HDFS入门
hadoop架构
- Hadoop 1.0中的资源管理方案
Hadoop 1.0指的是版本为Apache Hadoop 0.20.x、1.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统组成,其中,MapReduce是一个离线处理框架,由编程模型(新旧API)、运行时环境(JobTracker和TaskTracker)和数据处理引擎(MapTask和ReduceTask)三部分组成。
Hadoop 1.0资源管理由两部分组成:资源表示模型和资源分配模型,其中,资源表示模型用于描述资源的组织方式,Hadoop 1.0采用“槽位”(slot)组织各节点上的资源,而资源分配模型则决定如何将资源分配给各个作业/任务,在Hadoop中,这一部分由一个插拔式的调度器完成。
Hadoop引入了“slot”概念表示各个节点上的计算资源。为了简化资源管理,Hadoop将各个节点上的资源(CPU、内存和磁盘等)等量切分成若干份,每一份用一个slot表示,同时规定一个task可根据实际需要占用多个slot 。通过引入“slot“这一概念,Hadoop将多维度资源抽象简化成一种资源(即slot),从而大大简化了资源管理问题。
更进一步说,slot相当于任务运行“许可证”,一个任务只有得到该“许可证”后,才能够获得运行的机会,这也意味着,每个节点上的slot数目决定了该节点上的最大允许的任务并发度。为了区分Map Task和Reduce Task所用资源量的差异,slot又被分为Map slot和Reduce slot两种,它们分别只能被Map Task和Reduce Task使用。Hadoop集群管理员可根据各个节点硬件配置和应用特点为它们分配不同的map slot数(由参数mapred.tasktracker.map.tasks.maximum指定)和reduce slot数(由参数mapred.tasktrackerreduce.tasks.maximum指定)。
Hadoop 1.0中的资源管理存在以下几个缺点:
(1)静态资源配置。采用了静态资源设置策略,即每个节点实现配置好可用的slot总数,这些slot数目一旦启动后无法再动态修改。
(2)资源无法共享。Hadoop 1.0将slot分为Map slot和Reduce slot两种,且不允许共享。对于一个作业,刚开始运行时,Map slot资源紧缺而Reduce slot空闲,当Map Task全部运行完成后,Reduce slot紧缺而Map slot空闲。很明显,这种区分slot类别的资源管理方案在一定程度上降低了slot的利用率。
(3) 资源划分粒度过大。这种基于无类别slot的资源划分方法的划分粒度仍过于粗糙,往往会造成节点资源利用率过高或者过低 ,比如,管理员事先规划好一个slot代表2GB内存和1个CPU,如果一个应用程序的任务只需要1GB内存,则会产生“资源碎片”,从而降低集群资源的利用率,同样,如果一个应用程序的任务需要3GB内存,则会隐式地抢占其他任务的资源,从而产生资源抢占现象,可能导致集群利用率过高。
(4) 没引入有效的资源隔离机制。Hadoop 1.0仅采用了基于jvm的资源隔离机制,这种方式仍过于粗糙,很多资源,比如CPU,无法进行隔离,这会造成同一个节点上的任务之间干扰严重。
该部分具体展开讲解可阅读我的新书《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》 中“第6章 JobTracker内部实现剖析” 中的“6.7 Hadoop资源管理”。- Hadoop 2.0中的资源管理方案
Hadoop 2.0指的是版本为Apache Hadoop 0.23.x、2.x或者CDH4系列的Hadoop,内核主要由HDFS、MapReduce和YARN三个系统组成,其中,YARN是一个资源管理系统,负责集群资源管理和调度,MapReduce则是运行在YARN上离线处理框架,它与Hadoop 1.0中的MapReduce在编程模型(新旧API)和数据处理引擎(MapTask和ReduceTask)两个方面是相同的。
让我们回归到资源分配的本质,即根据任务资源需求为其分配系统中的各类资源。在实际系统中,资源本身是多维度的,包括CPU、内存、网络I/O和磁盘I/O等,因此,如果想精确控制资源分配,不能再有slot的概念,最直接的方法是让任务直接向调度器申请自己需要的资源(比如某个任务可申请1.5GB 内存和1个CPU),而调度器则按照任务实际需求为其精细地分配对应的资源量,不再简单的将一个Slot分配给它,Hadoop 2.0正式采用了这种基于真实资源量的资源分配方案。
Hadoop 2.0(YARN)允许每个节点(NodeManager)配置可用的CPU和内存资源总量,而中央调度器则会根据这些资源总量分配给应用程序。节点(NodeManager)配置参数如下:
(1)yarn.nodemanager.resource.memory-mb
可分配的物理内存总量,默认是8*1024,即8GB。
(2)yarn.nodemanager.vmem-pmem-ratio
任务使用单位物理内存量对应最多可使用的虚拟内存量,默认值是2.1,表示每使用1MB的物理内存,最多可以使用2.1MB的虚拟内存总量。
(3)yarn.nodemanager.resource.cpu-vcore
可分配的虚拟CPU个数,默认是8。为了更细粒度的划分CPU资源和考虑到CPU性能异构性,YARN允许管理员根据实际需要和CPU性能将每个物理CPU划分成若干个虚拟CPU,而每管理员可为每个节点单独配置可用的虚拟CPU个数,且用户提交应用程序时,也可指定每个任务需要的虚拟CPU个数。比如node1节点上有8个CPU,node2上有16个CPU,且node1 CPU性能是node2的2倍,那么可为这两个节点配置相同数目的虚拟CPU个数,比如均为32,由于用户设置虚拟CPU个数必须是整数,每个任务至少使用node2 的半个CPU(不能更少了)。
