最近开始刷 VLDB 2019 中感兴趣的 paper, 今天开始第一篇: 来自阿里云的分析性数据库 AnalyticDB
由于这是一个云厂商的商业产品, 因此写之前还是事先说明一下: 我没有用过阿里云的 AnalyticsDB 产品以及 Paper 中提到的相关产品例如 AWS 的 Redshift 和 Google 的 BigQuery; 本文中所有的观点仅代表个人, 如有不对的地方, 还请指正.
什么是 AnalyticDB
AnalyticsDB(下文简称 ADB)是一个 OLAP 数据库, 对标类似的产品是 AWS 的 Redshift/Google 的 BigQuery 或者开源的 Druid/Pinot
架构
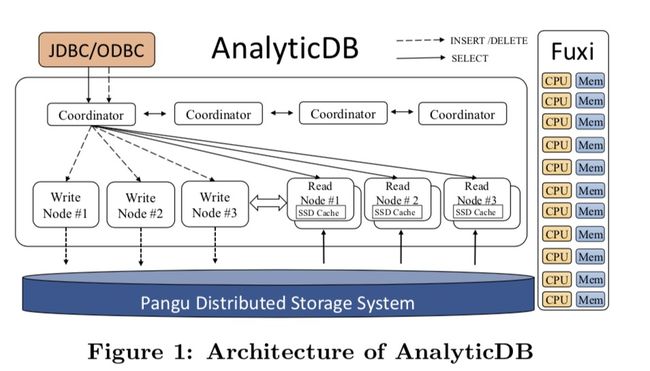
ADB 的一个优势是可以实时更新数据, 因此在设计上将读写节点做了分离:
- 写请求直接通过 Coordinator 路由到 Writer Node, 最终数据落盘到 Pangu(阿里云的分布式文件系统
- 数据写入到一定程度后, 启动 MapReduce 任务将数据合并成最终的数据文件
架构上来说个人认为一个大的亮点是虽然整体的数据库引擎是自研的, 但 ADB 却选择了支持 MySQL 和 PostgreSQL 两种协议, 直接享受了 MySQL 和 PostgreSQL 两个数据库相关的生态优势.
数据写入流程
第一个 Writer Node 启动后, 会作为 Master 分派后续的 Writer Worker Node. 当一个 Write 请求到达 Coordinator 后, Coordinator 先解析写入请求的 SQL 后在分配写入的节点. Writer Node 写入一定数据后再刷盘到 Pangu.
疑问 1: 如果在中途 Writer Node 停机, 是不是没有刷盘到 Pangu 的数据就丢失了?
疑问 2: 所有的写请求都通过单一的 Coordinator 做路由转发, 如果写入请求非常多(例如 paper 中提到的
handle tens of millions of online write requests per second), Coordinator 会不会成为瓶颈?
数据读取流程
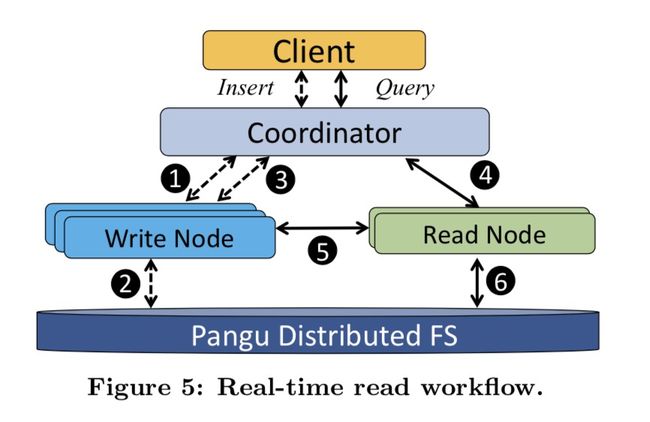
由于 ADB 的 table 是分区的, 因此具体数据的放置就可以实现 Storage-aware Query Optimizer.

Reader Node 启动时会从 Pangu 拉取数据文件, 因此猜测 Reader Node 还是会通过本地盘的方式加速查询的. 实时读取时, Reader Node 会时不时从 Writer Node 拉取最新的增量数据. Reader Node 也可以设置 replication factor 来提升 concurrency 和 reliability. 每个 Reader Node
都会分别从 Writer Node 获取最新的增量数据.
