4.00 本章概述:
-了解RedHat Linux下各种类型的RAID阵列;
-学习如何管理高级的软RAID;
-学习如何优化软RAID阵列;
-规划和实现存储阵列的增长;
4.01 独立的磁盘冗余阵列(RAID):
RAID是Redundant Array of Independent Disk的缩写,中文翻译过来就叫做“独立的冗余磁盘阵列”。磁盘技术还没发展到如今这样强大的时候,磁盘的价格非常昂贵,尤其是大容量的磁盘,更是天价。为了满足企业级的存储需求,早期的RAID产生了,最初只是为了组合廉价的小容量磁盘,以代替昂贵的大容量磁盘,后来随着数据存储的发展,RAID才慢慢突出其在提高数据访问速度、提高数据可用性上的特点。
RAID可以将多个物理磁盘组合成一个逻辑单元,对于操作系统来说,它将RAID看成一个块设备,而在RAID底层其实是由多个块设备通过不同的冗余算法组合而成的逻辑设备。本章中讲的RAID是围绕软件级RAID展开的,因为软RAID是由操作系统层提供,不需要RAID卡等硬件设备也能轻松做实验,其次是软件RAID比硬件RAID在类型上和功能上都要丰富,更利于我们充分深入地理解RAID阵列。
软RAID有以下几种类型:
RAID0,RAID1,RAID5,RAID6,RAID10等等,这些具有代表性的RAID我们会在下面几节内容中详细讲解。
对于RAID的功能相信大家一定不陌生:首先是其冗余校验算法在保证数据完整性上的作用,同时也实现了容错的功能,提高了阵列的吞吐率,最实在的是提高了存储阵列的容量。
很多朋友搞不清楚软件RAID和硬件RAID的本质区别,我这里做个讲解。软件级的RAID是基于操作系统层面的,它的RAID抽象层是由系统实现的,它的各磁盘之间的数据分布、校验码运算、阵列修复等都是由系统内核及系统CPU提供的,只要操作系统出现了问题,这个RAID也将朝不保夕,所以软件RAID的可靠性是完全达不到企业级要求的;硬件级的RAID则是将很多重要功能抽离出来,嵌入到硬件RAID卡上,最重要一点是硬件RAID卡自身带有专门设计用于RAID算法运算的CPU,这样就不需要占用系统CPU的资源,解决了可能因系统CPU中断调度阻塞而造成的数据瓶颈。
在RadHat Linux下的软件RAID工具是mdadm,通过这个工具我们可以创建各种RAID阵列,查看详细RAID信息等等重要操作,后面我们会详细说明使用方法。
4.02 RAID0条带卷:
RAID0又叫做Stripe,即条带卷,是所有RAID级别中性能最好的阵列类型。RAID0之所以具有很高的性能,是因为RAID0实现了带区组,它将连续的数据分散地存储到多个磁盘驱动器中。
当系统有数据请求时,就可以同时由多个磁盘中并行读取数据。这种数据上的并行操作充分地利用了总线的带宽,所以数据吞吐率大大提高。同时磁盘驱动器也能相对地负载均衡,从而显著地提高磁盘的整体存取性能。
要实现RAID0起码要两个以上的磁盘驱动器,如果某次请求所需的数据刚好分布在不同的驱动器上时,此时效率性能最佳,因为此时可以进行并行的读取;如果所需数据恰好在同一个驱动器上,则无法并行读取。
虽然RAID0在存取性能上有优势,但是其弱点也相当明显。RAID0没有数据的差错控制,不能保证数据的完整性可靠性,当阵列中某个驱动器损坏时,将无法读取正确的数据。但是RAID0应用在一些对于数据可靠性要求不高的应用上还是不错的,例如电影存储、图片站存储等等。
RAID0配置实例:
# mdadm --create /dev/md0 --level=0 --raid-devices=2 --chunk=64 /dev/sd[ab]1
# mke2fs -j -b 4096 -E stride=16 /dev/md0
在RAID中有block、chunk和stride这个3个重要参数,它们描述了数据在底层的组织和分布。在创建RAID设备的阶段首先要指定chunk的大小,如--chunk=64,chunk块其实是RAID数据分布的基本单位,如上面创建的RAID0,数据是分散存储在2个磁盘中的,如在第一块盘写入了一个chunk时,就转到第二块盘继续写数据,也就是以chunk为单位轮转地在多块磁盘上写数据。