此外,Hadoop 2.0还引入了基于cgroups的轻量级资源隔离方案,这大大降低了同节点上任务间的相互干扰,而Hadoop 1.0仅采用了基于JVM的资源隔离,粒度非常粗糙。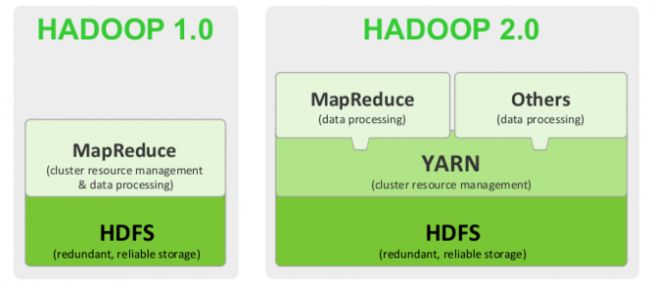 image
imageHadoop 1.0
 image
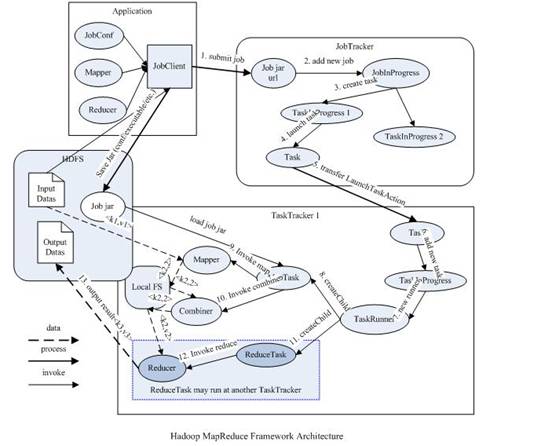
image从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路:
- 首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job Tracker 中,Job Tracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
- TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
- TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
- JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
- JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
- 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
- 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
- 源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
- 从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
hadoop2.0
 image
image从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce 的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷。在过去的几年中,hadoop 开发团队做了一些 bug 的修复,但是最近这些修复的成本越来越高,这表明对原框架做出改变的难度越来越大。
为从根本上解决旧 MapReduce 框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn,
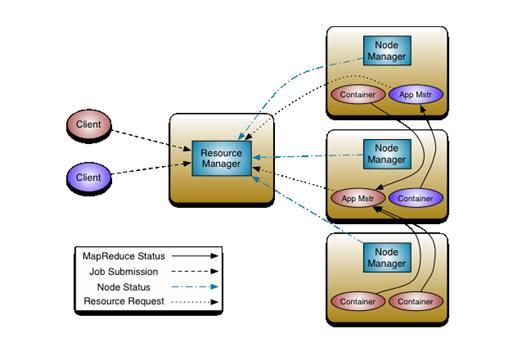
重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。
上图中 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
hdfs相关概念和特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;重要特性如下:
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
(注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
hdfs的优缺点
hdfs的优点:1、处理超大文件
这里的超大文件通常是指百MB、甚至数百TB大小的文件。目前在实际应用中,HDFS已经能用来存储管理PB级的数据了。2、流式的访问数据
HDFS的设计建立在“一次写入、多次读写”任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效。3、运行于廉价的商用机器集群上
Hadoop设计对应急需求比较低,只须运行在低廉的商用硬件集群上,而无需在昂贵的高可用性机器上。廉价的商用机也就意味着大型集群中出现节点故障情况的概率非常高。HDFS遇到了上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。HDFS的缺点:
1、不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求,则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。 改进策略: 对于那些有低延时要求的应用程序,HBase是一个更好的选择,通过上层数据管理项目尽可能地弥补这个不足。在性能上有了很大的提升,它的口号是goes real time。使用缓存或多个master设计可以降低Clinet的数据请求压力,以减少延时。2、无法高效存储大量的小文件
因为NameNode把文件系统的元数据放置在内存中,所有文件系统所能容纳的文件数目是由NameNode的内存大小来决定。还有一个问题就是,因为MapTask的数量是由Splits来决定的,所以用MR处理大量的小文件时,就会产生过多的MapTask,线程管理开销将会增加作业时间。当Hadoop处理很多小文件(文件大小小于HDFS中Block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个Split并分配一个Map任务,导致效率底下。 例如:一个1G的文件,会被划分成16个64MB的Split,并分配16个Map任务处理,而10000个100Kb的文件会被10000个Map任务处理。 改进策略: 要想让HDFS能处理好小文件,有不少方法。利用SequenceFile、MapFile、Har等方式归档小文件,这个方法的原理就是把小文件归档起来管理,HBase就是基于此的。3、不支持多用户写入及任意修改文件
