本文章作为Java NIO 一书的读书笔记
并且参考jenkov大神的Blog: http://tutorials.jenkov.com/java-nio/buffers.html
关于NIO的概念,在上一篇文章中有基本的介绍。在jdk7中引入了一个java.nio包, 主要分为以下
- java.nio (Buffer相关的类)
- java.nio.channels (Channel相关的类)
- java.nio.charset (字符集)
- java.nio.file (对文件的操作 Files, Paths等)
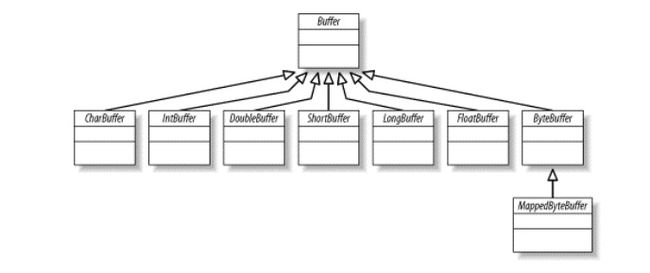
Buffer
一个缓冲区对象是固定数量的数据的容器,每个非bool的原始类型均对应了一个缓冲区。它和Channel一起工作进行I/O操作,Channel是I/O发生时数据的通道,而Buffer则是数据的来源或者目标。
下图说明了Buffer类以及相关子类的关系-----------------2.1
属性
容量(Capacity)
缓冲区能够容纳的数据元素的最大数量。这一容量在缓冲区创建时被设定,并且永远不能被改变。
上界(Limit)
缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。
位置(Position)
下一个要被读或写的元素的索引。位置会自动由相应的get()和put()函数更新。
标记(Mark)
一个备忘位置。调用mark()来设定mark = postion。调用reset()设定position = mark。标记在设定前是未定义的(undefined, int mark = -1) 。
这4个属性总是满足以下关系
0 <= mark <= position <= limit <= capacity
新创建的Buffer大致如下-----------------2.2

存取
上面提到的position属性在调用put()时指出下一个元素应该存放的位置, 在调用get()时指出下一个元素应当从何处进行检索。
由于不同子类的存取的参数类型和返回类型均不同,所以get和put不存在顶层Buffer,而是存在于各个子类当中。
我们使用ByteBuffer举例
存储
buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
当我们调用5次put方法以后,缓冲区由上图变为如下-----------------2.3

我们还可以指定从某一位进行put
buffer.put(0,(byte)'M').put((byte)'w');
这会将第一位变为'M',并且继续往后存储一个'w'
缓冲区变更如下----------------- 2.4
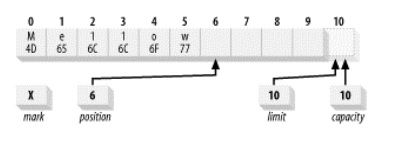
翻转
当我们想从Buffer中读取数据,假如我们什么都不做,直接使用get()进行读取的话,position的位置指向为空,get出来的东西也就为空。
我们需要使用flip()函数,将缓冲区的读写状态进行翻转,然后再读取数据。
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
翻转后的缓冲区如下----------------- 2.5

