = self.model(x)
projected_features = self.projection(features)
# 归一化特征向量
return F.normalize(projected_features, p=2, dim=1)
class TextEncoder(nn.Module):
def __init__(self, embed_dim=512):
super().__init__()
# 使用预训练的BERT作为文本编码器
self.model = BertModel.from_pretrained('bert-base-uncased')
# 添加投影层
self.projection = nn.Linear(768, embed_dim)
def forward(self, input_ids, attention_mask):
# 获取BERT的[CLS]令牌输出作为文本表示
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask)
cls_features = outputs.last_hidden_state[:, 0, :] # 取[CLS]标记的特征
projected_features = self.projection(cls_features)
# 归一化特征向量
return F.normalize(projected_features, p=2, dim=1)
class CLIP(nn.Module):
def __init__(self, embed_dim=512, temperature=0.07):
super().__init__()
self.image_encoder = ImageEncoder(embed_dim)
self.text_encoder = TextEncoder(embed_dim)
self.temperature = temperature # 温度参数控制softmax的平滑程度
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / temperature))
def forward(self, images, input_ids, attention_mask):
# 获取图像和文本特征
image_features = self.image_encoder(images)
text_features = self.text_encoder(input_ids, attention_mask)
# 计算图像-文本相似度矩阵
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
return logits_per_image, logits_per_text
def encode_image(self, images):
"""单独编码图像"""
return self.image_encoder(images)
def encode_text(self, input_ids, attention_mask):
"""单独编码文本"""
return self.text_encoder(input_ids, attention_mask)
3.4 创建数据集类
import torch
from torch.utils.data import Dataset
from PIL import Image
import os
from torchvision import transforms
class ImageTextDataset(Dataset):
def __init__(self, image_paths, captions, tokenizer, transform=None, max_length=64):
"""
图文对数据集
Args:
image_paths (list): 图像路径列表
captions (list): 对应的文本描述列表
tokenizer: BERT分词器
transform: 图像变换
max_length: 文本最大长度
"""
self.image_paths = image_paths
self.captions = captions
self.tokenizer = tokenizer
self.max_length = max_length
# 设置默认的图像变换
if transform is None:
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
else:
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
# 加载并转换图像
image_path = self.image_paths[idx]
try:
image = Image.open(image_path).convert('RGB')
image = self.transform(image)
except Exception as e:
print(f"Error loading image {image_path}: {e}")
# 生成一个随机图像作为替代
image = torch.randn(3, 224, 224)
# 处理文本
caption = self.captions[idx]
encoding = self.tokenizer(
caption,
padding='max_length',
truncation=True,
max_length=self.max_length,
return_tensors='pt'
)
# 去掉批次维度
input_ids = encoding['input_ids'].squeeze()
attention_mask = encoding['attention_mask'].squeeze()
return {
'image': image,
'input_ids': input_ids,
'attention_mask': attention_mask,
'caption': caption # 保留原始文本以便后续分析
}
class ImageTextContrastiveDataset(ImageTextDataset):
"""
增强版数据集,为对比学习提供正负样本对
"""
def __init__(self, image_paths, captions, tokenizer, transform=None, max_length=64, negative_samples=1):
super().__init__(image_paths, captions, tokenizer, transform, max_length)
self.negative_samples = negative_samples
def __getitem__(self, idx):
# 获取正样本对
pos_sample = super().__getitem__(idx)
# 为每个样本构建负样本
neg_indices = []
for _ in range(self.negative_samples):
neg_idx = random.randint(0, len(self) - 1)
while neg_idx == idx: # 确保不选择自身作为负样本
neg_idx = random.randint(0, len(self) - 1)
neg_indices.append(neg_idx)
# 获取负样本文本
neg_captions = [self.captions[i] for i in neg_indices]