疑问 3: Reader Node 是间隔多少时间拉取 Writer Node 的数据的? 这期间岂不是根本查询不到增量写入的数据? 多个 Reader Node replica 获取并构建增量数据索引, 会不会导致不同 replica 在某些情况下数据不一致(拉取增量有快有慢)?
集群管理
除了使用 Fuxi 做基础计算资源的申请外, ADB 里面还有一个 Gallardo 服务做资源分配, 据称是为了多个 ADB instance 之间采用 Control Group 做隔离.
疑问 4: 这个 Gallardo 有必要吗? 难道不是直接从 Fuxi 申请物计算资源就可以吗? 是多个 ADB instance 共用 Fuxi 分配的一台计算节点的?
存储
数据存储设计
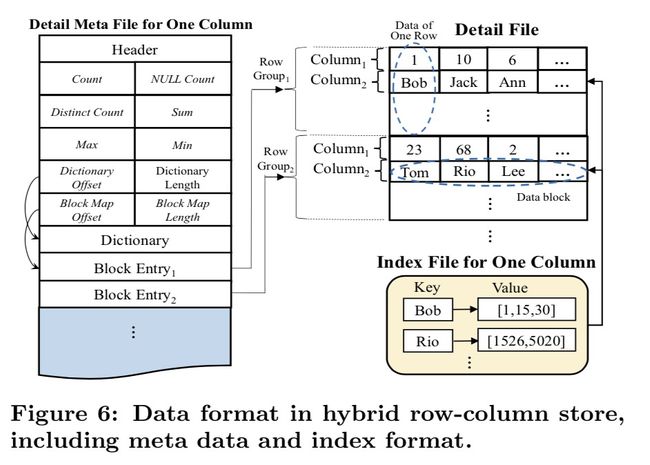
ADB 设计了自己的存储文件格式(Hybrid Row-Column Store):
- Table 的一个 partition 中所有的数据是一个文件, 称之为 Detail File
- 为了解决单纯 Column Store 对 Point Query 性能问题, 数据被划分成多个 Row Group.每个 Row Group 中有固定数量的 column, 同样的column 的数据被组织到同一个 data block.
疑问 5: 说实话, 我没看懂为啥这个 Hybrid Row-Column Store 能够同时对 OLAP 和 Point lookup 查询都有优势.
疑问 6: 如果数据量非常大而 Partition 数据量有不是足够多(比如 100TB 数据的 Table 只有 100 个 Partition), 岂不是单个 Detail 文件会很大? 这样设计在移步构建索引的时候岂不是降低了任务的并发度? 还是说构建索引的后台任务可以使用 RowGroup 切分 Detail File 提升任务并发度?
数据查询
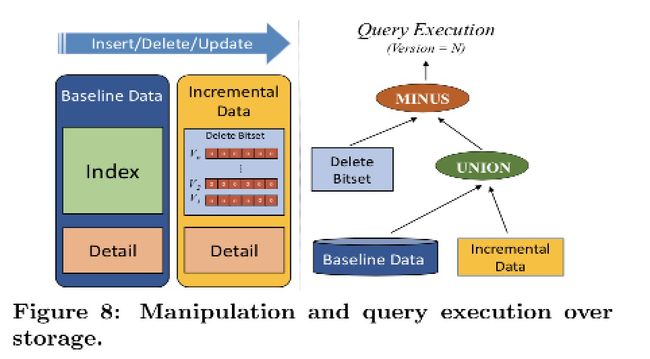
由于有数据频繁更新的场景, 因此 ADB 在数据查询上采用的是 Lambda 架构:
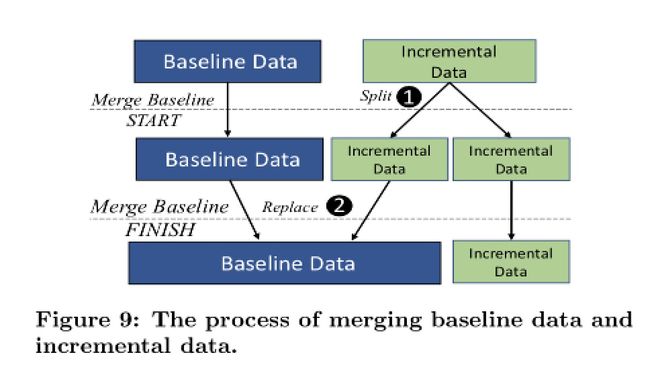
- 将 Baseline 数据和 Incremental 数据进行合并
- 对于删除的场景, 通过 Bitset 判断
- 由于增量数据查询只有 sorted index, 对比 Baseline data 索引有很大差距, 定期会进行 Incremental 数据合并.
