概述
在使用docke集群的时候,不可避免的会遇到网络问题,那么在遇到网络问题后如何做有效的排查呢,这需要我们对于docker集群网络本身实现有深入的理解,以下这篇文章非常好的诠释了整个docker集群网络的结构和原理,文章分为3部分,我也将分三次翻译。
原文地址
原文地址
作者:LAURENT BERNAILLE
介绍
在D2SI,我们在非常早期就开始使用Docker并帮助很多Docker项目发布到生产环境,我们相信将一项技术应用到生产环境中,需要深入理解这项技术以便能够debug复杂的问题,分析异常行为以及定位性能退化的情况。这也就是为什么我们尽最大努力去理解Docker所使用的各个技术组件。
这篇blog主要关注Docker的overlay网络,Docker的overlay网络依赖下面几项技术:
- network namespaces
- VXLAN
- Netlink and distributed key-value store
这篇文章将一项一项的讲述这些技术和相关的用户空间的工具,并且利用实践的方式展示这些技术是如何相互配合来完成overlay网络的设置,使得其中的容器能够相互连接。
这篇文章来源于我在Austin的DockerCon2017演讲,幻灯片可以在此处获取。
所有在这篇文章中使用的代码可以在GitHub上获取。
Docker Overlay 网络
首先,我们将在Docker的宿主机之间构建一个overlay网络,在例子中,我们将使用3台主机:两台运行Docker,一台运行Consul。Docker将使用Consul存储overlay网络的元数据,包括容器IP,MAC地址和容器的位置。这些信息将被所有的Docker engines所共享。在Docker1.12版本之前,Docker使用一个外部的key-value存储(Etcd or Consul)来创建overlay网络和Docker Swarms(现在经常被称为“classic Swarm”)。从Docker1.12开始,Docker使用内部的Key-Value存储去创建Swarm和overlay网络(“Swarm mode” or “new swarm”)。我们选择使用Consul是因为Consul允许我们查看Docker存储的keys并且能够更好的理解key-value存储的所扮演的角色。我们将Consul运行在单台主机上,但是在实际环境中我们至少需要3个节点组成的集群来保证系统的弹性(容灾)。
在我们的例子中,所用服务的IP地址如下:
- consul: 10.0.0.5
- docker0: 10.0.0.10
- docker1: 10.0.0.11
启动Consul 和 Docker服务
首先,我们需要启动Consul服务。为此,先下载Consul。然后利用以下命令启动一个非常小的Consul服务:
$ consul agent -server -dev -ui -client 0.0.0.0
我们实用如下的flags:
- server: 以server模式启动consul agent
- dev: 启动一个独立的没有持久化的Console服务
- ui: 启动一个简单的web界面,以便我们可以查看Docker存储的keys和对应的values
- client 0.0.0.0: 绑定所有的网卡,以便客户端访问(默认只绑定127.0.0.1)
为了使Docker engines 使用 Consul来作为key-value存储,我们使用如下的选项来启动Docker daemons
$ dockerd -H fd:// --cluster-store=consul://consul:8500 --cluster-advertise=eth0:2376
cluster-advertise可选项用于Docker宿主机指定哪一个IP地址发布到集群中(这个选项不是可选的)。这个命令假设consul能够被解析到10.0.0.5这个IP地址。
如果我们打开Consul的UI,我们可以看到Docker创建了一些keys,但是网络相关的key:http://consul:8500/v1/kv/docker/network/v1.0/network/](http://consul:8500/v1/kv/docker/network/v1.0/network/) 还是空的。

你可以使用在GitHub上的terroform步骤很方便的在AWS上面构建相同的环境。所有默认的配置(特别是所使用的region)都在variables.tf里面。你得给key_pair变量赋值,不管是通过命令行的方式(terraform apply -var key_pair=demo)还是通过修改variable.tf文件。这三个实例需要配置实际的数据:consul和docker的安装和启动相关的选项都配置的足够好,但是需要添加一条记录到/etc/hosts,以便consul能够被解析成consul服务所在机器的IP地址。当需要连接consul或者docker服务的时候,你需要使用Public IP地址(在 terraform 的输出中给出),并且连接的时候使用用户为“admin”(the terraform setup uses a debian AMI)。
创建一个Overlay
