概述
RDD作为Spark对各种数据计算模型的同一抽象,被用于迭代计算过程以及任务结果的缓存读写。在MR模型中,shuffle是map到reduce的中间桥梁。经过map标记后,shuffle负责分发到各个reducer上。如果有大量数据需要shuffle,shuffle决定了整个计算引擎的性能和吞吐量。
MappedRDD的iterator方法实际调用父类RDD的iterator方法
/**
* RDD的内部方法;如果有缓存将读取缓存,若没有缓存则计算。
* 用户不应该直接调用此方法,但是可以用于字定义他的子类实现。
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
如果没有缓存调用computeOrReadCheckpoint
/**
* Compute an RDD partition or read it from a checkpoint if the RDD is checkpointing.
*/
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointedAndMaterialized) {
//存在检查点时直接获取中间结果
firstParent[T].iterator(split, context)
} else {
compute(split, context)
}
}
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
* 子类去实现计算分区数
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
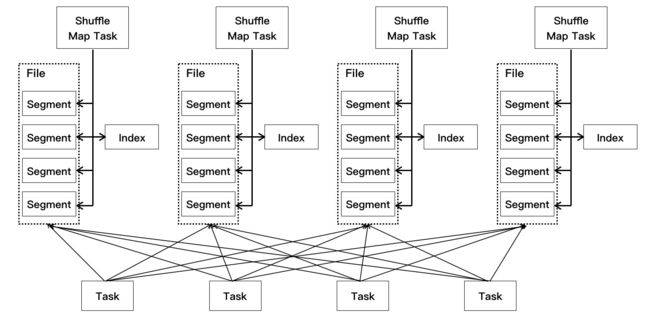
每个Shuffle Map Task不会为后续的每个任务创建单独的文件,而是会将所有结果写到同一个文件中,对应生成一个Index文件进行索引。通过这种机制避免了大量文件的产生,一方面可以减轻文件系统管理众多文件的压力, 另一方面可以减少Writer Handler的缓存所占用的内存大小,节省了内存的同时避免了GC的风险和频率。如图:
接下来我们以hadoopRDD为例子看看实现的compute方法
override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {
//匿名内部类
val iter = new NextIterator[(K, V)] {
private val split = theSplit.asInstanceOf[HadoopPartition]
logInfo("Input split: " + split.inputSplit)
//从broadcast种获取JobConf 正是HadoopConfiguration
private val jobConf = getJobConf()
//用于计算字节读取的测量信息
private val inputMetrics = context.taskMetrics().inputMetrics
private val existingBytesRead = inputMetrics.bytesRead
// Sets InputFileBlockHolder for the file block's information
split.inputSplit.value match {
case fs: FileSplit =>
InputFileBlockHolder.set(fs.getPath.toString, fs.getStart, fs.getLength)
case _ =>
InputFileBlockHolder.unset()
}
// Find a function that will return the FileSystem bytes read by this thread. Do this before
// creating RecordReader, because RecordReader's constructor might read some bytes
private val getBytesReadCallback: Option[() => Long] = split.inputSplit.value match {
case _: FileSplit | _: CombineFileSplit =>
Some(SparkHadoopUtil.get.getFSBytesReadOnThreadCallback())
case _ => None
}
// We get our input bytes from thread-local Hadoop FileSystem statistics.
// If we do a coalesce, however, we are likely to compute multiple partitions in the same
// task and in the same thread, in which case we need to avoid override values written by
// previous partitions (SPARK-13071).
private def updateBytesRead(): Unit = {
getBytesReadCallback.foreach { getBytesRead =>
inputMetrics.setBytesRead(existingBytesRead + getBytesRead())
}
}
private var reader: RecordReader[K, V] = null
//获取TextInputFormat
private val inputFormat = getInputFormat(jobConf)
//添加hadoop相关配置,关于本地化等等。
HadoopRDD.addLocalConfiguration(
new SimpleDateFormat("yyyyMMddHHmmss", Locale.US).format(createTime),
context.stageId, theSplit.index, context.attemptNumber, jobConf)
reader =
try {
inputFormat.getRecordReader(split.inputSplit.value, jobConf, Reporter.NULL)
} catch {
case e: IOException if ignoreCorruptFiles =>
logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e)
finished = true
null
}
// Register an on-task-completion callback to close the input stream.