position变为0,从0开始读取数据,limit变为原来的postion的值,可以获取Buffer中已存数据的上限。这时再使用get便可以从Buffer中读取数据。
连续使用两次flip会使position=limit=0,使得这个Buffer的大小变为0。
rewind不会改变limit,只会将position置为0, mark置为-1, 一般用于在读的过程中需要从头重新读取。
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
读取
我们可以使用get()获取Buffer中position位置对应的元素,与此同时,position会+1。需要注意的是Buffer并不是线程安全的,多线程中需要自己进行线程同步。
hasRemaining方法则用来进行判定我们是否还可以从Buffer中读取数据。
下面代码是一种获取buffer中数据的方式。
for (int i = 0; buffer.hasRemaining( ), i++) {
myByteArray [i] = buffer.get( );
}
clear和 compact
当我们需要使Buffer准备好可写入时,我们可以使用clear或者compact
clear()会将buffer置为初始状态(刚allocate), position置为0,limit置为capacity,mark置为-1(丢弃标记)。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
clear方法通常用在使用chanel-read或者put来向buffer中存放数据之前。比如:
buf.clear(); // Prepare buffer for reading
in.read(buf); // Read data
clear并没有将Buffer中的数据清除掉,只是将Buffer的4个属性置为初始状态。如果Buffer中有未读取到的数据,clear以后则数据不可读。
如果Buffer中有未读数据,我们需要在后续进行读取,但是在这以前需要先写入一部分数据,那么就需要使用compact而不是clear。
compact()会将Buffer进行压缩, 将[position,limit)区间的数据拷贝到Buffer起始位置[0,limit-position),然后将limit置为capacity, position则指向之前拷贝数据的后一个位置。此时,我们可以从position位置开始写入数据而不会覆盖掉之前的未读数据。
有部分未读数据----------------- 2.6
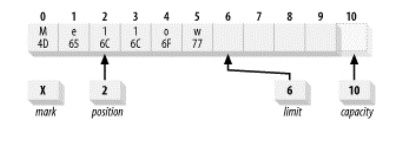
compact
压缩后的Buffer----------------- 2.7
mark和 reset
mark用于记住某个位置,在初始时为-1 (未标记)。当调用mark()以后,mark值置为position,记录当前position的位置。
而reset()则会将position置为mark的值。如果mark为-1则会抛出InvalidMarkException。
而之前所说的clear,flip,rewind均会清除标记
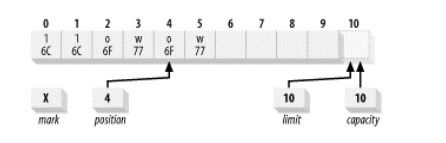
下面代码将mark设置为2,然后position设置为4
buffer.position(2).mark().position(4);
将mark设置为2----------------- 2.8
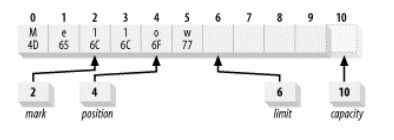
调用reset----------------- 2.9

equals和 compareTo
equals方法用来判断两个Buffer是否相等, 相等的条件如下
- 他们有同样的类型,一个ByteBuffer不会跟其他Buffer或者其他Object相等
- 他们remaining()相等(拥有相同个数的元素),这里无须考虑capacity是否相等,position和limit是否均相等,只需要limit-position相等即可
- 他们从position到limit这一段数据中,依次get()出来的数据是否相等。
相等的Buffer----------------- 2.10