neg_encodings = self.tokenizer(
neg_captions,
padding='max_length',
truncation=True,
max_length=self.max_length,
return_tensors='pt'
)
# 将正负样本组合在一起
pos_sample['neg_input_ids'] = neg_encodings['input_ids']
pos_sample['neg_attention_mask'] = neg_encodings['attention_mask']
pos_sample['neg_captions'] = neg_captions
return pos_sample
3.5 实现对比损失函数和训练逻辑
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from torch.optim.lr_scheduler import CosineAnnealingLR
from tqdm import tqdm
import numpy as np
class CLIPLoss(nn.Module):
def __init__(self):
super().__init__()
self.cross_entropy = nn.CrossEntropyLoss()
def forward(self, logits_per_image, logits_per_text):
# 创建标签:对角线上为匹配的图文对
batch_size = logits_per_image.shape[0]
labels = torch.arange(batch_size).to(logits_per_image.device)
# 计算图像到文本和文本到图像的损失
loss_i2t = self.cross_entropy(logits_per_image, labels)
loss_t2i = self.cross_entropy(logits_per_text, labels)
# 总损失是两者的平均
total_loss = (loss_i2t + loss_t2i) / 2
return total_loss
class CLIPTrainer:
def __init__(self, model, train_dataloader, val_dataloader=None,
device='cuda' if torch.cuda.is_available() else 'cpu',
lr=1e-4, weight_decay=0.01, epochs=10):
self.model = model.to(device)
self.train_dataloader = train_dataloader
self.val_dataloader = val_dataloader
self.device = device
# 初始化优化器
self.optimizer = Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
self.scheduler = CosineAnnealingLR(self.optimizer, T_max=epochs)
self.criterion = CLIPLoss()
self.epochs = epochs
# 跟踪指标
self.train_losses = []
self.val_losses = []
self.best_val_loss = float('inf')
def train_epoch(self):
self.model.train()
total_loss = 0
for batch in tqdm(self.train_dataloader, desc='Training'):
# 将数据移至设备
images = batch['image'].to(self.device)
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
# 前向传播
logits_per_image, logits_per_text = self.model(images, input_ids, attention_mask)
# 计算损失
loss = self.criterion(logits_per_image, logits_per_text)
# 反向传播和优化
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(self.train_dataloader)
self.train_losses.append(avg_loss)
return avg_loss
def validate(self):
if self.val_dataloader is None:
return None
self.model.eval()
total_loss = 0
with torch.no_grad():
for batch in tqdm(self.val_dataloader, desc='Validating'):
# 将数据移至设备
images = batch['image'].to(self.device)
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
# 前向传播
logits_per_image, logits_per_text = self.model(images, input_ids, attention_mask)
# 计算损失
loss = self.criterion(logits_per_image, logits_per_text)
total_loss += loss.item()
avg_loss = total_loss / len(self.val_dataloader)
self.val_losses.append(avg_loss)
# 保存最佳模型
if avg_loss < self.best_val_loss:
self.best_val_loss = avg_loss
torch.save(self.model.state_dict(), 'best_clip_model.pth')
return avg_loss
def train(self):
print(f"Training on {self.device}")
for epoch in range(self.epochs):
print(f"\nEpoch {epoch+1}/{self.epochs}")
# 训练一个epoch
train_loss = self.train_epoch()
print(f"Training Loss: {train_loss:.4f}")
# 验证
if self.val_dataloader is not None:
val_loss = self.validate()
print(f"Validation Loss: {val_loss:.4f}")
# 更新学习率
self.scheduler.step()
current_lr = self.scheduler.get_last_lr()[0]
print(f"Learning Rate: {current_lr:.6f}")
# 保存最终模型
torch.save(self.model.state_dict(), 'final_clip_model.pth')
print("Training completed!")
