一、寻找函数g的Pocket算法
前文提到,PLA算法有效的前提是D要是线性可分的,D中的数据可以看做由f产生而来。这样的假设过于理想化,现实中,D里面总会掺杂一些噪声数据(noise data),这些数据并不是从理想的f产生而来。
这些噪声数据会带来哪些影响?有了噪声数据,D可能就不是线性可分了,PLA算法也就不再有效,而且,即使D还是线性可分的,噪声数据也会对最后选择的g产生干扰,影响g与f的相似度。
怎么解决噪声数据带来的干扰?
答案是对PLA算法进行改进,不求对D中每一个数据都有g(X)=y=f(X),只求犯错尽可能少的W_g,如下所示:

这个想法貌似不错,很遗憾,找到这样的W_g是一个NP-hard问题,所以我们只能退而求其次,找到一个我们自己感觉犯错足够少的W_g,这样的算法叫做Pocket算法,伪代码如下:

二、反思,机器真的可以学习吗?
现在回顾一下我们目前了解的机器学习的过程:
算法A利用D,从H中挑出一个最好的函数g,使得g尽可能地像f。
再回顾一下PLA和Pocket算法的思路,我们很容易发现一个问题:
我们找函数g的标准是,使它在D上尽可能地像f,可是,我们怎么知道这样的函数g,在D之外的数据上也像f呢?
假如我们用E_in(g)表示

也就是函数g在D上犯错误的比例(与f不一致的比例)。可见,我们目前的算法只是让E_in(g)尽可能地接近0,也就是在D上使g和f很像。
我们用E_out(g)表示在D之外的数据上,g与f不一致的比例。假如我们能够证明E_out(g)与E_in(g)大致相等,又可以使E_in(g)尽可能接近0,也就能够使E_out(g)尽可能地接近0,此时,我们就可以自豪地说,我们找到的函数g确实与f很像!
现在,找最好的函数g实际上包含着两个问题:
- 如何使E_in(g)尽可能小?
- 如何确保E_out(g)与E_in(g)大致相等
PLA和Pocket算法都只专注解决第一个问题,第二个问题怎么解决?答案是用数学来证明。
课程的第4,5,6,7课就是用来证明第二个问题的。本课程一共才16课,竟然用4课来证明一个问题,可见该问题的重要性。
为什么这个问题如此重要?因为只有证明了这个问题,才能从根本上说清楚,为什么机器可以学习,机器学习才能有坚实的理论基础支撑。
通俗地讲,假如你说,我可以用方法A来解决问题B,那么,若要人信服你,仅仅说明怎么用方法A来解决问题B是不够的,你必须证明给别人看,为什么方法A可以解决问题B,我们证明E_out(g)与E_in(g)大致相等就是解决机器学习中为什么的问题。
下面我们简单快速地浏览一下证明过程:
1、从简单的抓弹珠受到的启发
如图所示,
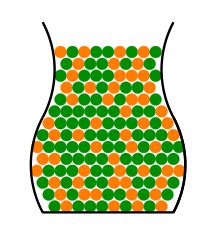
一个罐子里装了许多弹珠,有橙黄和绿两种颜色,如何估计橙黄色弹珠占总弹珠数量的比例μ呢?
统计学告诉我们,可以进行抽样统计,我们可以从里面随手抓一把弹珠出来,统计这把弹珠中橙黄色弹珠所占的比例v,那么v就会近似等于μ,即v≈μ。
当然,如果非常点背,v和μ还是可能相差很多的,例如罐子里只有很少的橙黄色弹珠,可是我们抓的那一把中恰好有很多的橙黄色弹珠。如果出现这种情况,我们称抓到的那把弹珠是BAD的,也就是我们的样本集D是BAD的。
但是数学上可以证明,如果我们只抓一把,这一把弹珠是BAD 的概率会很小,这就是Hoeffding不等式告诉我们的事情:

