
一、 任务目标
- Develop a k-NN classifier with Euclidean distance and simple voting
- Perform 5-fold cross validation, find out which k performs the best (in terms of accuracy)
- Use PCA to reduce the dimensionality to 6, then perform 2) again. Does PCA improve the accuracy?
- Explore the data before classification using summary statistics or visualization
- Pre-process the data (such as denoising, normalization, feature selection, …)
- Try other distance metrics or distance-based voting
- Try other dimensionality reduction methods
- How to set the k value, if not using cross validation? Verify your idea
二、 数据集介绍
Wine Date Set
Abstract:Using chemical analysis determine the origin of wines

更多细节见:http://archive.ics.uci.edu/ml/datasets/Wine
三、 实验过程
1)加载数据,求各个统计量
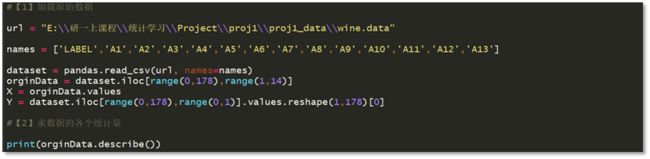
read_csv()函数说明:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html。
第一个参数为本地数据库的绝对路径; 第二个参数代表 List of column names to use,即数据集中各列的名称。
Describe()函数说明: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.core.groupby.DataFrameGroupBy.describe.html
返回数据集的每个特征的各个统计量。实验结果如图3-2所示.

2)数据可视化:画箱线图

利用 pandas.DataFrame.plot()函数实现: https://pandas.pydata.org/pandasdocs/stable/generated/pandas.DataFrame.plot.html?highlight=plot
各参数含义如下:
Kind:plot 图的类型
Subplots: Make separate subplots for each column, 即为每列创建一个子图;
Layout: (rows, columns) for the layout of subplots;
Sharex/sharey: 指示各子图是否共用同一坐标系;
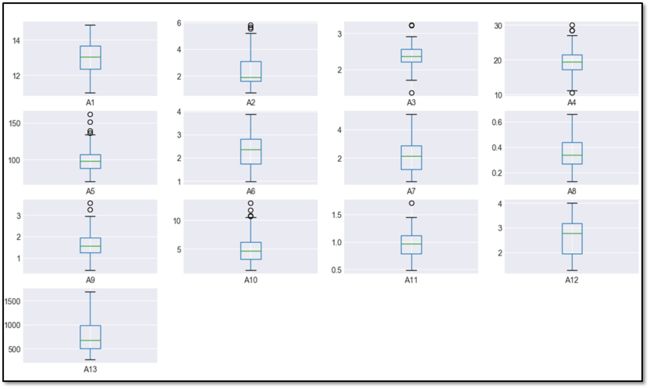
3)数据清洗和特征标准化
利用箱线图,我们可以轻易发现离群点(图3-4中黑色圆圈点)。利用图3-5中的代码可将离群点的值打印出来。

对离群点,我们可将其视为缺失值,并用前后点的平均值代替。表3-1列出了所有离群点以及相应的修正值。

我们采用均值方差归一化算法,可以利用sklearn库中的StandardScaler函数实现,详见:
http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html

4)分割数据集

利用sklearn库中的 train_test_split可以方便地将数据集随机划分成指定比例的训练集和测试集:
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
X_n: 标准化的后的数集 ;
y_n :数据标签,注意必须为一维数组,由于从dataset转化来的y_n为二维array:
[[y0,y1..]] ,所以取array[0]转化成一维arrray;
test_size :测试集默认为数据集样本数量的0.25;
random-state:随机数种子.
5)建立KNN模型(基于欧式距离和简单投票)

http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
利用KNeighborsClassifier****(n_neighbors=5, weights=’uniform’)**建立KNN分类器:
n_neighbors: 指定“近邻”的数量,默认为5;
weights: 是否进行基于距离的加权投票,默认设为uniform,等权加权;如果设置为distance,则以距离倒数为权重进行投票,此时离
中心样本更近的邻居对分类结果有更大的影响。
利用score(X, y) Returns the mean accuracy on the given test data and labels.
实验结果: 分类准确率为1.0
6)利用5折交叉验证寻找最佳K值