我们可以在两个Docker节点之间创建一个overlay网络:
docker0:~$ docker network create --driver overlay --subnet 192.168.0.0/24 demonet
13fb802253b6f0a44e17e2b65505490e0c80527e1d78c4f5c74375aff4bf882a
创建网络的时候选择overlay驱动,并且选择192.168.0.0/24来作为overlay的子网(子网选项是可选的,但是我们想让这个地址跟主机地址完全不同,以方便分析)
然后我们在各个docker主机上列出当前的网络来验证一下overlay配置的正确性
docker0:~$ docker network ls
NETWORK ID NAME DRIVER SCOPE
eb096cb816c0 bridge bridge local
13fb802253b6 demonet overlay global
d538d58b17e7 host host local
f2ee470bb968 none null local
docker1:~$ docker network ls
NETWORK ID NAME DRIVER SCOPE
eb7a05eba815 bridge bridge local
13fb802253b6 demonet overlay global
4346f6c422b2 host host local
5e8ac997ecfa none null local
这看上去是对的:两个docker节点都存在demonet网络并且拥有相同的网络id。
让我们利用在docker0上面创建一个容器,然后在docker1上面看能否ping通它来验证一下我们的overlay网络是否正常工作。在docker0上,我们创建了一个C0容器,attach到我们的overlay网络上,给定一个ip地址为192.168.0.100,并且是这个容器进入睡眠状态。在docker1上我们创建了一个容器attach到overlay网络上,并在在容器里面执行ping命令到目标C0。
docker0:~$ docker run -d --ip 192.168.0.100 --net demonet --name C0 debian sleep 3600
docker1:~$ docker run -it --rm --net demonet debian bash
root@e37bf5e35f83:/# ping 192.168.0.100
PING 192.168.0.100 (192.168.0.100): 56 data bytes
64 bytes from 192.168.0.100: icmp_seq=0 ttl=64 time=0.618 ms
64 bytes from 192.168.0.100: icmp_seq=1 ttl=64 time=0.483 ms
我们可以看到两个容器之间的连接是OK的。如果我们从docker1 ping C0的话,发现这是不通的,这个是因为docker1 不知道192.168.0.0/24网络的任何信息,这个网络是独立位于overlay上面的。
docker1:~$ ping 192.168.0.100
PING 192.168.0.100 (192.168.0.100) 56(84) bytes of data.
^C--- 192.168.0.100 ping statistics ---
4 packets transmitted, 0 received, 100% packet loss, time 3024ms
下面是我们目前构建的:

底层原理
现在我们已经构建了一个overlay网络,让我们试着来看看它是如何工作的。
容器的网络配置
C0容器的网络配置是怎么样的呢?我们可以在容器中执行如下的命令去发现:
docker0:~$ docker exec C0 ip addr show
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
6: eth0: mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:00:64 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.100/24 scope global eth0
valid_lft forever preferred_lft forever
9: eth1: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 scope global eth1
valid_lft forever preferred_lft forever
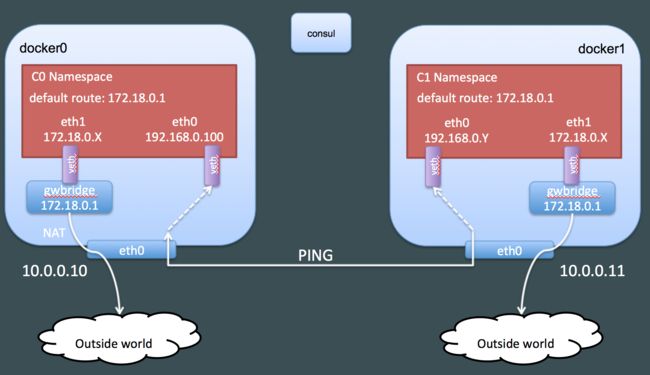
我们在容器中有两个网卡(当前还包含一个环回网卡)
- eth0: 配置的IP地址在192.168.0.0/24网络范围内,这个网卡是在overlay网络上的
- eth1: 配置的IP地址在172.18.0.2/16网络范围内,这个网络我们从来没有配置过
路由配置是怎么样的呢?