context.addTaskCompletionListener { context =>
// Update the bytes read before closing is to make sure lingering bytesRead statistics in
// this thread get correctly added.
updateBytesRead()
closeIfNeeded()
}
//得到LongWritable
private val key: K = if (reader == null) null.asInstanceOf[K] else reader.createKey()
//得到Text
private val value: V = if (reader == null) null.asInstanceOf[V] else reader.createValue()
override def getNext(): (K, V) = {
try {
finished = !reader.next(key, value)
} catch {
case e: IOException if ignoreCorruptFiles =>
logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e)
finished = true
}
if (!finished) {
inputMetrics.incRecordsRead(1)
}
if (inputMetrics.recordsRead % SparkHadoopUtil.UPDATE_INPUT_METRICS_INTERVAL_RECORDS == 0) {
updateBytesRead()
}
(key, value)
}
override def close(): Unit = {
if (reader != null) {
InputFileBlockHolder.unset()
try {
reader.close()
} catch {
case e: Exception =>
if (!ShutdownHookManager.inShutdown()) {
logWarning("Exception in RecordReader.close()", e)
}
} finally {
reader = null
}
if (getBytesReadCallback.isDefined) {
updateBytesRead()
} else if (split.inputSplit.value.isInstanceOf[FileSplit] ||
split.inputSplit.value.isInstanceOf[CombineFileSplit]) {
// If we can't get the bytes read from the FS stats, fall back to the split size,
// which may be inaccurate.
try {
inputMetrics.incBytesRead(split.inputSplit.value.getLength)
} catch {
case e: java.io.IOException =>
logWarning("Unable to get input size to set InputMetrics for task", e)
}
}
}
}
}
//最后封装为InterruptibleIterator 此类只是对NextIterator的代理
new InterruptibleIterator[(K, V)](context, iter)
}
根据工具查询调用栈发现ShuffleMapTask
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
接着调用SortShuffleWriter的write方法
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
//创建ExternalSorter 将计算结果写入缓存中
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
//获取当前任务输出路径
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
//创建blockId
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
//将中间结果持久化
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
//创建索引文件
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
//创建MapStatus
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
SparkShuffle性能优化
1.将map任务给每个partition的reduce任务输出的bucket合并到同一文件中,这样解决额bucket数量很多但是本身数据体积不大时照成shuffle频繁磁盘io成为性能瓶颈。
2.map任务逐条计算出计算结果,而不是一次性输出到内存,使用AppendOnlyMap缓存及其聚合算法对中间结果进行聚合,这大大减少了中间结果说占用内存大小。