不等的Buffer----------------- 2.11
compareTo则用于以字典顺序比较两个Buffer,返回1/0/-1,这使得Buffer数组可以使用Arrays.sort进行排序。
compareTo同样只允许同种Buffer进行比较。
BufferA在以下两种情况均认为比BufferB小
- BufferA中的对应位置的值比BufferB小, 比如 A[1,2,3,5,7], B[1,2,4,6] -- A中第三位3小于B中第三位4
- 当A,B对应位置的值都相等的时候,A的长度比B的小,比如 A[1,2,3], B[1,2,3,1]
allocate 和 wrap
allocate创建一个缓冲区对象并分配一个私有的空间来储存容量大小的数据元素。
分配一个能容纳100个char变量的Buffer,这段代码隐含地从堆空间中分配了一个char型数组作为备份存储器来储存100个char变量。
CharBuffer charBuffer = CharBuffer.allocate (100);
wrap创建一个缓冲区对象但是不分配任何空间来储存数据元素。它使用您所提供的数组作为存储空间来储存缓冲区中的数据元素
char [] myArray = new char [100]; CharBuffer charbuffer = CharBuffer.wrap (myArray);
- hasArray告诉Buffer是否拥有一个wrap的数组
- array返回这个数组的引用
- arrayOffset返回数组的偏移量(数组第一个元素存储在Buffer中的位置)
duplicate, asReadOnlyBuffer和 slice
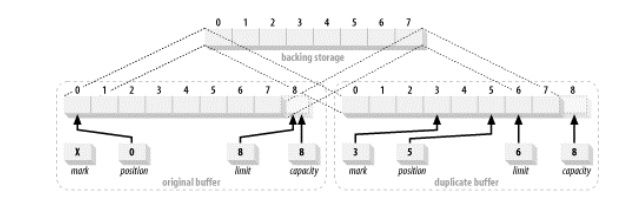
duplicate会新建一个Buffer, 和当前Buffer共享同一数据,但是其他的mark,position,limit均不会相互影响。新Buffer还会继承原有Buffer isReadOnly, isDirect这两个属性
public ByteBuffer duplicate() {
return new HeapByteBuffer(hb, --当前buffer的数组
this.markValue(),
this.position(),
this.limit(),
this.capacity(),
offset);
}
CharBuffer buffer = CharBuffer.allocate (8);
buffer.position (3).limit (6).mark( ).position (5);
CharBuffer dupeBuffer = buffer.duplicate( );
buffer.clear( );
复制Buffer----------------- 2.12
asReadOnlyBuffer则会创建一个readOnly的Buffer(不能put),和原Buffer共享数据。
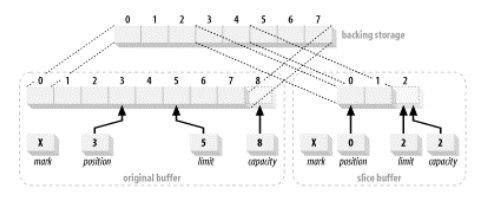
slice则创建一个以当前Buffer position起, 容量为剩余元素数量(limit-position)的Buffer, 同时和原有Buffer共享一部分数据。
CharBuffer buffer = CharBuffer.allocate (8);
buffer.position (3).limit (5);
CharBuffer sliceBuffer = buffer.slice( );
分割Buffer----------------- 2.13
ByteBuffer
所有的基本数据类型都有相应的缓冲区类(布尔型除外),但字节缓冲区有自己的独特之处。字节是操作系统及其I/O设备使用的基本数据类型。
字节顺序
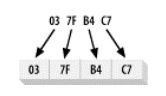
BIG_ENDIAN: 数字数值的最高字节 - big end(大端),位于低位地址,那么系统就是大端字节顺序。
BE----------------- 2.14
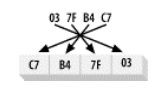
LITTLE_ENDIAN: 最低字节最先保存在内存中
LE----------------- 2.15
字节顺序一般取决于硬件设计,在IP协议中我们规定了使用BE。而在ByteOrder有3种顺序:
- BIG_ENDIAN
- LITTLE_ENDIAN
- nativeOrder (return Bits.byteOrder())
ByteBuffer的默认顺序是BE。
直接Buffer
操作系统的在内存区域中进行I/O操作。这些内存区域,就操作系统方面而言,是相连的字节序列。。直接缓冲区被用于与通道和固有I/O例程交互。它们通过使用固有代码来告知操作系统直接释放或填充内存区域。
直接字节缓冲区通常是I/O操作最好的选择。在设计方面,它们支持JVM可用的最高效I/O机制。非直接字节缓冲区可以被传递给通道,但是这样可能导致性能损耗。通常非直接缓冲不可能成为一个本地I/O操作的目标。如果您向一个通道中传递一个非直接ByteBuffer对象用于写入,通道可能会在每次调用中隐含地进行下面的操作:
- 创建一个临时的直接ByteBuffer对象。
- 将非直接缓冲区的内容复制到临时缓冲中。
- 使用临时缓冲区执行低层次I/O操作。
- 临时缓冲区对象离开作用域,并最终成为被回收的无用数据。
这可能导致缓冲区在每个I/O上复制并产生大量对象,而这种事都是我们极力避免的。
直接缓冲区是I/O的最佳选择,但可能比创建非直接缓冲区要花费更高的成本。直接缓冲区使用的内存是通过调用本地操作系统方面的代码分配的,绕过了标准JVM堆栈。建立和销毁直接缓冲区会明显比具有堆栈的缓冲区更加破费,这取决于主操作系统以及JVM实现。直接缓冲区的内存区域不受无用存储单元收集支配,因为它们位于标准JVM堆栈之外。
ByteBuffer.allocateDirect()函数会分配一段直接内存。虽然ByteBuffer是唯一可以被直接分配的类型,但如果基础缓冲区是一个直接ByteBuffer,对于非字节视图缓冲区,isDirect()可以是true。
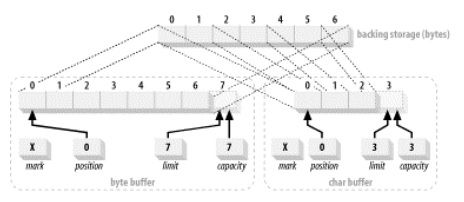
Buffer视图
I/O基本上可以归结成组字节数据的四处传递。在进行大数据量的I/O操作时,很又可能您会使用各种ByteBuffer类去读取文件内容,接收来自网络连接的数据,等等。一旦数据到达了您的ByteBuffer,您就需要查看它以决定怎么做或者在将它发送出去之前对它进行一些操作。ByteBuffer类提供了丰富的API来创建视图缓冲区。
ByteBuffer类允许创建视图来将byte型缓冲区字节数据映射为其它的原始数据类型。
下面代码为ByteBuffer创建了一个CharBuffer的视图
ByteBuffer byteBuffer = ByteBuffer.allocate (7).order (ByteOrder.BIG_ENDIAN);
CharBuffer charBuffer = byteBuffer.asCharBuffer( );
一个ByteBuffer的CharBuffer视图----------------- 2.16