索引设计
索引是所有的数据库系统提升性能的法宝. ADB 也设计了自己的索引. 简单总结几个我能看懂的点吧:
- ADB 的索引是将所有的 column 都索引的, 包括复杂的数据类型
- 由于索引多, 索引路径选择也有优化空间. ADB 通过 filter ratio 来自动决定索引路径, 进一步提升性能
- 对比 Greenplum, 1TB 数据文件情况下, ADB 仅仅使用 0.66TB 索引空间, 而 Greenplum 需要 2.7TB 索引存储空间
- 常规数据库都是在写入时更新索引,因此会影响一定的写入性能. ADB 使用后台任务在 Merge 数据的时候构建索引, 避免了这个问题, 提升了写入性能.
- 增量数据也是有索引的, 使用了一个 sorted index 设计, 并且索引是在 Reader Node 上构建的, 非常轻量级.

Optimizer
OLAP 数据库的查询优化器肯定是非常关键的. 可惜我在这个领域了解是在不多. 感兴趣的自己去看吧, 我就不瞎 BB 了.
测试结果
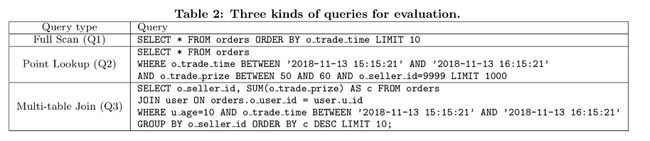
Paper 中给出了三个测试查询(SQL 见上图), 一共有三种类型:
- Q1: 全表扫描查询数据, 并且有全局的
ORDER BY操作 - Q2: 根据
o_trade_timeo_trade_priceseller_id三个过滤条 - Q3:
JOINGROUP BYORDER BY和聚合计算SUM操作的查询. 应该算三个里面最复杂的.
跟着对比的是 PrestoDB, SparkSQL, Druid 和 Greenplum
1TB 数据查询 Latency

从上图可以看出, 整体的 latency ADB 都是在 1s 内返回的, 即便是 Q3 这种复杂的查询. 注意 Y 坐标轴的刻度和单位(秒).
10TB 数据查询 Latency
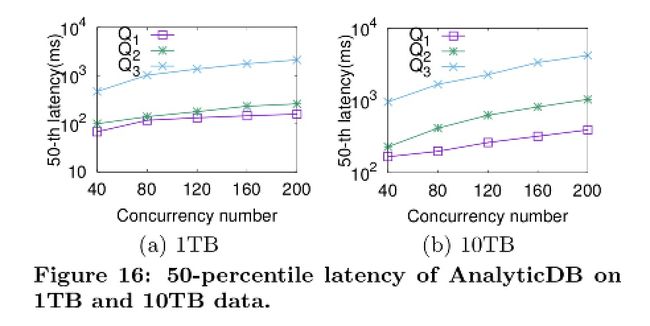
当数据量增长到 10TB 时, 查询 P50 latency 依旧影响不太大, 结果见上图. 不过不知道为啥没有贴出 P95 的数据, 毕竟 P95 更有说服力吧.
写入性能
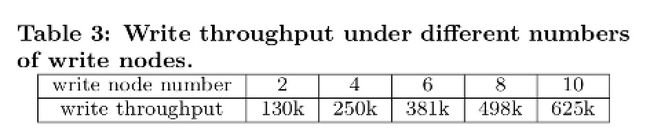
可以看出, 基本上写入性能是跟着 Writer Node 数量线性增长的.
