存储系统演变
存储系统一直以来都是一个总的控制器加上几串磁盘扩展柜存在的,但是随着数据量的快速增加,性能受限于控制器,所以要提升整体的处理能力,主要有两种方法:
-
最简单的是在单个控制器中加入更多的CPU、内存等,就如同PC机性能不够了,就加内存、换SSD等。这种扩展方式称为
带内扩展,Scale-up这种方式的问题是,随着CPU数量的增多,耗费的设计成本会越来越大。比如说在多CPU的系统中,我们需要花费大量的精力来保证CPU之间的通信。可见【大话存储】多CPU架构变迁, SMP,NUMA,MPP
-
而多台独立的控制器形成一个集群,他们通过网络将互联起来。这种方式叫
带外升级,Scale-Out不过现在大规模主机集群没有广泛应用于企业中,原因在于集群的
应用程序还没有跟上。我们知道传统的程序主要是运行在单机上的,并没有针对集群进行相应的优化,目前只有一些数据库等系统提供了集群方式的部署,比如Oracle RAC等。另一方面,企业又被主机性能浪费所困扰,又需要部署虚拟机系统
真的是集群也不是,不集群也不是,又催生了更彻底的解决方案——云系统。
好了我们重新回到集群存储系统上来,如果存储系统要做集群,数据分布方式将有两种:
-
将整体数据切分成若干份,然后每一份都分开存储在单个的节点上
这种方式,因为完全由系统自己决定如何切分。如果多个应用系统同时访问,有可能会影响系统整体的性能。
-
手动进行切分,每一份放在独立的节点上。
这种方式需要更多人为干预,但是却可以保证性能资源的合理分配,每个应用系统只访问一个或者若干节点,不影响其他节点的性能。这种方式,相当于在传统架构中为每个应用建立独立的Raid Group一样。
其实一个存储系统最大的问题在于在多主机并发访问时,如何能保证系统的性能,目前主要是通过隔离资源的方法来解决。
所以对于主机而言,只能看到自己的LUN,只是这些LUN是虚拟出来的,可以进行集中管理。
我们可以把集群存储系统分为如下三种:
块存储系统
NAS集群系统
文件系统集群
下面我们将先介绍块存储系统,主要介绍市面上几种典型的产品。

IBM XIV集群存储系统
组成部分
XIV是一种网格集群化存储系统,每个节点都是一台PC Server,每个节点包含12块本地SATA盘,配置是两颗4核的CPU和8GB的内存。
XIV有共有两种类型的节点:Interface Node , Data Node
只有Interface Node上插着FC HBA卡,也就说主机只能连接到Interface Module上。Interface Module本身含有12块SATA硬盘。
Data Node只有12块SATA硬盘以及两块双口千兆以太网卡。
所以这两种节点都可以提供存储空间,只是说Interface Node还可以接前端的主机而已。
下图为集群连接拓扑。

下图为机柜示意图

LUN的分布式设计
集群系统中,LUN被平均分布在多个节点上,也就是说一块逻辑硬盘实际上会拆分成若干份,散落在不同的节点上面。那么我们怎么知道LUN分散到哪里去了呢?这就需要一个映射图来记录每个LUN的分布情况。