docker0:~$ docker exec C0 ip route show
default via 172.18.0.1 dev eth1
172.18.0.0/16 dev eth1 proto kernel scope link src 172.18.0.2
192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.100
路由配置显示默认路由是通过eth1,这意味着这个网卡是用来访问overlay网络以外的资源的。我们可以利用ping一个外部IP地址来非常简单的验证这一点:
$ docker exec -it C0 ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: icmp_seq=0 ttl=51 time=0.957 ms
64 bytes from 8.8.8.8: icmp_seq=1 ttl=51 time=0.975 ms
注意,其实可以利用--internal 选项创建一个overlay网络,在其上的容器不能访问外部网络
让我们查看这些网卡上面的更多的信息:
docker0:~$ docker exec C0 ip -details link show eth0
6: eth0: mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:c0:a8:00:64 brd ff:ff:ff:ff:ff:ff promiscuity 0
veth
docker0:~$ docker exec C0 ip -details link show eth1
9: eth1: mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff promiscuity 0
veth
这两个网卡的类型都是veth。veth网卡通常是成对出现并且是虚拟连接的。两个成对的veth网卡可以在不同的网络命名空间里面,这样可以使得两个不同的网络命名空间进行相互通信。这两个veth网卡用于在容器的网络命名空间内访问外部信息。
以下是我们目前发现的:

我们现在需要发现这两个veth网卡的配对网卡
容器连接的是什么?
我们可以利用ethtool发现另一端的veth网卡。然而这个命令在我们的容器里面是不可用的。我们可以利用“nsenter”命令来在容器的命名空间中执行ethtool命令(“nsenter”允许我们进入一个进程关联的一个或者多个命名空间),或者利用“ip netns exec”(依赖iproute)在指定的网络命名空间里面执行一个命令。Docker并没有在 /var/run/netns目录下面创建符号链接,但是ip netns 是在 /var/run/netns上面来寻找网络命名空间的。这个就是为什么我们利用nsenter来进入容器创建的命名空间。
可以利用以下的命令列出Docker创建的网络命名空间
docker0:~$ sudo ls -1 /var/run/docker/netns
e4b8ecb7ae7c
1-13fb802253
为了使用这些信息,我们需要辨别出容器所使用的网络命名空间。我们可以利用inspecting容器来获取,需要提取的信息在SandboxKey里面:
docker0:~$ docker inspect C0 -f {{.NetworkSettings.SandboxKey}} /var/run/docker/netns/e4b8ecb7ae7c
docker0:~$ C0netns=$(docker inspect C0 -f {{.NetworkSettings.SandboxKey}})
现在,我们可以在容器的网络命名空间内执行宿主机上面的命令(即使容器内是不包含这个命令的):
docker0:~$ sudo nsenter --net=$C0netns ip addr show eth0
6: eth0: mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:00:64 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.100/24 scope global eth0
valid_lft forever preferred_lft forever
让我们看一下eth0和eth1配对网卡的索引值
docker0:~$ sudo nsenter --net=$C0netns ethtool -S eth0
NIC statistics:
peer_ifindex: 7
docker0:~$ sudo nsenter --net=$C0netns ethtool -S eth1
NIC statistics:
peer_ifindex: 10
我们发现配对网卡的索引为7和10.我们先看一下宿主机本身是否有这些网卡:
docker0:~$ ip -details link show
1: lo: mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity 0
2: eth0: mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 06:e2:c0:20:ec:9f brd ff:ff:ff:ff:ff:ff promiscuity 0
3: docker0: mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:a7:17:99:39 brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge
8: docker_gwbridge: mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:be:d6:b0:c5 brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge