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作,目前HDFS还不支持多个用户对同一文件的写操作,以及在文件任意位置进行修改HDFS shell命令行操作
例如: $ hadoop fs -ls /-help |—— 功能:输出这个命令参数手册
-ls |—— 功能:显示目录信息
示例:hadoopfs−lshdfs://Master:9000/备注:这些参数中,所有的hdfs路径都可以简写,–> hadoop fs -ls / 等同于上一条命令的效果-mkdir |—— 功能:在hdfs上创建目录
示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd-moveFromLocal |—— 功能:从本地剪切粘贴到hdfs
示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
-moveToLocal |—— 功能:从hdfs剪切粘贴到本地
示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt–appendToFile |—— 功能:追加一个文件到已经存在的文件末尾
示例:hadoop fs -appendToFile ./hello.txt hdfs://Master:9000/hello.txt
可以简写为: Hadoop fs -appendToFile ./hello.txt /hello.txt-cat |—— 功能:显示文件内容
示例:hadoop fs -cat /hello.txt
-tail |—— 功能:显示一个文件的末尾
示例:hadoop fs -tail /weblog/access_log.1
-text |—— 功能:以字符形式打印一个文件的内容
示例:hadoop fs -text /weblog/access_log.1-chgrp(只是更改文件的属组) -chmod(更改文件的权限) -chown(改文件的属主与属组)
示例: hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt-cp |—— 功能:从hdfs的一个路径拷贝hdfs的另一个路径
示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv |—— 功能:在hdfs目录中移动文件
示例: hadoop fs -mv /aaa/jdk.tar.gz /-get |—— 功能:等同于copyToLocal,就是从hdfs下载文件到本地
示例:hadoop fs -get /aaa/jdk.tar.gz
-getmerge |—— 功能:合并下载多个文件
示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum-put |—— 功能:等同于copyFromLocal
示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2-rm |—— 功能:删除文件或文件夹
示例:hadoop fs -rm -r /aaa/bbb/-rmdir |—— 功能:删除空目录
示例:hadoop fs -rmdir /aaa/bbb/ccc-df |—— 功能:统计文件系统的可用空间信息
示例:hadoop fs -df -h /
-du |—— 功能:统计文件夹的大小信息
示例: hadoop fs -du -s -h /aaa/*-count |—— 功能:统计一个指定目录下的文件节点数量
示例:hadoop fs -count /aaa/-setrep |—— 功能:设置hdfs中文件的副本数量
示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz
<这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量hdfs java API 操作
一.构建环境在hadoop的安装包中的share目录中有hadoop所有你能想象到的内容。 进入安装包下的share文件夹你会看到doc和hadoop文件夹。其中doc中是hadoop的整个document。而hadoop文件夹中则存放着所有开发hadoop所有用到的jar包,其依赖放到相应的lib文件夹中。 我们这次用到的是hadoop文件夹中的common以及hdfs文件夹中的内容。在创建工程时,继续将这两个文件夹中的jar包添加到相应的工程中,然后将文件夹中的lib文件夹的所有jar包作为依赖也添加到工程文件中(common和hdfs文件的lib文件中的jar包可能存在重复,注意去重。);其中source文件夹是该模块的源码包,如果想在IDEA中看到源码,需要将这些内容也添加到工程中。二.操作HDFS流程
- 获取HDFS的配置,根据HDFS的配置获取整个HDFS操作系统的内容
- 打开HDFS操作系统,进行操作
- 文件夹的操作:增删改查
- 文件的上传下载
- 文件的IO操作——hdfs之间的复制
三.具体的操作命令
- 根据配置获取HDFS文件操作系统(共有三种方式)
- 方法一:直接获取配置文件方法
通常情况下该方法用于本地有hadoop系统,可以直接进行访问。此时仅需在配置文件中指定要操作的文件系统为hdfs即可。这里的conf的配置文件可以设置hdfs的各种参数,并且优先级比配置文件要搞 - 方法二:指定URI路径,进而获取配置文件创建操作系统
通常该方法用于本地没有hadoop系统,但是可以通过URI的方式进行访问。此时要给给定hadoop的NN节点的访问路径,hadoop的用户名,以及配置文件信息(此时会自动访问远程hadoop的配置文件)
- 方法一:直接获取配置文件方法