为了保证数据块不丢失,每个LUN对应的数据块会镜像一份,而且放到另一个节点上。这样纵然这个节点挂了,还可以根据映射图找到其镜像,然后重新复制一份到剩余空间里面。这种思想就叫多副本机制,我们把源分块称为Primary,镜像分块称为Secondary。
这种思想与NetApp的WAFL文件系统极为类似,实际上高度虚拟化的设备,一般来说,底层的LUN不是存在于固定的位置。比如XIV可以通过映射图来记录LUN在所有节点的存储地址,这就是文件系统的思想,我们知道文件系统是可以通过INode Tree来遍历整个文件的分布情况的。
WAFL和XIV正是对文件系统的基本思想的灵活运用,但是XIV的粒度和元数据复杂度没有WAFL那么细,所以没有沦为一个彻底的文件系统。
所以像XIV这样的块存储系统,对内使用文件系统的基本思想进行LUN的管理,但是对外屏蔽细节,对主机而言是透明的。
如何应对客户端的写IO
当某个Interface Node接收到一个写IO的以后,首先会通过映射表去判断这个写IO会落到哪个节点上以及其镜像又落在哪里。有两种可能,一种是留在Interface Node 上,也可能在Data Node 上。
如果是落在Interface Node本地硬盘中,则会将副本发送到分块镜像所在的Node中。
然后返回成功。如果是放到另外的节点中,则Interface Node重定向这个写IO到该节点中。应该保存Primary分块的节点会再次根据映射表把分片数据复制到副本节点中。
当副本也写入成功了以后,才会向最初的Interface Node返回成功回应。由Inteface Node向客户端返回成功。
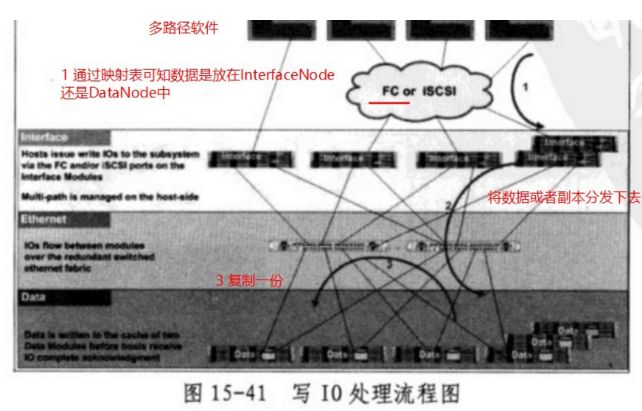
总结一下,就是Interface Node会接收到主机的写IO请求,如果发现是写到自己的内部硬盘上,则复制两份到副本节点上。
如果Inteface Node发现数据是写到其他节点上,则会将写IO重定向到对应的节点上,由该节点复制两份数据到其他节点。当所有的写入都成功了以后,才会向最初的Interface Node返回成功,注意,此时仍由Inteface Node 向主机返回成功,也就意味着,主机其实不知道数据被重定向走了,它仍然以为自己在和此Inteface Node 交互数据呢。
XIV快照设计
我们知道XIV设计也使用了文件系统的思想,所以对于快照,XIV的做法与WAFL差不多,都使用Write Redirect。现在简单的讲一下。
XIV的卷管理模块其实是一个集群文件系统,每个LUN都对应一个分布式映射表(Distribute Map)。
如要要生成快照,可以将这个点数据以及映射表先冻结,然后把映射表复制一份,做为新的活动映射表,之后的针对这个LUN的写IO都会被重定向到空闲数据块上,并把映射表更新。
所以再生成快照就简单了,只需要把活动的映射表复制一份即可,这就是Write Redirect模式。
故障恢复
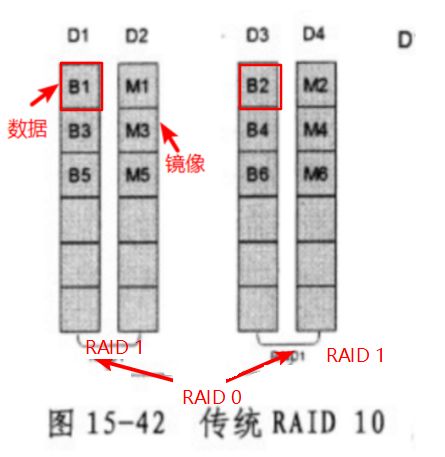
XIV对数据分布的本质思想是分布式RAID 10,相当于将一个LUN复制一份,副本保存在其他位置,这样系统的可用容量相当于减半了,我们可以把这种设计称为上层分布式RAID 10。
那么这种RAID 10的做法与传统的RAID 10有什么区别呢?