10: vethbc521fc: mtu 1500 qdisc noqueue master docker_gwbridge state UP mode DEFAULT group default
link/ether 32:a1:47:1a:7f:1e brd ff:ff:ff:ff:ff:ff promiscuity 1
veth
bridge_slave
我们可以从输出中看到网卡10,但是没有看到网卡7。并且我们发现网卡10是插在网桥“docker_gwbridge”上的。那这个网桥是什么呢?如果列出docker管理的网络,我们可以发现这个网桥就在列表里面:
docker0:~$ docker network ls
NETWORK ID NAME DRIVER SCOPE
eb096cb816c0 bridge bridge local
13fb802253b6 demonet overlay global
f6823b311fd2 docker_gwbridge bridge local
d538d58b17e7 host host local
f2ee470bb968 none null local
可以inspect这个网桥:
docker0:~$ docker inspect docker_gwbridge
"Name": "docker_gwbridge",
"Driver": "bridge",
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.18.0.0/16",
"Gateway": "172.18.0.1"
}
]
},
"Options": {
"com.docker.network.bridge.enable_icc": "false",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.name": "docker_gwbridge"
}
为了保证我们聚焦在必要的信息上面,我移除了部分的输出信息:
- 这个网络利用了bridge驱动(这个驱动就是docker的标准网桥bridge用的驱动)
- 它使用子网172.18.0.0/16,这个跟eth1是一致的。
- enable_icc被设置为false,这意味着我们不能利用这个网桥来做容器间的通信
- enable_ip_masquerade设置为 true, 这个意味着容器将通过NAT访问外部信息(这也就是为什么前面我们可以成功的ping通 8.8.8.8)
我们可以利用通过从另一个在docker0上attach在demonet网络上的容器来ping C0 的eth1的地址(172.18.0.2)来验证一下容器间的相互访问是被禁止的:
docker0:~$ docker run --rm -it --net demonet debian ping 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes
^C--- 172.18.0.2 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
这个是我们目前发现的网络结构
在overlay上的网卡eth0是什么样的?
网卡eth0的配对网卡不在宿主机的网络命名空间内,那么它肯定在另外的网络命名空间内,我们来重新看一下docker创建的网络命名空间
docker0:~$ sudo ls -1 /var/run/docker/netns
e4b8ecb7ae7c
1-13fb802253
我们可以看到一个命名空间叫做“1-13fb802253”,除了“1-“,这个命名空间的名字是overlay网络的网络id的开头部分。
docker0:~$ docker network inspect demonet -f {{.Id}}
13fb802253b6f0a44e17e2b65505490e0c80527e1d78c4f5c74375aff4bf882a
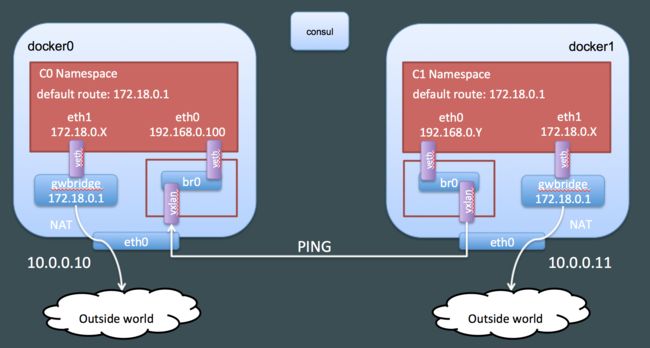
这个命名空间很明显应该跟overlay网络是相关联的。我们可以看一下这个命名空间的网卡:
docker0:~$ overns=/var/run/docker/netns/1-13fb802253
docker0:~$ sudo nsenter --net=$overns ip -d link show
2: br0: mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 3a:2d:44:c0:0e:aa brd ff:ff:ff:ff:ff:ff promiscuity 0
bridge
5: vxlan0: mtu 1450 qdisc noqueue master br0 state UNKNOWN mode DEFAULT group default
link/ether 4a:23:72:a3:fc:e3 brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 256 srcport 10240 65535 dstport 4789 proxy l2miss l3miss ageing 300
bridge_slave
7: veth2: mtu 1450 qdisc noqueue master br0 state UP mode DEFAULT group default
link/ether 3a:2d:44:c0:0e:aa brd ff:ff:ff:ff:ff:ff promiscuity 1
veth
bridge_slave
这个overlay网络命名空间包含三张网卡(和lo):
- br0: 一个网桥
- veth2: 一个veth网卡,是eth0的配对网卡并且这种网卡是连接到网桥上面的
- vxlan0: 一个“vxlan”类型的网卡,这张网卡也是连接到网桥上面的
这个vxlan的网卡很明显就是overlay网络的神奇之处,我们将会详细来看。现在我们先更新一下我们的网络结构图
结论
这是这篇文章的第一部分,在第二部分,我们将会聚焦VXLAN:这个协议是什么,docker是怎么来使用它的。