3.对SizeTrackingAppendOnlyMap和SizeTrackingPairBuffer等缓存进行溢出判断,当超出myMemoryThreshold的大小,将数据写入磁盘,防止内存溢出。
4.reduce任务对拉取到的map任务中间结果逐条读取,而不是一次性读取,进行聚合和排序,本质也使用了AppendOnlyMap缓存。大大减少内存开销。
5.reduce任务将要拉去的Block按照BlockManager地址划分,将同一地中中的block累积为少量网络请求减少I/O。
在ExternalSorter的insterAll方法中,先判断是否需要进行聚合(Aggregation),如果需要,则根据键值进行合并(Combine), 然后把这些数据写入到内存缓冲区中,如果排序中Map占用的内存超过了阈值,则将Map中的内容溢写到磁盘中,每一次溢写产生一个不同的文件。如果不需要聚合,把数据排序写到内存缓冲区
shuffle读操作
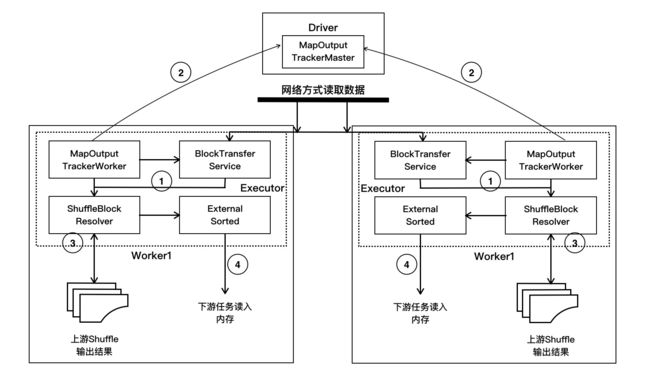
1.在SparkEnv启动时,对shufflemanage,blockmanager和mapoutputtracker等实例化,shufflemanager配置项有sortshufflemanager和字定义shufflemanager两种,SortShuffleManager实例化BlockStoreShuffleReader,持有的实例是IndexShuffleBlockResolver实例。
- 在BlockStoreShuffleReader的read方法中,调用mapOutputTracker的getMapSizesByExecutorId方法,由Executor的MapOutputTrackerWorker发送获取结果状态的
GetMapOutputStatuses消息给Driver端的MapOutputTrackerMaster,请求获取上游Shuffle输出结果对应的MapStatus,其中存放了结果数据信息,也就是我们之前在作业执行源码分析中介绍的ShuffleMapTask执行结果元信息。 - 知道Shuffle结果的位置信息后,对这些位置进行筛选,判断是从本地还是远程获取这些数据。如果是本地直接调用BlockManager的getBlockData方法,在读取数据的时候会根据写入方式的不同采取不同的ShuffleBlockResolver读取;如果是在远程节点上,需要通过Netty网络方式读取数据。
在远程读取的时候会采用多线程的方式进行读取,一般来说,会启动5个线程到5个节点进行读取数据,每次请求的数据大小不回超过系统设置的1/5,该大小由spark.reducer.maxSizeInFlight配置项进行设置,默认情况该配置为48MB。 - 读取数据后,判断ShuffleDependency是否定义聚合(Aggregation), 如果需要,则根据键值进行聚合。在上游ShuffleMapTask已经做了合并,则在合并数据的基础上做键值聚合。待数据处理完毕后,使用外部排序(ExternalSorter)对数据进行排序并放入存储中。
读操作从shuffleRDD的compute说起
/**
* ResultTask或者ShuffleMapTask在执行到shuffleRDD时调用compute方法来计算partition的数据
* @param split
* @param context
* @return
*/
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
//获取Reader(BlockStoreShuffleReader),拉取shuffleMapTask/ResultTask,需要聚合的数据
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
1.在BlockStoreShuffleReader的read方法里先实例化ShuffleBlockFetcherIterator,在该实例化过程中,通过MapOutputTracker的getMapSizeByExecutorId获取上游ShuffleMapTask输出的元数据。先尝试在本地的mapStatus获取,如果获取不到,则通过RPC通行框架,发送消息给MapOutputTrackerMaster,
请求获取该ShuffleMapTask输出数据的元数据,获取这些元数据转换成Seq[(BlockManagerId, Seq[(BlockId, Long)])]的序列。在这个序列中的元素包括两部分信息,BlockManagerId可以定位数据所处的Executor,而Seq[(BlockId,Long)]可以定位Executor的数据块编号和获取数据的大小。
override def read(): Iterator[Product2[K, C]] = {
// ShuffleBlockFetcherIterator根据得到的地理位置信息,通过BlockManager去远程的
// ShuffleMapTask所在节点的blockManager去拉取数据
val blockFetcherItr = new ShuffleBlockFetcherIterator(context,blockManager.shuffleClient,blockManager,
// 通过MapOutputTracker获取上游的ShuffleMapTask输出数据的元数据,
// 先尝试从本地获取,获取不到,通过RPC发送消息给MapOutputTrackerMaster,获取元数据
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
...