/** * 根据配置文件获取HDFS操作对象 * 有两种方法: * 1.使用conf直接从本地获取配置文件创建HDFS对象 * 2.多用于本地没有hadoop系统,但是可以远程访问。使用给定的URI和用户名,访问远程的配置文件,然后创建HDFS对象。 * @return FileSystem */ public FileSystem getHadoopFileSystem() { FileSystem fs = null; Configuration conf = null; // 方法一,本地有配置文件,直接获取配置文件(core-site.xml,hdfs-site.xml) // 根据配置文件创建HDFS对象 // 此时必须指定hdsf的访问路径。 conf = new Configuration(); // 文件系统为必须设置的内容。其他配置参数可以自行设置,且优先级最高 conf.set("fs.defaultFS", "hdfs://huabingood01:9000"); try { // 根据配置文件创建HDFS对象 fs = FileSystem.get(conf); } catch (IOException e) { e.printStackTrace(); logger.error("",e); } // 方法二:本地没有hadoop系统,但是可以远程访问。根据给定的URI和用户名,访问hdfs的配置参数 // 此时的conf不需任何设置,只需读取远程的配置文件即可。 /*conf = new Configuration(); // Hadoop的用户名 String hdfsUserName = "huabingood"; URI hdfsUri = null; try { // HDFS的访问路径 hdfsUri = new URI("hdfs://huabingood01:9000"); } catch (URISyntaxException e) { e.printStackTrace(); logger.error(e); } try { // 根据远程的NN节点,获取配置信息,创建HDFS对象 fs = FileSystem.get(hdfsUri,conf,hdfsUserName); } catch (IOException e) { e.printStackTrace(); logger.error(e); } catch (InterruptedException e) { e.printStackTrace(); logger.error(e); }*/ // 方法三,反正我们没有搞懂。 /*conf = new Configuration(); conf.addResource("/opt/huabingood/pseudoDistributeHadoop/hadoop-2.6.0-cdh5.10.0/etc/hadoop/core-site.xml"); conf.addResource("/opt/huabingood/pseudoDistributeHadoop/hadoop-2.6.0-cdh5.10.0/etc/hadoop/hdfs-site.xml"); try { fs = FileSystem.get(conf); } catch (IOException e) { e.printStackTrace(); logger.error(e); }*/ return fs; }2.添加文件夹
/** * 这里的创建文件夹同shell中的mkdir -p 语序前面的文件夹不存在
* 跟java中的IO操作一样,也只能对path对象做操作;但是这里的Path对象是hdfs中的
* @param fs
* @return
*/
public boolean myCreatePath(FileSystem fs){ boolean b = false;Path path = new Path("/hyw/test/huabingood/hyw"); try { // even the path exist,it can also create the path. b = fs.mkdirs(path); } catch (IOException e) { e.printStackTrace(); logger.error(e); } finally { try { fs.close(); } catch (IOException e) { e.printStackTrace(); logger.error(e); } } return b; }3.删除文件夹
/** * 删除文件,实际上删除的是给定path路径的最后一个
* 跟java中一样,也需要path对象,不过是hadoop.fs包中的。
* 实际上delete(Path p)已经过时了,更多使用delete(Path p,boolean recursive)
* 后面的布尔值实际上是对文件的删除,相当于rm -r
* @param fs
* @return
*/
public boolean myDropHdfsPath(FileSystem fs){ boolean b = false; // drop the last path
Path path = new Path("/huabingood/hadoop.tar.gz"); try {
b = fs.delete(path,true);
} catch (IOException e) {
e.printStackTrace();
logger.error(e);
} finally { try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
logger.error(e);
}
} return b;
}4.重命名
/** * 重命名文件夹
* @param hdfs
* @return
*/