而block和stride则是在格式化创建文件系统时指定的,block好理解,就是文件系统层面上划分的基本块,你可以针对你所要存储的数据的特点来指定更为合适的Block Size;而stride也成为跨步数,stride=chunk/block,就是说,当你的chunk=64,block=4096时,你在第一块的文件系统上写了16个Block(16个跨步)才达到一个Chunk,也就是在磁盘上进行16个跨步的写操作才轮转到下一块磁盘。
4.03 RAID1镜像卷:
RAID1又称为镜像卷,使用RAID1至少需要2块以上的磁盘,当数据写入时,会在两块盘中写入完全相同的数据,形成镜像结构,当一组盘出现问题时,可以使用镜像盘,以此提高存储的容错能力。
RAID1的容错策略是完全备份,同样的数据在RAID1阵列中有两份,这样也使得读性能有了很大的提高,因为在读取数据时可以使主磁盘和镜像盘两个驱动器并行地进行读取。这样使得RAID1具有极佳的读性能。
RAID1支持热替换,即可以在在线的状态下取下受损的磁盘,替换上新的磁盘,此时RAID将自动进行镜像修复。但是由于RAID1是完全备份的策略,且出错校验较为严格,如果是软件级的RAID1则将会大大影响服务器的性能,尤其是在服务器负载高峰期。
RAID1配置实例:
# mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sd[ab]1
4.04 RAID5奇偶校验卷:
RAID5是带有分布式奇偶校验位的块级别条带卷,需要3块及以上个磁盘,RAID5具有很高的读性能,但是写性能则一般,因为在数据写入的过程中要进行奇偶校验运算并将校验码写到磁盘中。
RAID5在物理底层数据存储是以“异或”运算来实现校验的,如下表,该RAID5是由以下3块磁盘组成的,数据的写入都是分布式的,并没有哪一块盘是专门用于存放校验码的。
| Disk 1 |
Disk2 |
Disk3 |
| 1 |
1 |
0 |
| 1 |
0 |
1 |
| 0 |
1 |
1 |
如第一行,假如1,2号盘写入的是数据,则第3块盘则根据前两个数据做“异或”运算的结果存放起来,即 1 XOR 1 = 0,当任一盘出现问题,例如Disk1损坏,则将Disk2和Disk3上的数据进行“异或”运算就能得出Disk1上的数据,即 1 XOR 0 = 1。
RAID5在检测到某盘损坏时将自动进入降级模式,限制读写速度以保证现有已损坏的阵列不会出现更大的问题;RAID5支持热备盘,即当检测到某磁盘损坏时,阵列会自动将热备盘顶上,并自动进行数据修复动作。
RAID5的磁盘利用率:(N-1/N)*100% (N为磁盘数)
RAID5配置实例:
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sd[abc]1
4.05 RAID5的校验和数据分布:
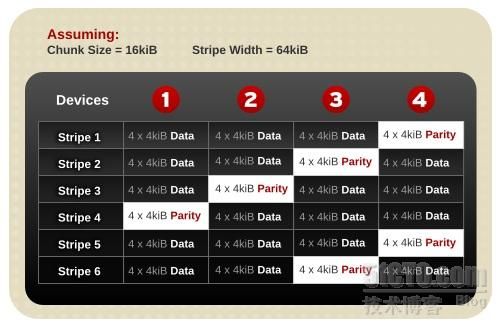
如图就是我上面提到过的底层数据分布,该RAID5阵列是由4个磁盘组成的,其中白色的框代表奇偶校验信息,可以看出数据的分布式存储以及条带的组成。以上数据分布模型采用的是“左对称奇偶校验”策略,这在RHEL中是默认使用的策略。
4.06 RAID5的数据排列算法:
RAID阵列的数据分布有以下4种算法,分别是左对称、右对称、左非对称、右非对称,而RAID5默认使用左对称的数据分布算法。
Left Asymmetric左非对称 Right Asymmetric右非对称
sda1 sdb1 sdc1 sde1 sda1 sdb1 sdc1 sde1
D0 D1 D2 P P D0 D1 D2
D3 D4 P D5 D3 P D4 D5
D6 P D7 D8 D6 D7 P D8
P D9 D10 D11 D9 D10 D11 P
D12 D13 D14 P P D12 D13 D14
=================================================================
Left Symmetric左对称 Right Symmetric右对称
sda1 sdb1 sdc1 sde1 sda1 sdb1 sdc1 sde1
D0 D1 D2 P P D0 D1 D2
D4 D5 P D3 D5 P D3 D4
D8 P D6 D7 D7 D8 P D6
P D9 D10 D11 D9 D10 D11 P
D12 D13 D14 P P D12 D13 D14
在使用mdadm创建RAID阵列时,可以使用--layout=