return self.train_losses, self.val_losses
3.6 完整的训练流程
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, random_split
from torchvision import transforms
from transformers import BertTokenizer
import matplotlib.pyplot as plt
import os
import json
import random
import numpy as np
from PIL import Image
from tqdm import tqdm
import argparse
# 导入我们自己定义的模块
from clip_model import CLIP
from clip_dataset import ImageTextDataset
from clip_trainer import CLIPTrainer
# 设置随机种子以便复现结果
def set_seed(seed=42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def load_flickr8k_data(root_dir):
"""
加载Flickr8k数据集,这是一个常用的图文配对数据集
Args:
root_dir: 数据集根目录
Returns:
image_paths: 图像路径列表
captions: 对应的文本描述列表
"""
images_dir = os.path.join(root_dir, 'Images')
captions_file = os.path.join(root_dir, 'captions.txt')
# 读取图像文件列表
image_files = [f for f in os.listdir(images_dir) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 读取描述文件
with open(captions_file, 'r', encoding='utf-8') as f:
captions_data = f.readlines()
# 解析描述文件并匹配图像
image_paths = []
captions = []
for line in captions_data[1:]: # 跳过标题行
parts = line.strip().split(',')
if len(parts) >= 2:
image_name = parts[0]
caption = parts[1]
if image_name in image_files:
image_path = os.path.join(images_dir, image_name)
image_paths.append(image_path)
captions.append(caption)
return image_paths, captions
def create_dummy_data(num_samples=100):
"""
创建虚拟数据用于测试
"""
# 设定一些文本描述模板
objects = ["cat", "dog", "bird", "car", "flower", "tree", "house", "person", "book", "computer"]
colors = ["red", "blue", "green", "yellow", "black", "white", "purple", "orange"]
actions = ["running", "sleeping", "playing", "standing", "sitting", "flying", "driving", "reading"]
locations = ["in the park", "on the beach", "in the house", "on the street", "in the garden"]
# 创建随机图像(只是为了测试,实际应用中应使用真实图像)
os.makedirs("dummy_images", exist_ok=True)
image_paths = []
captions = []
for i in range(num_samples):
# 创建随机彩色图像
img = Image.new('RGB', (224, 224), color=(
random.randint(0, 255),
random.randint(0, 255),
random.randint(0, 255)
))
# 保存图像
image_path = f"dummy_images/image_{i}.jpg"
img.save(image_path)
image_paths.append(image_path)
# 生成随机描述
obj = random.choice(objects)
color = random.choice(colors)
action = random.choice(actions)
location = random.choice(locations)
caption = f"A {color} {obj} {action} {location}"
captions.append(caption)
return image_paths, captions
def plot_training_curves(train_losses, val_losses=None):
"""绘制训练曲线"""
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Training Loss')
if val_losses:
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('CLIP Training Curves')
plt.legend()
plt.grid(True)
plt.savefig('training_curves.png')
plt.show()
def visualize_image_text_matches(model, dataloader, device, num_examples=5):
"""可视化图像-文本匹配结果"""
model.eval()
# 获取一批数据
batch = next(iter(dataloader))
images = batch['image'].to(device)
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
captions = batch['caption']
# 获取相似度
with torch.no_grad():
logits_per_image, _ = model(images, input_ids, attention_mask)
similarities = logits_per_image.cpu().numpy()
# 可视化前num_examples个样本
plt.figure(figsize=(15, num_examples * 3))
for i in range(min(num_examples, len(images))):
# 获取当前图像
img = images[i].cpu().permute(1, 2, 0).numpy()
# 反归一化
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img = img * std + mean
img = np.clip(img, 0, 1)
# 获取相似度
similarity_scores = similarities[i]
# 绘制图像
plt.subplot(num_examples, 2, i*2+1)
plt.imshow(img)
plt.title(f"Image {i}")
plt.axis('off')
# 绘制相似度条形图
plt.subplot(num_examples, 2, i*2+2)
top_k = min(5, len(similarity_scores))
indices = np.argsort(similarity_scores)[::-1][:top_k]
plt.barh(range(top_k), [similarity_scores[idx] for idx in indices])
plt.yticks(range(top_k), [captions[idx][:50] + '...' for idx in indices])
plt.xlabel('Similarity Score')
plt.title(f"Top {top_k} Caption Matches")
plt.tight_layout()
plt.savefig('image_text_matches.png')
plt.show()
def main(args):
# 设置随机种子
set_seed(args.seed)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 加载数据
if args.use_dummy_data:
print("Using dummy data for testing...")
image_paths, captions = create_dummy_data(args.num_samples)
else:
print(f"Loading data from {args.data_dir}...")