我们传统的RAID 10不管底层有没有数据占用,都会将所有数据块镜像起来,浪费了很多空间。这是因为判断有用或者是没有是上层的文件系统来做的,传统的RAID 10根本无法判断,所以只能一股脑的镜像。
XIV相当于一种粗粒度的文件系统,它可以在上层对数据块是否有用进行判断。
下面来具体看看XIV是怎么做:
不需要备份无用的块:XIV卷管理系统相当于一个粗粒度的文件系统,LUN就是它管理的文件,所以它可以感知LUN分块占用了磁盘的哪块空间。也就是说卷管理系统完全可以只镜像部分LUN分块,而无须做其他的无用功。
-
分布式
假设LUN被分为6块数据块,分别标记为B1B6,镜像块为M1M6。
如果D1故障,为了恢复数据的冗余,可以将镜像块M1~M3复制到D3和D4磁盘中。
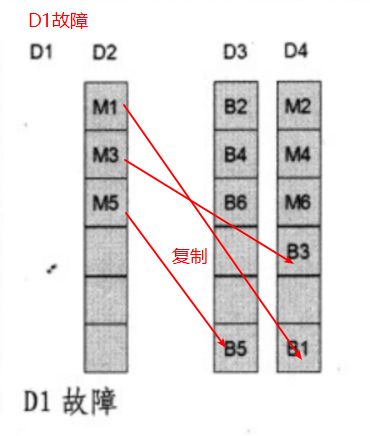
如果D3又故障了,那么数据还是没有丢失,依然继续复制。此时还有冗余性,存在一份副本。
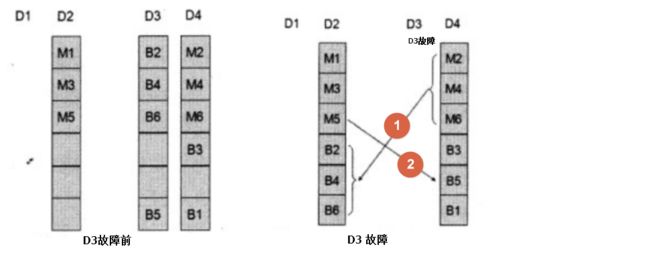
此时如果D2或者D4发生了故障,则没有冗余性了,但是数据仍然没有丢失。
此时如果手动添加了两块硬盘,XIV会重新平衡数据。如下图:
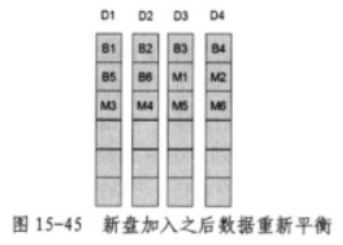
XIV的这种上层RAID 10设计可以随时迁移数据块,并且可以任意分布式摆放数据块,不受磁盘数量限制。只受系统内剩余空间限制。我们把这种模式叫上层分布式RAID 10
那么与传统的RAID 10有什么区别。传统的RAID 10在一块盘故障之后,只能将数据镜像到新盘里面。
目前发布的XIV系统,最大配置为6个Interface Node和9个Data Node,最大磁盘数为1512 = 180块。XIV这种架构设计可以很容易的扩充节点*
XIV优点
下面我们来看一下XIV相对于传统架构有什么优点:
如果此时系统还有剩余的磁盘空间,只要磁盘一块一块的坏下去,整体数据的冗余性可以保持,直到一点空间都没有的时候。当然前提是,当一个磁盘或者节点坏了以后,需要Rebuild,也就是只有在Rebuild以后,才允许再坏一块硬盘,否则有可能数据被损坏。
-
另一个优点在于恢复的速度上,它的Rebuild时间短,一个1TB容量的SATA盘损坏之后,Rebuild时间只有30分钟作用,为什么这么快呢?
- 原因一:XIV使用的是RAID 10的思想,而不是RAID 5。
这样XIV没有校验盘,不需要计算校验值,也不需要把校验值放到其他空间里面,节省了大量计算资源和IO资源。所以XIV的恢复时间比RAID 5快十几倍很正常。
我们可以简单的对比一下。假设有180块硬盘,组成大RAID 5,此时坏了一块盘,系统需要从剩下的盘里面读所有的数据。
若一块盘容量为1TB,内部磁盘环路带宽为4Gb,需要耗费时间(179TB/4Gb)/3600=130.3小时,与XIV的30分钟相比,反差巨大。