利用sklearn中的cross_val_score函数进行交叉验证,各参数含义为:
knn: 待验证的基础分类器。每次迭代过程中,向cross_val_score传递不同K值 的KNN分类器。
X_n,y_n:数据集和标签集;
Cv: 指定k-交叉验证的k值;
关于KNN 分类器中K值的选取,体现了bias_variance_trade-off观点:
K值过小,模型复杂度上升,容易发生过拟合;
K值过大,模型过于简单,容易发生欠拟合,若K=N(数据集大小),对于输入实例,将简单地预测它属于训练实例中最多的类。
K值选取的经验方法:一般取训练数集大小的平方根,且取奇数。在本实验中,K经验值取13
7)将步骤6的实验结果进行可视化,选取最佳K值
我们取k=[1,3,5,7,9,11,13,15,17,19,21]中的不同值,将平均准确率进行可视化,见图3-10所示。
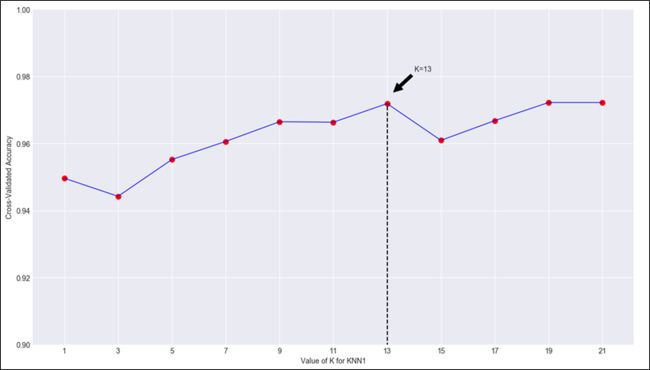
随着K值从1开始逐渐增大,准确率渐渐提升。在K=13时达到峰值,随后下降再上升,可以预计当K大于一定阈值后,准确率将再度下降。如前所示,K值选取不宜过大或过小,最佳K值应该在13附近。
从上述分析知,本实验最佳K值等于13,此时准确率为0.972.
8)使用距离加权投票训练KNN,重复步骤6,7
训练距离加权的KNN,只要将KneighborsClassifier中的weight参数设置为‘distance’即可。
knn = KNeighborsClassifier(n_neighbors = k,weights = 'distance')
其他代码不变,实验结果如图3-11所示。

对照图3-10和3-11知,两类的KNN的随近邻数K值变化的准确率走势基本一致。加权KNN的最佳K值亦是13,准确率为0.972.
9)对数据进行PCA降维,重复步骤6,7

可以调用 scikit_learn 库中的 PCA函数实现目的:
http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
Pca=PCA(n_component=6)含义:设置保留主成分个数为 6.
newData=pca.fit_transform(X)含义:用 X_n来训练 PCA 模型,同时返回降维后的数据。
为什么要进行特征降维?原因之一是去冗余,更重要的原因是:在高维空间下,样本将变得稀疏,相同K值,高维度空间比低维度空间需要更多训练样本。当维度趋于无穷,距离度量失去意义(维度灾难)。基于距离计算的模型如Kmeans ,KNN,维度过高时会影响精度和性能。
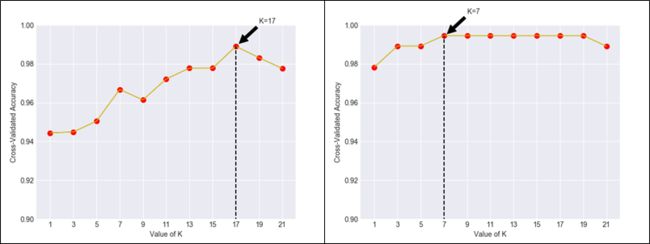
对降维后的数据训练KNN,重复步骤6和7,实验结果如图3-13所示。
由左图可以看出,进行PCA将维后,当K=17时,取得最高准确率0.989,准确率提高了一个百分点。
10)对数据进行LDA降维,重复步骤6,7

可以调用 scikit_learn 库中的LinearDiscriminantAnalysis()函数实现目的:
http://scikit-learn.org/stable/modules/generated/sklearn.discriminant_analysis.LinearDiscriminantAnalysis.html
LDA=LinearDiscriminantAnalysis() 含义:返回一个LDA分类器
newData=LDA.fit_transform(X) 含义:用 X_n来训练LDA模型,同时返回降维后的数据。
注意:对N维数据,数据类别数为C,则LDA降维后数据维度为C-1,与N无关。在本实验中,降维后的数据维度为2.
对降维后的数据训练KNN,重复步骤6,7,实验结果如图3-13所示。
由右图可以看出,进行LDA将维后,当K=7时,取到最高准确率0.995,相较PCA,准确率提高了一个百分点.
11)利用BAGGING法寻找最佳K值
除了K折交叉验证法,我们还可以利用委员会算法寻找最佳K值。Bagging 是其代表,其基本思想是:
i.对一个单独数据集,利用bootstrap(放回抽样)产生M个自助数据集。
ii.对每一个K值,我们利用这M个自助数据集训练M个独立模型
iii.对每一个实例,委员会预测为M个独立模型的平均值。
我们可以利用sklearn库中的BaggingClassifier()函数实现目的,参考:
http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html

代码中各参数含义为:
KneighborsClassifier(n_neighbors = k) : 指定委员会的基础分类器;
max_samples: 每个自助集占原始数据集的最大比例;
n_estimator: 指定委员会成员数量。
Bootstrap: 若为true,则进行放回抽样。
图3-15 给出了利用bagging算法衡量不同k值下的KNN分类器准确率曲线图。

我们发现K=1时,取到最高准确率。这是因为K=1时,模型方差很大,但是加和求平均后偏置很小,从而产生了预测效果的提升。在K>5后,曲线趋于平缓,说明模型偏置和方差得到了相对平衡。利用bagging算法,我们选取K=7,此时准确率为0.983.
四、 实验总结

针对KNN算法,我们有以下几点结论,这些结论在本文第二部分中均得到具体阐述。
特征归一化至关重要,目的是使各项特征对距离计算的贡献度保持一致。
基于距离加权的KNN与普通投票的KNN分类效果相差不大。
当数据维度过高时,特征降维是提升KNN分类器性能的必要手段,在本实验中LDA优于PCA。
可以利用Bagging算法代替k-fold验证法寻找最佳K值。