public boolean myRename(FileSystem hdfs){ boolean b = false;
Path oldPath = new Path("/hyw/test/huabingood");
Path newPath = new Path("/hyw/test/huabing"); try {
b = hdfs.rename(oldPath,newPath);
} catch (IOException e) {
e.printStackTrace();
logger.error(e);
}finally { try {
hdfs.close();
} catch (IOException e) {
e.printStackTrace();
logger.error(e);
}
} return b;
}5.文件夹的递归遍历
/** * 遍历文件夹
* public FileStatus[] listStatus(Path p)
* 通常使用HDFS文件系统的listStatus(path)来获取改定路径的子路径。然后逐个判断
* 值得注意的是:
* 1.并不是总有文件夹中有文件,有些文件夹是空的,如果仅仅做是否为文件的判断会有问题,必须加文件的长度是否为0的判断
* 2.使用getPath()方法获取的是FileStatus对象是带URL路径的。使用FileStatus.getPath().toUri().getPath()获取的路径才是不带url的路径
* @param hdfs
* @param listPath 传入的HDFS开始遍历的路径
* @return
/
public SetrecursiveHdfsPath(FileSystem hdfs,Path listPath){ / FileStatus[] files = null;
try {
files = hdfs.listStatus(listPath);
Path[] paths = FileUtil.stat2Paths(files);
for(int i=0;i
// set.add(paths[i].toString());
set.add(paths[i].getName());
}else {
recursiveHdfsPath(hdfs,paths[i]);
}
}
} catch (IOException e) {
e.printStackTrace();
logger.error(e);
}*/ FileStatus[] files = null; try {
files = hdfs.listStatus(listPath); // 实际上并不是每个文件夹都会有文件的。
if(files.length == 0){ // 如果不使用toUri(),获取的路径带URL。
set.add(listPath.toUri().getPath());
}else { // 判断是否为文件
for (FileStatus f : files) { if (files.length == 0 || f.isFile()) {
set.add(f.getPath().toUri().getPath());
} else { // 是文件夹,且非空,就继续遍历
recursiveHdfsPath(hdfs, f.getPath());
}
}
}
} catch (IOException e) {
e.printStackTrace();
logger.error(e);
} return set;
}6.文件的判断
/** * 文件简单的判断
* 是否存在
* 是否是文件夹
* 是否是文件
* @param fs */
public void myCheck(FileSystem fs){ boolean isExists = false; boolean isDirectorys = false; boolean isFiles = false;Path path = new Path("/hyw/test/huabingood01"); try { isExists = fs.exists(path); isDirectorys = fs.isDirectory(path); isFiles = fs.isFile(path); } catch (IOException e){ e.printStackTrace(); logger.error(e); } finally { try { fs.close(); } catch (IOException e) { e.printStackTrace(); logger.error(e); } } if(!isExists){ System.out.println("lu jing not cun zai."); }else{ System.out.println("lu jing cun zai."); if(isDirectorys){ System.out.println("Directory"); }else if(isFiles){ System.out.println("Files"); } }7.文件配置信息的查询
/** * 获取配置的所有信息
* 首先,我们要知道配置文件是哪一个
* 然后我们将获取的配置文件用迭代器接收
* 实际上配置中是KV对,我们可以通过java中的Entry来接收
* */
public void showAllConf(){
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://huabingood01:9000");
Iterator
Map.Entry
System.out.println(entry.getKey()+"=" +entry.getValue());
}
}8.文件的上传
/** * 文件下载
* 注意下载的路径的最后一个地址是下载的文件名