Left-asymmetric:对照上面的左非对称算法的数据分布实例,该算法描述的数据分布是,在阵列上从第一个阵列段到最后一个阵列段依次的存入数据块,与此同时,奇偶校验块P也从最后一个阵列段到第一个阵列段依次写入。
Right-asymmetric:数据块在阵列上从第一个阵列段到最后一个阵列段依次的存入数据块,与此同时,奇偶校验块P也从第一个阵列段到最后一个阵列段依次写入。
Left-symmetric:这个是RAID5默认的分布算法,也是对于读请求性能最佳的数据分布机制。奇偶校验信息P从最后一个阵列段到第一个阵列段依次写入。数据块从左向右写,且每行的数据块都先在校验块P后面开始写,直到写满。
Right-symmetric:奇偶校验信息P从第一个阵列段到最后一个阵列段依次写入。数据块从左向右写,且每行的数据块都先在校验块P后面开始写,直到写满。
4.07 RAID5数据更新的开销:
对于RAID5来说,每次数据更新需要如下4次I/O操作:
-从磁盘上读出需要更新的某个数据;
-更新该数据,但是此时奇偶校验信息还没更新过来;
-读出其他块的数据并计算出校验信息;
-写回更新后的信息和校验信息;
RAID5的数据更新开销相对较大,以上4次I/O操作对于读写操作频繁的应用是致命,其性能的下降被操作系统层强大的cache所掩盖了,对于性能的下降感觉不明显。
4.08 RAID6双份校验卷:
RAID6即带有双份分布式奇偶校验信息的块级别条带卷。它与RAID5很相似,但是比RAID5多设了一个校验位,也就是存储了两份的校验信息。所以RAID6阵列最少需要4块磁盘。
由于RAID6在进行写操作时需要计算两个校验码,所以其写性能较RAID5要差,但是容错能力却有了大大的提升。RAID6可以允许2块以上的磁盘出现问题,当磁盘损坏时,阵列进入降级模式,直到阵列修复后才会取消降级保护模式。
RAID6的磁盘利用率:(1-2/N)*100% (N为磁盘数)
RAID6配置实例:
# mdadm --create /dev/md0 --level=6 --raid-devices=4 /dev/sd[abcd]1
4.09 RAID6的校验和数据分布:
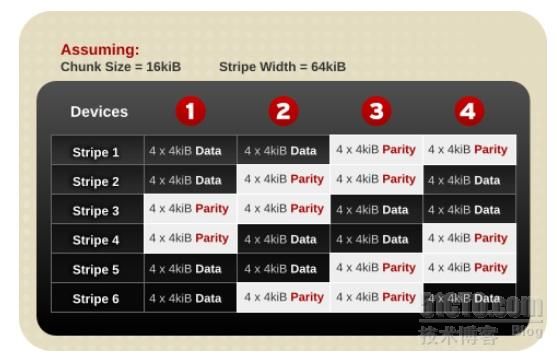
上图是RAID6的数据块分布图,了解RAID6的关键在于了解其如何在损坏2个以上的磁盘时依然保证数据的完整性。如图Stripe1中,Device1和Divice2上保存了数据块,Device3和Device4上则是校验信息。Device3的校验信息可以由Device1-3计算所得,Device4的校验信息可以由Device2-4计算所得。
当Device1和Device2损坏时,Device4上的校验信息就可以结合Device3和Device4来计算出Device2上的数据,Device1则利用Device2和3来计算,实现数据的冗余校验,保证数据的完整性。
4.10 RAID10阵列卷:
RAID10是一种嵌套的RAID阵列,结合了RAID1和RAID0的特点,既有RAID1的高容错能力,也具有RAID0的高性能。RAID10需要4块及以上个磁盘。
RAID10磁盘利用率:(1/N)*100% (N为磁盘数)
以下是一个RAID10配置实例:
磁盘sda1和sdb1创建成RAID1阵列,设备为/dev/md0;磁盘sdc1和sdd1创建成RAID1阵列,设备为/dev/md1;再将两个RAID1阵列组合成一个RAID0阵列:
# mdadm -C /dev/md0 --level=1 --raid-devices=2 /dev/sd[ab]1
# mdadm -C /dev/md1 -a yes --level=1 --raid-devices=2 /dev/sda[cd]1
# mdadm -C /dev/md2 -a yes --level=10 --raid-devices=2 /dev/md[01]
查看RAID设备的详细信息:
# mdadm -D /dev/md2
4.11 条带阵列的参数:
调整条带卷的参数对于优化阵列的性能是相当重要的。对于RAID0、RAID5、RAID6阵列主要有Chunk Size和Stride两个重要参数。
Chunk Size是指阵列中在每个物理磁盘上分布的数据块的大小,通常默认为64K,可以根据所提供服务的需求来进行适当的优化。Stride即跨步数,是在为阵列创建文件系统时可以指定的参数,由Chunk Size / Block Size计算所得。