既然概率很小,我们就可以说,v和μ相等是很可能差不多正确的,注意这个表述,差不多是指v和μ近似相等,很可能是指v和μ近似相等的概率很大。实际上,很可能差不多正确的这一说法被称为PAC(Probably Approximately Corret)。
现在,用专业点的话来讲,我们说v和μ相等是一个PAC表述。
类似的道理,假如我们现在有数据集D,如果在D上,函数g和f很像,那么我们也就可以证明,g和f在所有的数据上也很可能是很像的,不过这里要加一个条件,那就是我们的输入X应当是服从某个分布的随机变量。
但是,正如随手抓一把弹珠可能是BAD的一样,我们的D也可能是BAD的,就是说,有可能我们用算法A挑出的函数g在D上和f确实非常像,但在D之外却与f非常不一样,即E_in(g)很小,但E_out(g)却很大。
显然,如果是这样的话,我们的机器学习就失灵了,因为没法挑出和f很像的g。所幸,对于任意一个函数h,D是BAD的概率同样是很小的,这也是由Hodffding不等式给我们做出的保证。
现在我们的机器学习流程变成了这个样子:
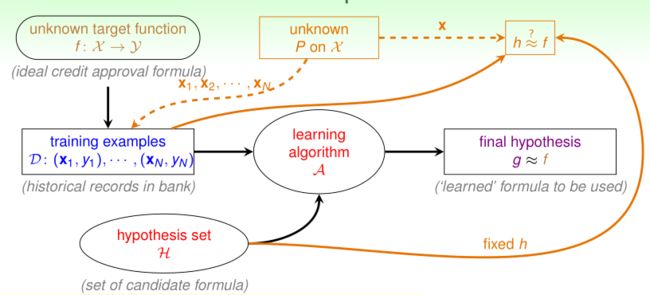
让我们看看这个图,我们的D中的x是从某个分布P中产生的,对于任意一个确定的函数h 如果在D上,h和f非常像,那么我们就可以说,对于一个D之外的x,我们就可以说,h(x)和f(x)相等是一个PAC表述,即它们很大概率上是比较接近的。
现在,你觉得我们的问题解决了吗?好像解决了,但实际上,证明才刚刚开始。
2、H是有限情况下的证明
仔细观察,我们的机器学习算法和抓弹珠估计橙黄色弹珠比例有一个不同的地方。
在抓弹珠中,我们就抓了一把,然后就用它来估计橙黄色弹珠的比例,Hoeffding不等式告诉我们,如果你只抓一把,那么这一把是BAD的概率是很小的。
但在机器学习算法中,我们虽然也是只有一把,即只有一个D,但是我们却有不止一个函数h,我们的H是一个函数的集合,算法正是要从这一个集合中挑出一个和f很像的函数g。类似于抓一把弹珠,对H中的任意一个函数h,D是BAD的概率是很小的,但是对于一个有很多函数的函数集合H,很可能有一个函数b,对它来说D是BAD的,也就是说对函数b来说,它在D上与f很像,但在D之外,却与f大相径庭。
这就好比,让你丢五次硬币,五次全是正面的可能性很小,如果让200个人同时各丢五次硬币,其中有一个人五次全丢正面的可能性就会很大很大,真是上山上多了总会碰到虎,夜路走了总会碰到鬼。
而我们的算法挑选函数g的标准就是看它们谁与f在D上最像,那岂不是很可能会挑中函数b作为最后的g?如果这样的话,机器学习就又失灵了,细思极恐!
怎么破?
既然问题出在H上,我们当然就从H入手,我们把H分成两类,一类是有限的H,一类是无限的H,有限的H就是说里面可供我们挑选的函数数量是有限的,比如只有M个函数。
本着先易后难的原则,我们先解决H中只有M个函数的情形。
此时,如果D对M个函数中任一个函数来说是BAD的,我们就说D对整个H是BAD的,所幸的是,只要M是有限的,D中的样本数量N足够大,这一概率仍然是很小的,证明如下:

由此我们证明了,对于H是有限的情况,我们的算法A最后挑选的函数g与f相等是一个PAC表述。
3、H是无限情况下的证明
更难的问题来了!如果H中有无限数量个函数,岂不是必然有一个函数b,D对它来说是BAD的?
实事求是讲,这个证明是很复杂的,很难简略地说清楚,我也是尽我所能,如果你看不懂,很可能是我没说清,推荐你看林老师的视频,里面讲的极棒。
我们以银行发放信用卡为例,银行中的数据是这样的D:{(x_i,y_i)|x_i
∈d维向量空间,y_i∈{+1,-1}}
x表示用户的个人特征信息向量,是d维的,y为+1表示给这个人发卡后很好,y为-1表示给这个人发卡后很差。为便于分析,这里我们假设d=2。x向量就是这样的
(x1,
x2)
将这些数据可视化,就是这样的:

圈圈表示y = +1,叉叉表示y=-1 。
我们的H中的每个函数就是这个平面上的一条线,如下所示:

我们要找的函数g实际上就是一条将图中的圈圈叉叉完全分开的直线。如上图中右面所示。
回到我们的问题中,现在有一个D,里面的样本数是N,H是无数条直线,我们希望能够证明,D对H来说是BAD的概率很小,这是我们努力的方向。
仔细观察上面的图,我们可以发现,虽然H中直线的数量是无限的,但是其“种类”却是有限的,什么意思?
假设我们只有一个点,这个点非常牛逼,它说:“在我眼中只有两条直线,一条直线把我划为叉叉,一条直线把我划为圈圈。”
是不是很有哲学意味?世界上有多少人?答曰两人,一为男人,一为女人。
假设我们现在有两个点,在这两个点看来,纵然有无数条直线,也不过只有四种,如下所示:

最终我们可以证明,对于N个点来说,直线的种类m(N)是一个关于N的多项式。
至此,虽然H中函数数量是无限的,但函数的种类却可看做N的多项式,对这个种类m(N)稍加变换,就可以用来代替上面H有限情况下的不等式中的M,我们可以得到:

这就是著名的VC-bound不等式,这是一个在机器学习中非常非常重要的公式。
上面的说明实在过于简略,下面我准备用一个图来简单表示课程中的证明过程,可以结合视频进行理解。整个证明以二元线性分类为例进行,但是结论却具有一般性。这是哲学观点共性寓于个性之中的很好体现。

实际上,完整地证明这个公式非常难,课程中也没有给出详细的证明。但这并不妨碍我们对这个公式表达的意义的理解。
下面是一些关于vc dimension的简单结论:
vc dimension是对假设集H的power的衡量,在我们的perceptrons 假设集中,它的vc dimension就是d+1,即模型中参数变量的个数。实际上,在大多数情况下,假设集H的vc dimension与它的模型中参数变量的数量是相等的。从物理的意义上看,这些参数变量代表了模型的自由度,参数变量数量越多,模型的自由度越大,power就会越强,vc dimension自然就会越大。
但是,只要假设集H的vc dimension是一个有限的值,vc bound就可以确保,找到一个函数小g,如果它有较小的E_in,那么它很大概率上也将拥有较小的E_out,即“学习”这件事发生了。