* copyToLocalFile(Path local,Path hdfs)
* 下载命令中的参数是没有任何布尔值的,如果添加了布尔是,意味着这是moveToLocalFile()
* @param fs */
public void getFileFromHDFS(FileSystem fs){
Path HDFSPath = new Path("/hyw/test/hadoop-2.6.0-cdh5.10.0.tar.gz");
Path localPath = new Path("/home/huabingood"); try {
fs.copyToLocalFile(HDFSPath,localPath);
} catch (IOException e) {
e.printStackTrace();
logger.error("zhe li you cuo wu !" ,e);
}finally { try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
logger.error("zhe li you cuo wu !", e);
}
}
}9.文件的下载
/** * 文件的下载
* 注意事项同文件的上传
* 注意如果上传的路径不存在会自动创建
* 如果存在同名的文件,会覆盖
* @param fs */
public void myPutFile2HDFS(FileSystem fs){ boolean pathExists = false; // 如果上传的路径不存在会创建 // 如果该路径文件已存在,就会覆盖
Path localPath = new Path("/home/huabingood/绣春刀.rmbv");
Path hdfsPath = new Path("/hyw/test/huabingood/abc/efg/绣春刀.rmbv"); try {
fs.copyFromLocalFile(localPath,hdfsPath);
} catch (IOException e) {
e.printStackTrace();
}finally { try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}}10.文件的IO操作——HDFS之间文件的复制
/** * hdfs之间文件的复制
* 使用FSDataInputStream来打开文件open(Path p)
* 使用FSDataOutputStream开创建写到的路径create(Path p)
* 使用 IOUtils.copyBytes(FSDataInputStream,FSDataOutputStream,int buffer,Boolean isClose)来进行具体的读写
* 说明:
* 1.java中使用缓冲区来加速读取文件,这里也使用了缓冲区,但是只要指定缓冲区大小即可,不必单独设置一个新的数组来接受
* 2.最后一个布尔值表示是否使用完后关闭读写流。通常是false,如果不手动关会报错的
* @param hdfs /
public void copyFileBetweenHDFS(FileSystem hdfs){
Path inPath = new Path("/hyw/test/hadoop-2.6.0-cdh5.10.0.tar.gz");
Path outPath = new Path("/huabin/hadoop.tar.gz"); // byte[] ioBuffer = new byte[10241024*64]; // int len = 0;
FSDataInputStream hdfsIn = null;
FSDataOutputStream hdfsOut = null; try {
hdfsIn = hdfs.open(inPath);
hdfsOut = hdfs.create(outPath);IOUtils.copyBytes(hdfsIn,hdfsOut,1024*1024*64,false); /*while((len=hdfsIn.read(ioBuffer))!= -1){ IOUtils.copyBytes(hdfsIn,hdfsOut,len,true); }*/ } catch (IOException e) { e.printStackTrace(); logger.error(e); }finally { try { hdfsOut.close(); hdfsIn.close(); } catch (IOException e) { e.printStackTrace(); } } }hdfs的核心设计
一、hadoop心跳机制(heartbeat)1、 Hadoop 是 Master/Slave 结构, Master 中有 NameNode 和 ResourceManager, Slave 中有 Datanode 和 NodeManager
2、 Master 启动的时候会启动一个 IPC( Inter-Process Comunication,进程间通信) server 服 务,等待 slave 的链接
3、 Slave 启动时,会主动链接 master 的 ipc server 服务,并且每隔 3 秒链接一次 master,这 个间隔时间是可以调整的,参数为 dfs.heartbeat.interval,这个每隔一段时间去连接一次 的机制,我们形象的称为心跳。 Slave 通过心跳汇报自己的信息给 master(自己服务器的CPU使用率,内存还剩多少等等一些信息),master 也通 过心跳给 slave 下达命令。
4、NameNode 通过心跳得知 Datanode 的状态
ResourceManager 通过心跳得知 NodeManager 的状态
5、 如果 master 长时间都没有收到 slave 的心跳,就认为该 slave 挂掉了。!!!!!