image_paths, captions = load_flickr8k_data(args.data_dir)
print(f"Loaded {len(image_paths)} image-caption pairs")
# 初始化BERT分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 创建数据集
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = ImageTextDataset(
image_paths=image_paths,
captions=captions,
tokenizer=tokenizer,
transform=transform,
max_length=args.max_length
)
# 分割数据集
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
# 创建数据加载器
train_dataloader = DataLoader(
train_dataset,
batch_size=args.batch_size,
shuffle=True,
num_workers=args.num_workers
)
val_dataloader = DataLoader(
val_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=args.num_workers
)
# 初始化模型
model = CLIP(embed_dim=args.embed_dim, temperature=args.temperature)
# 初始化训练器
trainer = CLIPTrainer(
model=model,
train_dataloader=train_dataloader,
val_dataloader=val_dataloader,
device=device,
lr=args.learning_rate,
weight_decay=args.weight_decay,
epochs=args.epochs
)
# 训练模型
print("Starting training...")
train_losses, val_losses = trainer.train()
# 绘制训练曲线
plot_training_curves(train_losses, val_losses)
# 可视化图像-文本匹配
if args.visualize:
print("Visualizing image-text matches...")
visualize_image_text_matches(model, val_dataloader, device, num_examples=5)
print("Done!")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="CLIP Training")
# 数据相关参数
parser.add_argument("--data_dir", type=str, default="./flickr8k", help="Directory with images and captions")
parser.add_argument("--use_dummy_data", action="store_true", help="Use dummy data for testing")
parser.add_argument("--num_samples", type=int, default=100, help="Number of dummy samples to generate")
parser.add_argument("--max_length", type=int, default=64, help="Maximum length of text")
# 模型相关参数
parser.add_argument("--embed_dim", type=int, default=512, help="Embedding dimension")
parser.add_argument("--temperature", type=float, default=0.07, help="Temperature parameter")
# 训练相关参数
parser.add_argument("--batch_size", type=int, default=32, help="Batch size")
parser.add_argument("--learning_rate", type=float, default=1e-4, help="Learning rate")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay")
parser.add_argument("--epochs", type=int, default=10, help="Number of epochs")
parser.add_argument("--num_workers", type=int, default=4, help="Number of workers for data loading")
parser.add_argument("--seed", type=int, default=42, help="Random seed")
# 其他参数
parser.add_argument("--visualize", action="store_true", help="Visualize results")
args = parser.parse_args()
main(args)
3.7 使用训练好的模型进行图文检索
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
from transformers import BertTokenizer
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import os
from tqdm import tqdm
# 导入自定义模块
from clip_model import CLIP
class CLIPRetrieval:
def __init__(self, model_path, device='cuda' if torch.cuda.is_available() else 'cpu'):
"""
初始化CLIP检索系统
Args:
model_path: 预训练模型路径
device: 使用的设备
"""
self.device = device
self.model = CLIP(embed_dim=512).to(device)
# 加载预训练权重
self.model.load_state_dict(torch.load(model_path, map_location=device))
self.model.eval()
# 初始化BERT分词器
self.tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 图像转换
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 存储索引
self.image_features = None
self.image_paths = None
def build_image_index(self, image_dir):
"""
为图像目录构建特征索引
Args:
image_dir: 图像目录路径
"""
# 获取所有图像文件
self.image_paths = [
os.path.join(image_dir, f) for f in os.listdir(image_dir)
if f.lower().endswith(('.jpg', '.jpeg', '.png'))
]
# 收集所有图像特征
all_features = []
print(f"Indexing {len(self.image_paths)} images...")
for img_path in tqdm(self.image_paths):
try:
# 加载并转换图像
img = Image.open(img_path).convert('RGB')
img_tensor = self.transform(img).unsqueeze(0).to(self.device)
# 计算特征
with torch.no_grad():
features = self.model.encode_image(img_tensor)
all_features.append(features.cpu())
except Exception as e:
print(f"Error processing {img_path}: {e}")
# 将所有特征连接为一个张量
self.image_features = torch.cat(all_features, dim=0)
print(f"Indexed {len(self.image_features)} images successfully")
def text_to_image_search(self, query_text, top_k=5):
"""
使用文本查询图像
Args:
query_text: 查询文本
top_k: 返回的结果数量
Returns:
top_image_paths: 最相似图像的路径
similarities: 相似度分数
"""
if self.image_features is None or self.image_paths is None:
raise ValueError("Image index not built. Call build_image_index first.")
