决策树原理介绍
决策树是用样本的属性作为结点,用属性的取值作为分支的树结构,是通过一系列规则对数据进行分类的过程,它提供一种在什么条件下会得到什么值的类似规则的方法。决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。下图是一个相亲时候的决策图,女方根据男方的条件来决定是否见面(仅为解释)。

决策树的构造
一棵决策树的生成过程主要分为以下3个部分:
- 特征选择
特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,比如相亲时要根据男方的一系列特征[年龄,长相,收入,是否公务员]来决定见不见面,特征选择就是每次选择哪个特征才能得到一个最好的决策结果。如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。 - 决策树生成
根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 - 剪枝
决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
在构造决策树时,需要解决的第一个问题是,当前数据集上那个特征在划分数据分类时起决定作用。为找到决定性的特征,划分出最好的结果,需要评估每个特征。当根据第一个特征进行数据划分后,原始数据集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,则该分支无需继续划分。如果数据子集内的数据不属于同一类型则需要根据新的特征继续划分。
创建分支的伪代码如下:
def create_branch():
根据数据集中的每个子项是否属于同一分类:
if so:
return 类标签
else:
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集:
create_branch()
return 分支节点
信息熵
每次划分数据集时如何选择合适的特征才能产生最优的划分结果,可以用信息熵来评估。在概率论中,信息熵给了我们一种度量不确定性的方式,是用来衡量随机变量不确定性的,熵就是信息的期望值。若待分类的事物可能划分在N类中,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:
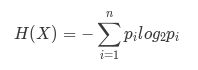
熵越高就表明数据越混乱,不确定性越高。
举个例子,掷一枚筛子的结果的信息熵
划分数据集的最大原则是:将无序的数据变得更加有序。划分数据集前后信息熵发生的变化叫做信息增益,信息增益是熵的减少或数据无序度的减少,获得信息增益最高的特征就是最好的选择。
Gain(A) = Info(D) - Info(D-a)
使用特征a进行划分后的信息增益 =(原始数据的信息熵)-(使用特征a进行划分后得到的新数据集的信息熵)。
划分数据集
有了信息熵的概念,我们就可以依此来选择特征划分数据集了。具体过程是遍历数据集的每个特征,用每个特征的不同值去划分数据集,计算信息增益。最后返回信息增益最大的那个特征。
递归构建决策树
得到原始数据集,基于最好特征划分一次数据集。第一次划分后,数据将被向下传递到树分支的下一节点,在这个节点熵再次划分数据。递归结束的条件是程序遍历完所有属性或者每个分之下的所有实力都属于同一分类。
代码实现
生成如下数据集
|id| 年龄 | 长相 | 收入 | 公务员 | 是否见面 |
| ------------- |:-------------:| -----:|
|1| <30 | 帅 | 低 |是| no |
|2| <30 | 丑 | 高 |否| no |
|3| <30 | 帅 | 中等 |是| yes |
|4| >30 | 帅 | 高 |否| no |
|5| <30 | 丑 | 低 |是| no |
|6| <30 | 帅 | 低 |否| no |
|7| <30 | 帅 | 高 |否| yes |
|8| <30 | 帅 | 中等 |否| no |
|9| >30 | 帅 | 中等 |是| no |
|10| <30 | 丑 | 中等 |是| no |
from math import log
# 构造数据集
def createDataSet():
dataSet = [
[1, 1, 0, 1, 'no'],
[1, 0, 2, 0, 'no'],
[1, 1, 1, 1, 'yes'],
[0, 1, 2, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 0, 0, 'no'],
[1, 1, 2, 0, 'yes'],
[1, 1, 1, 0, 'no'],
[0, 1, 1, 1, 'no'],
[1, 0, 1, 1, 'no'],
]
labels = ['年龄','长相','收入','公务员']
return dataSet, labels
# 计算香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
# 统计数据集中每个分类的数量
for featVec in dataSet:
currentLabel = featVec[-1]
labelCounts[currentLabel] = labelCounts.get(currentLabel, 0) + 1
shannonEnt = 0.0
# 计算每个分类的熵,然后就和得到整个数据集的熵
for key in labelCounts:
prob = float(labelCounts[key])/numEntries # 每个分类的数量/总数据集的数量=每个分类的概率
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
# 划分数据集,根据每个特征的不同值把整个数据集划分为多个数据子集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 用第i个特征的一个value划分一次数据集得到一个数据子集,计算该数据子集的熵
# 对每个value划分得到的数据子集的熵就和得到用该特征划分数据集后的熵
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 # 最后一列是标签
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): # 遍历每个特征
featList = [example[i] for example in dataSet] # 所有数据的第i个特征
uniqueVals = set(featList) # 对特征值去重
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value) # 用第i个特征的一个value来划分数据集
prob = len(subDataSet)/float(len(dataSet)) # 第i个特征等于value的个数/整个数据集的数量
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #用第i个特征进行数据划分后的信息增益
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature
# 返回类别中数量最多的那个分类
def majorityCnt(classList):
classCount={}
for vote in classList:
classCount[vote] = classCount.get(vote, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]# 类别完全相同则停止划分
if len(dataSet[0]) == 1: # 遍历完所有特征时返回出现次数最多的
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
if __name__ == '__main__':
dataSet, labels = createDataSet()
tree = createTree(dataSet, labels)
print(tree)
{'收入': {0: 'no', 1: {'年龄': {0: 'no', 1: {'长相': {0: 'no', 1: {'公务员': {0: 'no', 1: 'yes'}}}}}}, 2: {'年龄': {0: 'no', 1: {'长相': {0: 'no', 1: 'yes'}}}}}}
# 根据决策树来构建分类器
def classify(inputTree, featLabels, testVec):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else:
classLabel = secondDict[key]
return classLabel
# 测试
labels = ['年龄','长相','收入','公务员']
label = classify(tree, labels, [1, 0, 1, 1])
print(label)
no
# 用pickle模块存储决策树
def storeTree(inputTree,filename):
import pickle
fw = open(filename,'wb')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename, 'rb')
return pickle.load(fr)
storeTree(tree, '决策树.txt')
dt = grabTree('决策树.txt')
print(dt)
{'收入': {0: 'no', 1: {'年龄': {0: 'no', 1: {'长相': {0: 'no', 1: {'公务员': {0: 'no', 1: 'yes'}}}}}}, 2: {'年龄': {0: 'no', 1: {'长相': {0: 'no', 1: 'yes'}}}}}}
- 原文:
http://jlan.me/2017/05/04/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B9%8B%E5%86%B3%E7%AD%96%E6%A0%91%E7%AE%97%E6%B3%95/ - 详细代码:
https://github.com/jllan/machine-lernning-case/tree/master/decision_tree