Namenode 感知到 Datanode 掉线死亡的时长计算:
HDFS 默认的超时时间为 ``10分钟+``30秒。这里暂且定义超时时间为 timeout计算公式为:timeout = 2* heartbeat.recheck.interval + 10* dfs.heartbeat.interval而默认的 heartbeat.recheck.interval 大小为 ``5分钟,dfs.heartbeat.interval 默认的大小为 ``3秒。需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒所以,举个例子,如果 heartbeat.recheck.interval 设置为 ``5000``(毫秒), dfs.heartbeat.interval设置为 ``3``(秒,默认),则总的超时时间为 ``40秒heartbeat.recheck.interval 5000 dfs.heartbeat.interval 3 二、HDFS安全模式
问题引出:集群启动后,可以查看目录,但是上传文件时报错,打开 web页面可看到 namenode 正处于 safemode 状态,怎么处理?解释: safemode 是 namenode 的一种状态( active/standby/safemode 安全模式)
namenode 进入安全模式的原理:
a、 namenode 发现集群中的 block 丢失率达到一定比例时( 0.1%), namenode 就会进入 安全模式,在安全模式下,客户端不能对任何数据进行操作,只能查看元数据信息(比 如 ls/mkdir) 这个丢失率是可以手动配置的,默认是 dfs.safemode.threshold.pct=0.999f
b、如何退出安全模式?
找到问题所在,进行修复(比如修复宕机的 datanode)
或者可以手动强行退出安全模式(没有真正解决问题): hdfs dfsadmin --safemode leave
c、在 hdfs 集群正常冷启动时,namenode 也会在 safemode 状态下维持相当长的一段时间, 此时你不需要去理会,等待它自动退出安全模式即可正常启动的时候进入安全的原理: (原理: namenode 的内存元数据中,包含文件路径、副本数、 blockid,及每一个 block 所在 datanode 的信息,而 fsimage 中,不包含 block 所在的 datanode 信息,那么,当 namenode 冷启动时,此时内存中的元数据只能从 fsimage 中加载而来,从而就没有 block 所在的datanode 信息——>就会导致 namenode 认为所有的 block 都已经丢失——>进入安全模式— —>datanode 启动后,会定期向 namenode 汇报自身所持有的 blockid 信息, ——>随着 datanode 陆续启动,从而陆续汇报 block 信息, namenode 就会将内存元数据中的 block 所
在 datanode 信息补全更新——>找到了所有 block 的位置, 从而自动退出安全模式)安全模式常用操作命令:
hadoop dfsadmin -safemode leave //强制 NameNode 退出安全模式
hadoop dfsadmin -safemode enter //进入安全模式
hadoop dfsadmin -safemode get //查看安全模式状态
hadoop dfsadmin -safemode wait //等待,一直到安全模式结束(如果你使用的版本是 2.X 之后的版本,那么这个 hadoop 命令可以替换成 hdfs,它们都在 bin目录下 )
三、HDFS的副本存放策略
1、 作用: 数据分块存储和副本的存放,是保证可靠性和高性能的关键
2、 方法:
将每个文件的数据进行分块存储, 每一个数据块又保存有多个副本, 这些数据块副本分 布在不同的机器节点上 image
image3、存放说明:
在多数情况下, HDFS 默认的副本系数是 3, Hadoop 默认对 3 个副本的存放策略,如下图:
 image
image第一个 block 副本放在和 client 所在的 node 里(如果 client 不在集群范围内,则这第一个 node 是随机选取的,系统会尝试不选择哪些太满或者太忙的 node)。
第二个副本放置在与第一个节点不同的机架中的 node 中( 近乎随机选择,系统会尝试不选 择哪些太满或者太忙的 node)。
第三个副本和第二个在同一个机架,随机放在不同的 node 中。4、修改副本数
第一种方式: 修改集群文件 hdfs-site.xml
dfs.replication
1
第二种方式: 命令设置
bin/hadoop fs -setrep -R 1 /四、负载均衡
机器与机器之间磁盘利用率不平衡是 HDFS 集群非常容易出现的情况,尤其是在 DataNode 节点出现故障或在现有的集群上增添新的 DataNode 的时候分析数据块分布和重新均衡 DataNode 上的数据分布的工具
命令: sbin/start-balancer.sh
sbin/start-balancer.sh -t 10%
集群中容量最高值 与最低值 差值不能超过10%,如果超过,负载均衡就不能工作了
练习题
1.创建一个文本文件 test.txt,然后将该文件通过刚才学习的hdfs API 将该文件上传到hdfs文件系统的/ssh目录中去,并将该文件目录的文件打印输出到控制台中去。
文件内容如下:
hello lanou
hello ibm
hello tianjin
hello shanghai2.hdfs包含哪些组件?这些组件分别代表什么含义?他们在hdfs架构中的作用是什么?
3.使用hdfs java API来进行操作,对hdfs进行上传文件,并将该文件的内容打印输出到控制台上。
- Hadoop 2.0中的资源管理方案