TPC-H 对比
TPC-H 的查询就比上面 Paper 中自己定义的三个 Query 复杂多了, 例如 TPC-H Q7 的查询如下:
select
supp_nation,
cust_nation,
l_year, sum(volume) as revenue
from (
select
n1.n_name as supp_nation,
n2.n_name as cust_nation,
extract(year from l_shipdate) as l_year,
l_extendedprice * (1 - l_discount) as volume
from
supplier,
lineitem,
orders,
customer,
nation n1,
nation n2
where
s_suppkey = l_suppkey
and o_orderkey = l_orderkey
and c_custkey = o_custkey
and s_nationkey = n1.n_nationkey
and c_nationkey = n2.n_nationkey
and (
(n1.n_name = '[NATION1]' and n2.n_name = '[NATION2]')
or (n1.n_name = '[NATION2]' and n2.n_name = '[NATION1]')
)
and l_shipdate between date '1995-01-01' and date '1996-12-31'
) as shipping
group by
supp_nation,
cust_nation,
l_year
order by
supp_nation,
cust_nation,
l_year;
感兴趣的可以自己去看看 TPC-H 规范
ADB 的 TPC-H 结果如下图(注意 Y 轴), 可以看出优势还是很明显, 超过 10 秒的查询都没有几个.

总结
从架构上来说, ADB 走的是 shared-storage 的路线, 大体架构跟 Azure SQL 数仓和当红炸子鸡 Snowflake 架构类似, 都是采用"无状态" 的节点实现数仓横向扩展的, 本质上说跟 Redshift 还是不一样. 对 Cloud Data Warehousing 感兴趣的同学也强烈建议去看 大神 Dr David DeWitt 的演讲: Data Warehousing in the Cloud
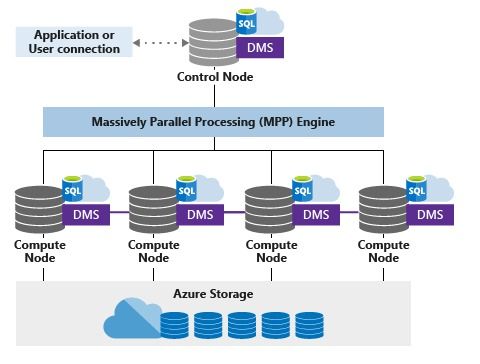
- 来源: Azure 官网文档

- 来源: Snowflake 官网文档
疑问 7: 从 Azure SQL 和 Snowflake 的架构图看, 二者都是采用云服务的 Object Storage 作为 shared-storage 架构中的 Storage 选型的, 那么为何 ADB 没有直接使用 OSS 而是选择了 Pangu?
个人认为, ADB 这个架构设计上最大的亮点就是既然都徒手撸了一个 OLAP 数据库了, 还选择了支持 MySQL 和 PostgreSQL 两种最为广泛的协议, 而不是安耐不住自己设计了一个协议然后再苦哈哈的去构建所谓的生态. 原因很简单: MySQL 协议和 PostgreSQL 协议应该算是这个领域使用最为广泛的, 支持这两种协议, 用户就可以有大量的生态体系中的工具或则其他产品整合, 大为降低了 ADB 的使用门槛. 反观 Snowflake, 几乎是为主流语言都开发了 SDK, 也不知道这满满一屏幕的产品是如何被 Snowflake 拿下的.
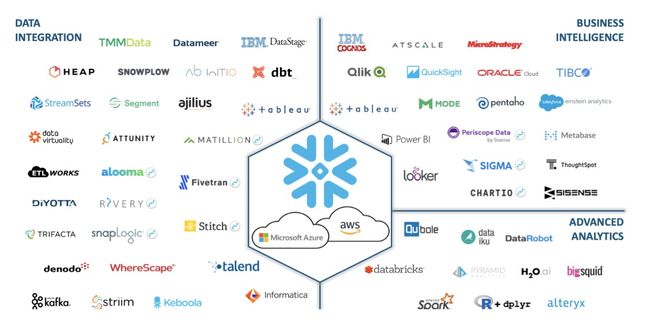

Reference:
- ADB 官网文档: https://help.aliyun.com/product/92664.html
- Snowflake 文档: https://docs.snowflake.net/manuals/user-guide/intro-key-concepts.html#query-processing
- Azure SQL 数据仓库架构介绍: https://docs.microsoft.com/zh-cn/azure/sql-data-warehouse/massively-parallel-processing-mpp-architecture
- VLDB 2019 Industrial Track Papers: https://vldb.org/2019/?papers-industrial
- TPC-H 规范: http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-h_v2.18.0.pdf