# 对文本进行编码
encoding = self.tokenizer(
query_text,
padding='max_length',
truncation=True,
max_length=64,
return_tensors='pt'
)
input_ids = encoding['input_ids'].to(self.device)
attention_mask = encoding['attention_mask'].to(self.device)
# 计算文本特征
with torch.no_grad():
text_features = self.model.encode_text(input_ids, attention_mask)
# 计算与所有图像的相似度
text_features = text_features.cpu()
similarities = F.cosine_similarity(text_features, self.image_features)
# 获取最相似的图像
top_indices = similarities.argsort(descending=True)[:top_k]
top_image_paths = [self.image_paths[idx] for idx in top_indices]
top_similarities = similarities[top_indices].tolist()
return top_image_paths, top_similarities
def image_to_text_search(self, query_image_path, text_candidates, top_k=5):
"""
使用图像查询文本
Args:
query_image_path: 查询图像路径
text_candidates: 候选文本列表
top_k: 返回的结果数量
Returns:
top_texts: 最相似的文本
similarities: 相似度分数
"""
# 加载并处理查询图像
img = Image.open(query_image_path).convert('RGB')
img_tensor = self.transform(img).unsqueeze(0).to(self.device)
# 编码图像
with torch.no_grad():
image_features = self.model.encode_image(img_tensor)
# 编码所有候选文本
text_features = []
for text in text_candidates:
encoding = self.tokenizer(
text,
padding='max_length',
truncation=True,
max_length=64,
return_tensors='pt'
)
input_ids = encoding['input_ids'].to(self.device)
attention_mask = encoding['attention_mask'].to(self.device)
with torch.no_grad():
features = self.model.encode_text(input_ids, attention_mask)
text_features.append(features)
# 连接所有文本特征
text_features = torch.cat(text_features, dim=0)
# 计算相似度
image_features = image_features.cpu()
text_features = text_features.cpu()
similarities = F.cosine_similarity(image_features, text_features)
# 获取最相似的文本
top_indices = similarities.argsort(descending=True)[:top_k]
top_texts = [text_candidates[idx] for idx in top_indices]
top_similarities = similarities[top_indices].tolist()
return top_texts, top_similarities
def visualize_text_search_results(self, query_text, top_k=5):
"""
可视化文本到图像搜索结果
Args:
query_text: 查询文本
top_k: 结果数量
"""
# 执行搜索
top_image_paths, similarities = self.text_to_image_search(query_text, top_k)
# 可视化结果
plt.figure(figsize=(15, 10))
for i, (img_path, similarity) in enumerate(zip(top_image_paths, similarities)):
# 加载图像
img = Image.open(img_path).convert('RGB')
# 显示图像
plt.subplot(1, top_k, i + 1)
plt.imshow(img)
plt.title(f"Similarity: {similarity:.3f}")
plt.axis('off')
plt.suptitle(f'Images matching: "{query_text}"', fontsize=16)
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.savefig('text_search_results.png')