还可以与传统的RAID 10对比一下。180块盘组成RAID 10,其中90块数据盘和90块镜像盘,如果一块盘故障,会从对应的镜像盘中读数据。由于是RAID 10,不需要计算XOR等,可以整盘复制,所以是连续读写,可以达到磁盘的最大吞吐。SATA硬盘的理论连续读吞吐量为60MB/s,所以Rebuild时间为(1TB/60MB/s)/3600 = 4.85小时,为XIV的10倍。因为RAID 10需要整盘复制。
- 原因二:分布式。
传统RAID 10中,一块盘坏了,只能从镜像盘中取数据,写到新盘上,也就是一个盘读,一个盘写。
而XIV是将LUN分块平衡存放到多个磁盘上,而这些分块对应的镜像也是存放在多块磁盘。所以XIV在 Rebuild的时候,是从多块盘读,多块盘写,相当于RAID 3,众人拾柴火焰高,恢复速度当然快。
- 原因三:最重要的原因,不做无用功。
Rebuild的时候,只使用了已占用的数据块,而不是整块盘。

3PAR公司Inserv-T800集群存储系统
Inserv-T800为一款x86集群式存储系统。
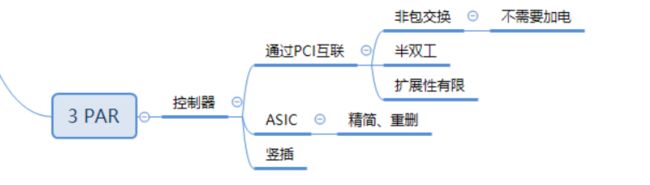
每个节点都是一台x86 Server,整个集群可以由2~8个节点组成。系统所有节点两两直通,每两个节点使用一条独立的100MHz 64b PCI-X总线相连。
比如一个8节点的系统,1个节点需要与另外7个节点互联,所以每个节点都需要7条PCI-X总线连接到背板,形成一个具有28条直通PCI-X的星形结构。
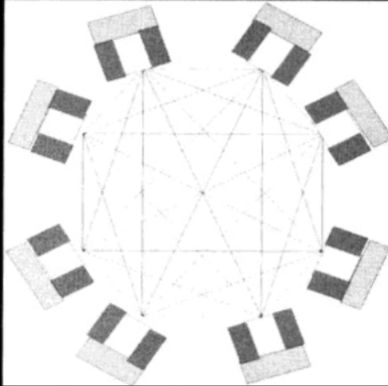
PCI-X是半双工的,所以内部互联带宽为28*800MB/s=21.875GB/s。
不过因为PCI-X并非一种包交换网络传输模式,所以背板不需要加电,是一块布满导线和接口的被动式背板。也正因为此,只用了两个控制器,则只用到一条PCI-X作为互联.
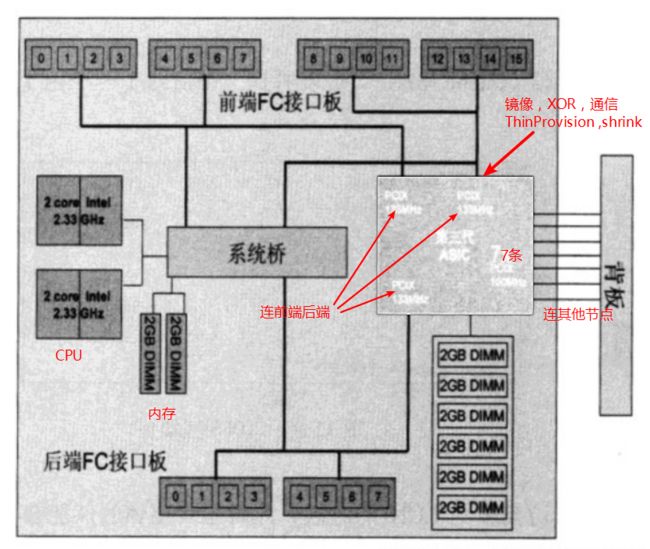
上图为单节点内部的架构,其中ASIC芯片是比较独特的。它将Thin Provision和LUN Shrink功能内嵌到芯片里面来执行。
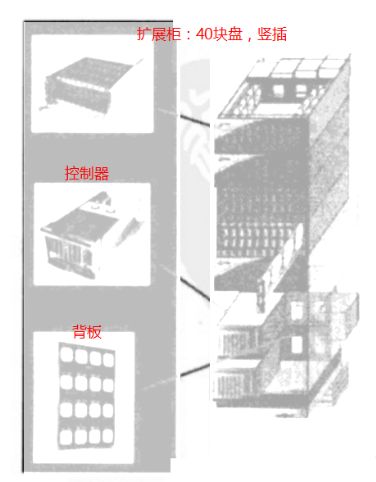
3PAR扩展柜很有特色:在4U的空间放置40块3.5的大盘。因为磁盘可以竖着插而且紧密排列,所以散热和共振的问题也解决了。
特点:
使用直连的PCI-X总线作为节点之间的互联。但是因为使用点对点的互联,而不是使用交换的方式,系统的扩展性很有限
节点内部使用ASIC来实现大部分的数据操作,而且还负载Thin Provision和LUNShrink(Space Reclaiming),降低了CPU的负担。而且扩展柜的高密度设计,减少了空间和连线,降低了耗电。
瓶颈在于每个节点使用3条1GB/s的PCI-X总线来支持6个扩展卡共4Gb/s的FC接口,有些不够。所以系统吞吐量上不去。