}
在MapOutputTracker的getMapSizesByExecutorId方法代码如下:
def getMapSizesByExecutorId(shuffleId: Int, startPartition: Int, endPartition: Int)
: Seq[(BlockManagerId, Seq[(BlockId, Long)])] = {
logDebug(s"Fetching outputs for shuffle $shuffleId, partitions $startPartition-$endPartition")
// 通过shuffleId获取上游ShuffleMapTask输出数据的元数据
val statuses = getStatuses(shuffleId)
// Synchronize on the returned array because, on the driver, it gets mutated in place
// 使用同步的方式把获取到的MapStatuses转为Seq[(BlockManagerId, Seq[(BlockId, Long)])]格式
statuses.synchronized {
return MapOutputTracker.convertMapStatuses(shuffleId, startPartition, endPartition, statuses)
}
}
getStatus(shuffleId)方法如下:
private def getStatuses(shuffleId: Int): Array[MapStatus] = {
// 先尝试在本地读取
val statuses = mapStatuses.get(shuffleId).orNull
if (statuses == null) {
logInfo("Don't have map outputs for shuffle " + shuffleId + ", fetching them")
val startTime = System.currentTimeMillis
var fetchedStatuses: Array[MapStatus] = null
fetching.synchronized {
// Someone else is fetching it; wait for them to be done
// 如果其他人也在读取消息,等待其他人读取完毕后再进行读取
while (fetching.contains(shuffleId)) {
try {
fetching.wait()
} catch {
case e: InterruptedException =>
}
}
// Either while we waited the fetch happened successfully, or
// someone fetched it in between the get and the fetching.synchronized.
fetchedStatuses = mapStatuses.get(shuffleId).orNull
if (fetchedStatuses == null) {
// We have to do the fetch, get others to wait for us.
fetching += shuffleId
}
}
if (fetchedStatuses == null) {
// We won the race to fetch the statuses; do so
logInfo("Doing the fetch; tracker endpoint = " + trackerEndpoint)
// This try-finally prevents hangs due to timeouts:
try {
// 发送消息给MapOutputTrackerMaster,获取该ShuffleMapTask输出的元数据
val fetchedBytes = askTracker[Array[Byte]](GetMapOutputStatuses(shuffleId))
// 对获取的元数据进行反序列化
fetchedStatuses = MapOutputTracker.deserializeMapStatuses(fetchedBytes)
logInfo("Got the output locations")
mapStatuses.put(shuffleId, fetchedStatuses)
} finally {...}
...
}
1.获取读取数据位置信息后,返回到ShuffleBlockFetcherIterator的initalize方法,该方法是Shuffle读的核心代码所在。
private[this] def initialize(): Unit = {
// Add a task completion callback (called in both success case and failure case) to cleanup.