plt.show()
# 使用示例
def demo_clip_retrieval():
"""演示CLIP检索系统的使用"""
# 初始化检索系统
retrieval = CLIPRetrieval(model_path='best_clip_model.pth')
# 构建图像索引
image_dir = 'dummy_images' # 替换为你的图像目录
retrieval.build_image_index(image_dir)
# 执行文本到图像搜索
query_text = "A red cat sitting in the garden"
retrieval.visualize_text_search_results(query_text, top_k=5)
# 执行图像到文本搜索
query_image_path = 'dummy_images/image_0.jpg' # 替换为你的查询图像
text_candidates = [
"A red cat sitting in the garden",
"A blue car driving on the street",
"A person reading a book in the park",
"A yellow dog playing in the house",
"A white flower in the garden"
]
top_texts, similarities = retrieval.image_to_text_search(
query_image_path, text_candidates
)
print(f"Image: {query_image_path}")
print("Top matching texts:")
for text, sim in zip(top_texts, similarities):
print(f"{sim:.3f}: {text}")
if __name__ == "__main__":
demo_clip_retrieval()
4. 理解CLIP的核心机制与训练技巧
4.1 对比学习详解
对比学习(Contrastive Learning)是CLIP模型的核心训练方法。它的基本思想是:
- 将语义相关的样本对(如图片和对应的描述)在特征空间中拉近
- 将语义不相关的样本对(如图片和随机的描述)在特征空间中推远
这种学习范式使得模型能够学习到跨模态的语义对齐,从而实现图文匹配。
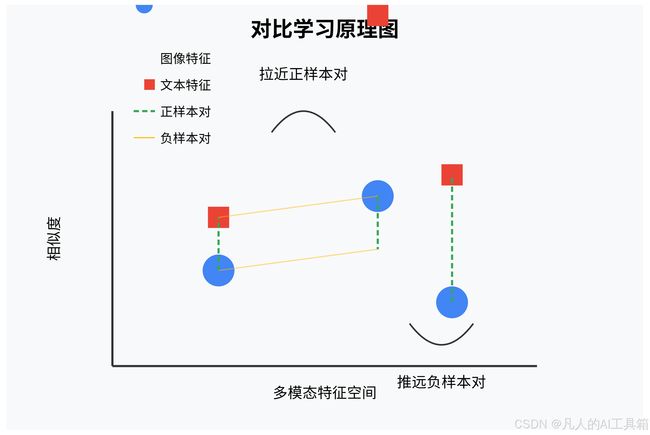
4.2 CLIP模型核心训练技巧
| 技巧 | 描述 | 作用 |
|---|---|---|
| 批量大小 | 使用大批量训练 | 提供更多的负样本,提高对比学习效果 |
| 温度参数 | 调整logit缩放的温度系数 | 控制softmax分布的锐度,影响学习难度 |
| 数据增强 | 对图像应用数据增强 | 提高模型的鲁棒性和泛化能力 |
| 对称损失 | 同时使用图像→文本和文本→图像两个方向的损失 | 确保两个模态的特征空间对齐 |
| 学习率预热 | 初期使用较小学习率,然后逐渐增大 | 稳定初期训练,避免早期发散 |
| 权重衰减 | 应用适当的权重正则化 | 防止过拟合,提高泛化能力 |
| 特征归一化 | 对特征向量进行L2归一化 | 使用余弦相似度度量特征向量间的相似度 |
| 模型选择 | 为不同模态选择合适的编码器 | 平衡性能与计算效率 |
4.3 困难负样本挖掘
标准的对比学习在批次内随机选择负样本,但随着训练的进行,这些负样本可能变得"过于简单",模型很容易将它们与正样本区分开。为了让模型继续进步,我们可以使用困难负样本挖掘技术:
- 在线困难负样本挖掘:在每个批次中,选择与锚点样本最相似的负样本作为困难负样本
- 硬采样:仅使用困难负样本进行训练
- 混合采样:结合随机负样本和困难负样本
- 加权对比损失:根据样本对的困难程度动态调整权重
以下是一个实现困难负样本挖掘的代码示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class HardNegativeMiningLoss(nn.Module):
def __init__(self, temperature=0.07, hard_negative_ratio=0.5):
super().__init__()
self.temperature = temperature
self.hard_negative_ratio = hard_negative_ratio
self.cross_entropy = nn.CrossEntropyLoss()
def forward(self, image_features, text_features):
"""
具有困难负样本挖掘的对比损失
Args:
image_features: 图像特征 [batch_size, embed_dim]
text_features: 文本特征 [batch_size, embed_dim]
Returns:
loss: 总损失
"""
# 确保特征已经归一化
image_features = F.normalize(image_features, p=2, dim=1)
text_features = F.normalize(text_features, p=2, dim=1)
# 计算余弦相似度矩阵
batch_size = image_features.shape[0]
sim_matrix = torch.matmul(image_features, text_features.t()) / self.temperature
# 创建目标标签:对角线为正样本
labels = torch.arange(batch_size).to(sim_matrix.device)
