1. 什么是基数计算
基数计算(cardinality counting)指的是统计一批数据中的不重复元素的个数,常见于计算独立用户数(UV)、维度的独立取值数等等。实现基数统计最直接的方法,就是采用集合(Set)这种数据结构,当一个元素从未出现过时,便在集合中增加一个元素;如果出现过,那么集合仍保持不变。
在大数据的场景中,实现基数统计往往去面临以下的两个问题:
- 如果有效的存储原始数据,以避免数据占用空间过多,这里就涉及到存储空间压缩的问题
- 如果能够跨不同的维度、不同的时间段实现基数计算,比如在计算日度UV的情况下,如果计算出周度、或者月度的UV
本文旨在介绍目前比较成熟的基数计算的方式,并通过实例对比他们在解决以上两个问题上的效果,最后引出本文的重点,HyperLogLog算法的实现和应用。
2. Bitmap
2.1 基本原理
Bitmap进行基数计算的方法,是先定义一个bit数组,数组中的每一位对应数据的一种取值。由于bit是计算机中的最小单位,使用bit可以大量的减少存储空间。例如一个数组[1,3,4,5],那么对应的bitmap即为[0,0,0,1,1,1,0,1],后续每新增加一个元素,就和现有的bitmap进行OR操作,通过计算bitmap中1的个数,即可以得到基数计算的结果。
正是因为bitmap之间对OR也是良好支持的,两个bitmap在进行OR操作之后,便是这两个条件组合下的基数计算结果,因此使用bitmap是可以实现任意条件下的基数计算。
2.2 空间使用
按照上面介绍的原理,进行bitmap的构建。假如统计1亿数据的基数值,大约需要内存100000000/8/1024/1024 ~= 12M,如果有100个这样的对象,就需要1.2G的内存空间,可见占用内存还是很大的,在实际业务中基本很少使用。
3. Linear Counting
3.1 基本原理
Linear Counting是采用概率的方式进行基数估计的最简单的方法。下面通过一个实例描述Linear Counting的计算过程:
- 数据哈希:假设原始数据的基数为n,使用一组哈希空间为m的哈希函数H,将原始数据转换为满足均匀分组的一组哈希数组。
-
分桶数据统计:构建一个长度为m的bitmap,其中每一个bit对应哈希空间的一个值。生成哈希数组的值如果存在,则把相应的bit设置为1。当所有值设置完成后,统计bitmap中为0的bit数为u。
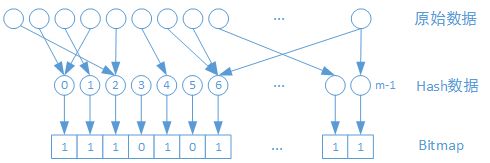
可以通过下述的公式计算基数估计的结果:
注意这里的log指的是自然对数。
公式的推导过程有兴趣的可以参考这篇文章。其中最重要的是要清楚,在经过n次数据的哈希后,bitmap中的某个bit值为0,是一个伯努利事件。记住这一点再理解公式推导就容易多了。
3.2 空间使用
Linear Counting的空间使用,和bitmap相比,空间复杂度是一致的,仅有线性下降。因此如果对于1亿的原始数据,仍然需要MB级别的内存空间存储。Linear Counting在实际应用中也很少被使用。
4. LogLog Counting
4.1 伯努利过程
在介绍LogLog Counting之前,我们先来回顾一下伯努利过程的概念。
伯努利过程是一个由有限个或无限个的独立随机变量 X1, X2, X3 ,..., 所组成的离散时间随机过程,其中 X1, X2, X3 ,..., 满足如下条件:
对每个 i, Xi 等于 0 或 1; 对每个 i, Xi = 1 的概率等于 p. 换言之,伯努利过程是一列独立同分布的伯努利试验。每个Xi 的2个结果也被称为“成功”或“失败”。所以当用数字 0 或 1 来表示的时候,这个数字被称为第i个试验的成功次数。
举一个常见的例子:每次抛硬币之后,出现正面和反面的概率分别为1/2,如果不停地抛硬币,直至出现正面为止,这就是一个伯努利过程。
这样,我们假设一共进行了n次伯努利过程,出现正面的次数分别为k1, k2, ... kmax,那么有以下两个结论:
- n次伯努利过程的投掷次数都不大于kmax
- n次伯努利过程,至少有一次的投掷次数等于kmax
已知投掷k次才出现正面的概率为:1/2^k,那么:
-
第一种情况的概率为:

-
第二种情况的概率为:
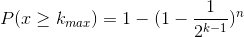
如果n >> 2^k,则P(x >= kmax)为0;如果n << 2^k,则P(x <= kmax)为0。因此我们可以用2^k来作为n的近似估计结果。
4.2 伯努利过程与LogLog Counting
如何将基数计算,等价地认为是一个伯努利过程,是LogLog Counting的关键所在。这里我们可以把原始数据进行哈希,哈希后的数组是满足均匀分布的。把每个元素看做一个投掷硬币的过程,将元素转换为2进制之后,每个bit出现0和1的概率是相等的。从高位开始查,第一次出现1的位置记为k,即等同于投掷硬币时出现第一个正面,将所有元素出现1的位置的最大值,记为kmax,那么2^kmax就是基数计算的结果。
4.3 LogLog Counting计算过程
- 数据哈希:这个和Linear Counting是类似的,都需要保证哈希后的数据是满足均匀分布的。
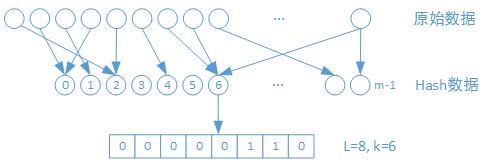
- 转换为2进制:将哈希后的每个元素,都转换为2进制,由于数据在哈希后满足均匀分布的,2进制数据每一个bit的0和1出现的概率都是1/2,这里设2进制数据的位数为L。
- 统计第一个1出现的位置:分别计算每个2进制数据,第一次出现1的次数。所有次数中的最大值为kmax,那么2^kmax就是最终结果。
下图中给出一个针对一个元素进行k值计算的过程。
4.4 数据分桶
上面的计算过程,由于是单一估计量,可能会出现一定的偶然性导致误差。因此这里引入数据分桶的方法。取哈希空间分成m个桶,用哈希值的前几个bit的值来决定数据属于哪一个桶,再对桶内的数据取k值,最终计算出kmax。再将所有桶的kmax取平均数,这样就通过多次估计取平均的方式,消除了单一估计可能存在的偶然性误差。计算公式如下:
4.5 误差修正和分析
以上的过程仍然是存在误差的,并不是无偏估计。将上述过程修正为无偏估计的过程由于过于复杂,这里就不再介绍了。需要了解的是,最终结果的误差公式为:
4.6 空间使用
到这里,我们就可以理解LogLog Counting中两个log了,它们的含义分别如下:
- 第一次log,和Linear Counting很类似,由于使用哈希,压缩了数据空间。
- 第二次log,由于在存储哈希值的第一次1出现的次数时,只需要存储结果k,而不需要存储原始的哈希值,进一步节省了空间。
加入哈希之后的值有32bit,那么每个桶需要5bit保存kmax的值,m个桶就是m5/8 B。
如果基数是1亿个(227),当分桶数为1024时,每个桶的基数上限为227 / 2^10 = 217,log(log(217))=4.09,那么每个桶需要5bit保存kmax,总共需要的空间为51024/8,等于640B,可见是非常小的。
5. Adapative Counting
通过概率计算可知,LogLog Counting由于使用了几何平均值,可能出现在基数较小的情况,有些桶是为空的。空桶对于最后平均值的计算干扰较大。
Adapative Counting的思想是将Linear Counting和LogLog Counting进行结合。Linear Counting和LogLog Counting的存储结构是类似的,仅仅是Linear Couting关心桶是否为空,而LogLog Counting需要桶中的kmax。
最终分析得到的结论是:在空桶率大于0.051时,使用Linear Counting的偏差率更小;在空桶率小于0.051时,使用LogLog Counting的偏差率更小。
6. HyperLogLog Counting
HyperLogLog Counting,是在LogLog Counting的基础上,将桶之间计算采用的几何平均,修改为调和平均,可以有效的减少空桶对于平均值的影响。
调和平均的计算公式如下:
使用调和平均后的偏差公式为:
可见偏差期望和LogLog Counting相比要更小。
参考文献
- Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure
- 解读Cardinality Estimation算法(第一部分:基本概念)