context.addTaskCompletionListener(_ => cleanup())
// Split local and remote blocks. 切分本地和远程block
// 对获取数据位置的元数据进行分区,区分为本地节点还是远程节点
val remoteRequests = splitLocalRemoteBlocks()
// Add the remote requests into our queue in a random order
fetchRequests ++= Utils.randomize(remoteRequests)
assert ((0 == reqsInFlight) == (0 == bytesInFlight),
"expected reqsInFlight = 0 but found reqsInFlight = " + reqsInFlight +
", expected bytesInFlight = 0 but found bytesInFlight = " + bytesInFlight)
// Send out initial requests for blocks, up to our maxBytesInFlight
// 对于远程节点数据,使用Netty网络方式读取
fetchUpToMaxBytes()
val numFetches = remoteRequests.size - fetchRequests.size
logInfo("Started " + numFetches + " remote fetches in" + Utils.getUsedTimeMs(startTime))
// Get Local Blocks
// 对于本地数据,sort Based Shuffle使用的是IndexShuffleBlockResolver的getBlockData方法获取数据
fetchLocalBlocks()
logDebug("Got local blocks in " + Utils.getUsedTimeMs(startTime))
}
划分本地节点还是远程节点的splitLocalRemoteBlocks方法中划分数据读取方式:
private[this] def splitLocalRemoteBlocks(): ArrayBuffer[FetchRequest] = {
// 设置每次请求的大小不超过maxBytesInFlight的1/5,该阈值由spark.reducer.maxSizeInFlight配置,默认48MB
val targetRequestSize = math.max(maxBytesInFlight / 5, 1L)
logDebug("maxBytesInFlight: " + maxBytesInFlight + ", targetRequestSize: " + targetRequestSize)
// Split local and remote blocks. Remote blocks are further split into FetchRequests of size
// at most maxBytesInFlight in order to limit the amount of data in flight.
val remoteRequests = new ArrayBuffer[FetchRequest]
// Tracks total number of blocks (including zero sized blocks)
var totalBlocks = 0
for ((address, blockInfos) <- blocksByAddress) {
totalBlocks += blockInfos.size
if (address.executorId == blockManager.blockManagerId.executorId) {
// 当数据和所在BlockManager在一个节点时,把该信息加入到localBlocks列表中,
// 需要过滤大小为0的数据块
localBlocks ++= blockInfos.filter(_._2 != 0).map(_._1)
numBlocksToFetch += localBlocks.size
} else {
val iterator = blockInfos.iterator
var curRequestSize = 0L
var curBlocks = new ArrayBuffer[(BlockId, Long)]
while (iterator.hasNext) {
val (blockId, size) = iterator.next()
// 对于不空数据块,把其信息加入到列表中
if (size > 0) {
curBlocks += ((blockId, size))
remoteBlocks += blockId
numBlocksToFetch += 1
curRequestSize += size
} else if (size < 0) {
throw new BlockException(blockId, "Negative block size " + size)
}
// 按照不大于maxBytesInFlight的标准,把这些需要处理数据组合在一起
if (curRequestSize >= targetRequestSize) {
// Add this FetchRequest
remoteRequests += new FetchRequest(address, curBlocks)
curBlocks = new ArrayBuffer[(BlockId, Long)]
logDebug(s"Creating fetch request of $curRequestSize at $address")
curRequestSize = 0
}
}
// 剩余的处理数据组成一次请求
if (curBlocks.nonEmpty) {
remoteRequests += new FetchRequest(address, curBlocks)
}
}
}
logInfo(s"Getting $numBlocksToFetch non-empty blocks out of $totalBlocks blocks")
remoteRequests
}
数据读取完毕后,回到BlockStoreShuffleReader的read方法,判断是否定义聚合,如果需要,则根据键值调用Aggregator的combineCombinersByKey
方法进行聚合。聚合完毕,使用外部排序(ExternalSorter)对数据进行排序并放入内存中
override def read(): Iterator[Product2[K, C]] = {
...
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// 对于上游ShuffleMapTask已经合并的,对合并结果数据进行聚合
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// 对未合并的数据进行聚合处理,注意对比类型一个是C一个是Nothing
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}
// Sort the output if there is a sort ordering defined.
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
// 对于需要排序,使用ExternalSorter进行排序,根据获取的排序方式,对数据进行排序并写入到内存缓冲区中。
// 如果排序中的Map占用的内存已经超越了使用的阈值,则将Map中的内容溢写到磁盘
val sorter =
new ExternalSorter[K, C, C](context, ordering = Some(keyOrd), serializer = dep.serializer)
sorter.insertAll(aggregatedIter)
context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)
CompletionIterator[Product2[K, C], Iterator[Product2[K, C]]](sorter.iterator, sorter.stop())
case None =>
aggregatedIter
}
}