论文地址:https://arxiv.org/abs/1605.06409
Github代码:Matlab版,Python版
背景
在Fast R-CNN中,rbg利用 ROI Pooling 解决了不同尺寸 proposal 的特征提取问题,在其升级版 Faster R-CNN 中rbg进一步提出了 RPN 网络,通过共享输入图像的卷积特征,快速生成 proposal。纵观整个 R-CNN 系列的发展过程,我们可以发现,Fast R-CNN中之所以引进 ROI Pooling 是因为网络中全连接层的存在。事实上,一些state of art的图片分类网络均为全卷积网络,如ResNet、GoogLeNet等。所以很自然地,是否可以将目标检测的网络也用全卷积网络来实现?事实证明,如果简单地丢弃全连接层(实现融合特征和特征映射),检测的效果会很差。
作者认为这主要来源于这样的一对矛盾:
图像分类:要求图像具有平移不变性(translation invariance)
目标检测:要求图像具有位置敏感性(translation variance)
Region based Fully Convolutional Network(R-FCN)的提出即是为了解决这样的一对矛盾,R-FCN中的一个关键层是位置敏感ROI池化层(position-sensitive RoI pooling layer)。
R-FCN结构

首先来看一下R-FCN的网络结构。和Faster R-CNN一样,R-FCN也是 基于region proposal的两级检测架构。
“对于region-based的检测方法,以Faster R-CNN为例,实际上是分成了几个subnetwork,第一个用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast RCNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork和前两个subnetwork中间的就是ROI pooling。我们希望的是,耗时的卷积都尽量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91层共享,插入ROI pooling,后10层不共享)策略不同,本文把所有的101层都放在了前面共享的subnetwork。最后用来prediction的卷积只有1层,大大减少了计算量。”

R-FCN 首先也是一个RPN的网络,用于生成和训练proposal(ROI)。所不同的是,Faster R-CNN中,ROI Pooling层直接对ROI进行分块池化输出用于分类和回归的特征向量。
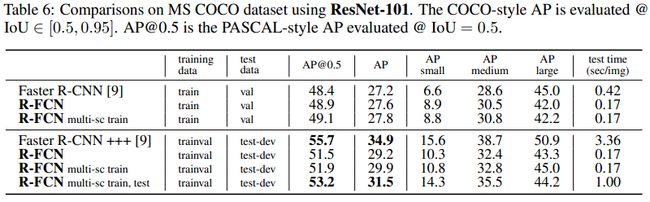
R-FCN中,则将每一个ROI划分成k×k个格,池化输出每个格的位置得分,再通过投票方式得到 ROI 最后的输出特征向量。的首先生成 k^2(C+1) 通道大小的输出。其中,C 为类别数(+1为背景), k^2 表示将ROI区域划分成 k×k个格,如上图所示。如 k=3,则对应9个格,分别为上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角),如下图所示:

Backbone网络:ResNet101——去除原始网络最后的平均池化层和全连接层,保留100层的卷积层用于特征提取。为了降维,100层卷积层之后又添加了一层1×1×1024的卷积层,使输出维度变成1024(原始的是2048)。之后再接一层卷积层用于产生得分图。
位置敏感得分图&位置敏感ROI Pooling:将w×h大小的ROI划分成k×k个格(大小 ≈ \frac{w}{k}×\frac{h}{k})。对每个格进行位置敏感池化操作,如下式:
r(i,j|Θ) = \sum_{(x,y)∈bin(i,j)}^{}z_i,_j,_c(x+x_0,y+y_0|Θ)/n
式中,r(i,j|Θ)是第(i,j)个格的池化响应;z_i,_j,_c表示k^2(C+1) 中的一个得分图;(x_0,y_0)表示ROI左上角的格。
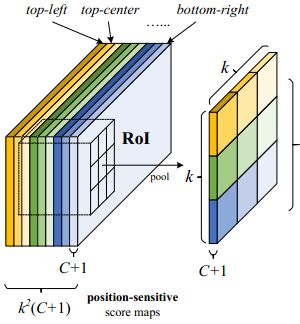
k^2个得分图通过投票(eg.求均值)后得到ROI上 C+1 维的输出向量。后接一个softmax层得到每一类的最终得分,并在训练时计算损失,如下图。
ROI的位置回归:R-FCN的位置回归方式与R-CNN和Fast R-CNN相似。上面说到,在base网络的 feature map 之后连接了一层卷积用于产生k^2(C+1)维的位置敏感得分图。此处仍然从base网络上连接一个 4k^2 通道的得分图(与位置敏感得分图并列),用来做 ROI 的坐标微调。同样对这个 4k^2 大小的得分图进行 ROI Pooling操作,输出 t=(t_x, t_y, t_w, t_h) 大小的 4 维坐标向量。
训练的相关细节:损失函数与Fast RCNN相似,分类部分为交叉熵损失,回归部分为平滑L1损失,总的损失为这两部分的和:
L(s, t_{x, y, w, h}) = L_{cls}(s_{c^*}) + \lambda[c^* > 0]L_{reg}(t, t^*)
- IoU大于0.5的ROI被当做正样本,其余作为负样本
- 采用单尺度训练,尺度大小为600像素(min(w, h))。每张图片通过OHEM选取128个hard example做反向传播
- 分别用学习率为0.001,20k次迭代;学习率为0.0001,10k次迭代在VOC数据集上做微调
- 采用类似Faster R-CNN中的4步训练策略交替训练RPN网络和R-FCN网络
推理部分:与Faster R-CNN等类似,采用阈值0.7的NMS进行非极大值抑制。
À trous卷积和stride调整:R-FCN调整了部分卷积核的stride大小(conv4及之前的保持stride=16,conv5的stride由2变为1)。同时,conv5上的卷积采用À trous卷积(空洞卷积),补偿减小stride带来的影响。
实验结果
VOC数据集
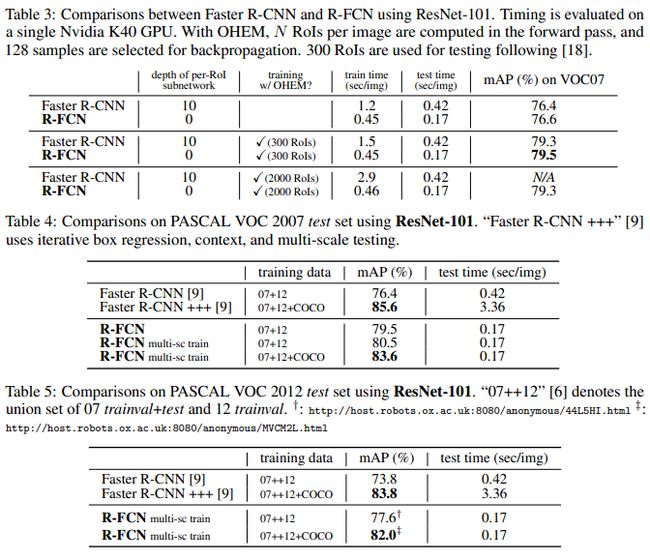
1. 与Faster R-CNN的对比
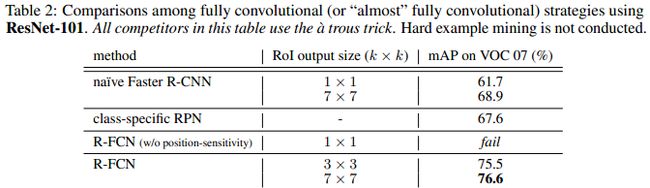
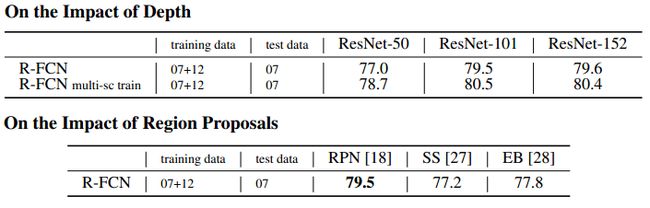
2. ResNet深度、ROI生成策略的影响
COCO数据集