要求:原操作系统代码里只是支持了日语显示,需要做的是实现对这个系统的汉字全角支持。
hzk16的介绍以及简单的使用方法
HZK16字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。其中一级汉字有3755个,按声序排列,二级汉字有3008个,按偏旁部首排列。我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
我们知道一个GB2312汉字是由两个字节编码的,范围为A1A1~FEFE。A1-A9为符号区,B0到F7为汉字区。每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)。下面以汉字“我”为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。
前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号。其中,每个区记录94个汉字,位号为该字在该区中的位置。所以要找到“我”在hzk16库中的位置就必须得到它的区码和位码。(为了区别使用了区码和区号,其实是一个东西,别被我误导了)
区码:区号(汉字的第一个字节)-0xa0 (因为汉字编码是从0xa0区开始的,所以文件最前面就是从0xa0区开始,要算出相对区码)
位码:位号(汉字的第二个字节)-0xa0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:
offset=(94*(区码-1)+(位码-1))*32
注解:1、区码减1是因为数组是以0为开始而区号位号是以1为开始的
2、(94*(区号-1)+位号-1)是一个汉字字模占用的字节数
3、最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息(前面提到一个汉字要有32个字节显示)
有了偏移地址就可以从HZK16中读取汉字编码了
实现思路:
- 了解HZK编码,理解一下符合GB2312标准的中文点阵字库文件HZK16;
- 下载中文GB2312的二进制点阵文件;
- 将HZK16.fnt文件放入nihongo文件夹中;
- 修改主makefile文件和app_make.txt文件,将原来装载nihongo.fnt的语句替换成装载HZK16.fnt即可;
- 修改bootpack.c文件,将之前分配的装载日语字体的内存扩大,载入字库的文件名;
- 在haribote/graphic.c中添加支持汉字的代码,增加一个函数用于显示汉字;
- 修改putfonts8_asc函数里if (task->langmode == 3)语句块;
- 测试程序。
- 注意:日文的编码是分为左半部分和右半部分,而我们使用的HZK16是分为上半部分和下半部分的。
这里其他的地方比较弄,第5步将大小修改一下,我的是nihongo = (unsigned char *) memman_alloc_4k(memman, 55*94*32);
第6步,要注意,HZK16是上下两部分,不同于日文的左右两部分的结构。
代码如下:
void putfont32(char *vram, int xsize, int x, int y, char c, char *font1, char *font2) { int i,k,j,f; char *p, d ; j=0; p=vram+(y+j)*xsize+x; j++; //上半部分 for(i=0;i<16;i++) { for(k=0;k<8;k++) { if(font1[i]&(0x80>>k)) { p[k+(i%2)*8]=c; } } if(i%2==0){ for(k=0;k<4;k++){ f=p[k]; p[k]=p[7-k]; p[7-k]=f; } }else{ for(k=0;k<4;k++){ f=p[k+8]; p[k+8]=p[15-k]; p[15-k]=f; } } /* for(k=0;k<8/2;k++) { f=p[k+(i%2)*8]; p[k+(i%2)*8]=p[8-1-k+(i%2)*8]; p[8-1-k+(i%2)*8]=f; }*/ if(i%2) { p=vram+(y+j)*xsize+x; j++; } } //下半部分 for(i=0;i<16;i++) { for(k=0;k<8;k++) { if(font2[i]&(0x80>>k)) { p[k+(i%2)*8]=c; } } if(i%2==0){ for(k=0;k<4;k++){ f=p[k]; p[k]=p[7-k]; p[7-k]=f; } }else{ for(k=0;k<4;k++){ f=p[k+8]; p[k+8]=p[15-k]; p[15-k]=f; } } /*for(k=0;k<8/2;k++) { f=p[k+(i%2)*8]; p[k+(i%2)*8]=p[8-1-k+(i%2)*8]; p[8-1-k+(i%2)*8]=f; }*/ if(i%2) { p=vram+(y+j)*xsize+x; j++; } } return; }
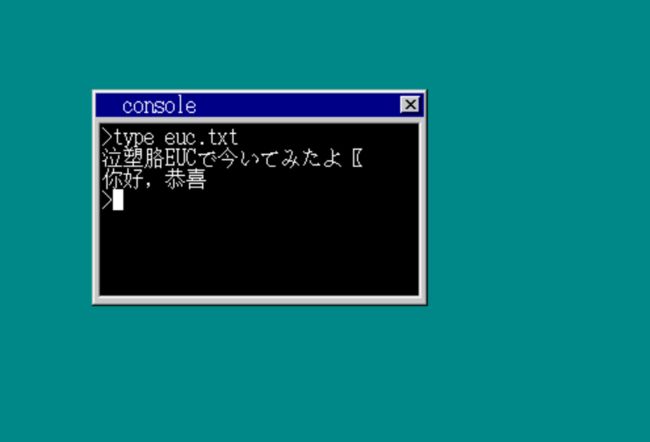
运行结果,我们在euc.txt中加入一些汉字。
参考资料:
1.https://www.cnblogs.com/wunaozai/p/3858473.html 30天操作系统支持中文。