# 挖掘困难负样本
# 移除对角线元素(正样本)以寻找困难负样本
mask = torch.ones_like(sim_matrix, dtype=torch.bool)
mask.fill_diagonal_(False)
# 对于每个锚点,找到最相似的负样本
hard_negative_indices = []
for i in range(batch_size):
# 获取当前行/列的非对角元素
neg_sim_i2t = sim_matrix[i][mask[i]]
neg_sim_t2i = sim_matrix[:, i][mask[:, i]]
# 找到最相似的负样本索引
hard_neg_i2t = torch.argsort(neg_sim_i2t, descending=True)
hard_neg_t2i = torch.argsort(neg_sim_t2i, descending=True)
# 转换为原始索引
hard_neg_i2t_indices = torch.nonzero(mask[i]).squeeze()[hard_neg_i2t]
hard_neg_t2i_indices = torch.nonzero(mask[:, i]).squeeze()[hard_neg_t2i]
hard_negative_indices.append((hard_neg_i2t_indices, hard_neg_t2i_indices))
# 计算常规对比损失
i2t_loss = self.cross_entropy(sim_matrix, labels)
t2i_loss = self.cross_entropy(sim_matrix.t(), labels)
regular_loss = (i2t_loss + t2i_loss) / 2
# 如果不使用困难负样本,直接返回常规损失
if self.hard_negative_ratio <= 0:
return regular_loss
# 计算困难负样本损失
hard_loss = 0
# 只使用最困难的K个负样本
k = max(1, int(batch_size * self.hard_negative_ratio))
for i in range(batch_size):
# 获取硬负样本的索引
hard_i2t_indices = hard_negative_indices[i][0][:k]
hard_t2i_indices = hard_negative_indices[i][1][:k]
# 创建只包含正样本和困难负样本的相似度向量
i2t_indices = torch.cat([torch.tensor([i]), hard_i2t_indices]).to(sim_matrix.device)
t2i_indices = torch.cat([torch.tensor([i]), hard_t2i_indices]).to(sim_matrix.device)
i2t_sim = sim_matrix[i, i2t_indices]
t2i_sim = sim_matrix[t2i_indices, i]
# 创建对应的标签
i2t_label = torch.zeros(k + 1, dtype=torch.long).to(sim_matrix.device)
t2i_label = torch.zeros(k + 1, dtype=torch.long).to(sim_matrix.device)
# 计算困难对比损失
i2t_hard_loss = self.cross_entropy(i2t_sim.unsqueeze(0), i2t_label)
t2i_hard_loss = self.cross_entropy(t2i_sim.unsqueeze(0), t2i_label)
hard_loss += (i2t_hard_loss + t2i_hard_loss) / 2
hard_loss /= batch_size
# 组合常规损失和困难样本损失
total_loss = (1 - self.hard_negative_ratio) * regular_loss + self.hard_negative_ratio * hard_loss
return total_loss
# 使用示例
def demo_hard_negative_mining():
# 创建随机特征
batch_size = 8
embed_dim = 512
image_features = torch.randn(batch_size, embed_dim)
text_features = torch.randn(batch_size, embed_dim)
# 标准对比损失
standard_loss = HardNegativeMiningLoss(hard_negative_ratio=0)
std_loss_value = standard_loss(image_features, text_features)
# 困难负样本对比损失
hard_negative_loss = HardNegativeMiningLoss(hard_negative_ratio=0.5)
hard_loss_value = hard_negative_loss(image_features, text_features)
print(f"Standard Contrastive Loss: {std_loss_value.item():.4f}")
print(f"Hard Negative Mining Loss: {hard_loss_value.item():.4f}")
return std_loss_value, hard_loss_value
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!