减小Chunk Size的大小意味着文件在存储阵列中被分得更小,增大Chunk Size则可以使得文件保存在一个Chunk中,虽然设置大的Chunk有利于写操作,但是过大的Chunk会使得RAID的读性能不能很好地发挥,所以,盲目地加大Chunk Size有时会有反效果。
4.12 RAID状态信息/proc/mdstat:
/proc/mdstat中保存了当前所有RAID阵列的详细信息,我们可以通过查看该文件来获取RAID的状态信息。可以通过下面这条命令做实时监控:
# watch -n .5 'cat /proc/mdstat' (每隔0.5秒查看一次)
以下是各种状态信息的实例:
Initial sync'ing of a RAID1 (mirror):
Personalities : [raid1]
md0 : active raid1 sda5[1] sdb5[0]
987840 blocks [2/2] [UU]
[=======>.............] resync = 35.7% (354112/987840) finish=0.9min (RAID1修复中。。。)
speed=10743K/sec
-----------------------------------------------------------------
Active functioning RAID1:
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sda5[1] sdb5[0]
987840 blocks [2/2] [UU]
unused devices:
-----------------------------------------------------------------
Failed half of a RAID1:
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sda5[1](F) sdb5[0]
987840 blocks [2/1] [U_] (该RAID1损坏了一个磁盘)
unused devices:
4.13 详细的RAID状态信息:
要想获取详细的RAID信息,可以使用如下命令:
# mdadm --detail /dev/md0 (--detail可以简写为-D)
/dev/md0:
Version : 00.90.03
Creation Time : Tue Mar 13 14:20:58 2007
Raid Level : raid1
Array Size : 987840 (964.85 MiB 1011.55 MB)
Device Size : 987840 (964.85 MiB 1011.55 MB)
Raid Devices : 2
Total Devices : 2
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Tue Mar 13 14:25:34 2007
State : clean, degraded, recovering
Active Devices : 1
Working Devices : 2
Failed Devices : 0
Spare Devices : 1
Rebuild Status : 60% complete
UUID : 1ad0a27b:b5d6d1d7:296539b4:f69e34ed
Events : 0.6
Number Major Minor RaidDevice State
0 3 5 0 active sync /dev/sda5
1 3 6 1 spare rebuilding /dev/sdb5
由以上的RAID信息,我们可以看出,这是一个由两个磁盘组成的RAID1阵列,该RAID1状态为Clean、degraded、recovering,即表示阵列数据没有遭到污染,目前进入降级保护模式,且正在处于修复RAID过程中,目前已修复完成60%。
磁盘/dev/sda5处于活跃状态,而/dev/sdb5则正在参与修复,一旦修复完成,RAID将取消降级模式,恢复原有的RAID性能。
---本章未完,待续!