欢迎访问个人博客:blog.spursgo.com
关于pyhton2.x中编码问题的一点小理解
大约在一年前,当时接触pyhton爬虫时(那时还是在Windows上开发学习),由于网页中存在大量中文,自然不可避免的会涉及到编码问题。刚刚入门就遇到了python中的一个大麻烦:编码问题,查了一些资料把手上的问题解决之后,就没有去管编码问题了。
一年后,仍然习惯于python2.x。本来在macOS和ubuntu上写得很顺利得一个爬虫程序,转到windows 10上居然出现了大量的乱码。
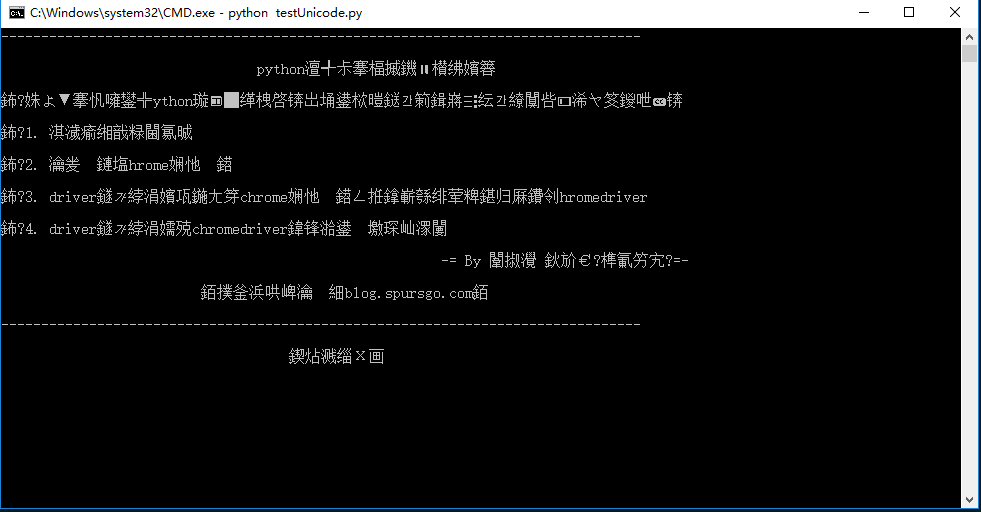
当时真的很郁闷,为什么在其他操作系统上运行好好的程序,到Windows上就成这样了呢?郁闷归郁闷,问题还是要解决呀!
于是乎,又开始和pyhton编码问题打交道了。因为现在养成了写博客的习惯,所以本次探究python编码问题的过程我就详细记录了下来,以便以后再次遇到这个问题,可以很快的查看而不需要再次折腾。
各个击破
1. Windows命令行的编码
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
这是我程序中对pyhton脚本默认编码的处理,python默认的本来是ascii编码,这里我改为了utf-8。
因此,如果我在程序执行这么一句:
print " "*25 + "〓个人博客:blog.spursgo.com〓"
那么,打印出来的这句话就是默认采用utf-8编码格式,嗯哼,难道有什么不对吗?
别忘了,我们还不知道Windows命令行窗口采取的编码格式呢!
好的,赶快查阅一下!
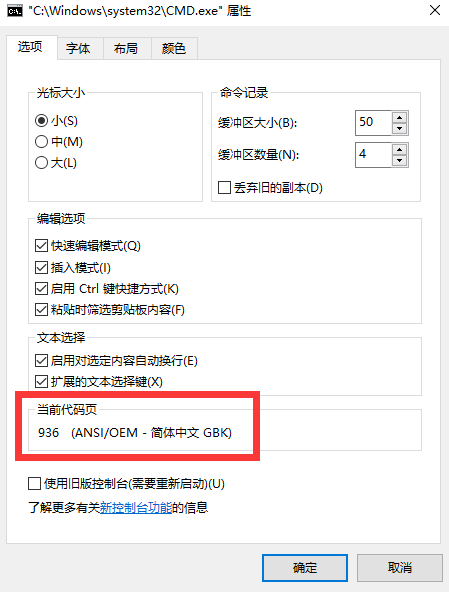
右击命令行窗口标题栏--选择属性--点击选项,之后我们会看到GBK的字样:
2. 编码格式介绍
哦,原来如此,我打印的是utf-8编码格式,但是他却采用gbk编码格式,命令行窗口当然不能正常显示喏!
可能你觉得对python的各种编码格式不是很了解,没关系,网上有很多介绍编码格式的文章,这里我推荐两篇:
在Python中正确使用Unicode 这篇侧重介绍在python中正确使用编码
Python字符编码详解 这篇侧重介绍编码格式
看完这两篇文章后,相信你会对pyhton中的编码会有很深刻的认识。
这里,主要记录一下我个人的一些理解和实验操作:
2.1 python中的字节串和字符串
对java比较了解的同学,应该会知道在java中不需要严格区分所谓的字节串和字符串,java这门语言把编码问题处理的非常好!
但是,在python2.x中,这两个概念却是一定要理解的,不然各种编码问题可能就会找上门来。
以下概念来自于自己的理解,可能不是很严谨。
字节串:以字节为单位,它的每一个个体是字节,因此我们统计字节串的长度时,结果一定是所有字节的数量。
字符串:以字符为单位,它的每一个个体是字符,因此我们统计字符串的长度时,结果一定是所有字符的数量。
咦!怎么两句话好像差不多? 是的,我们要区分的就是字符和字节:一个字符可以包含多个字节。
说了这么多,还是来验证一下吧:
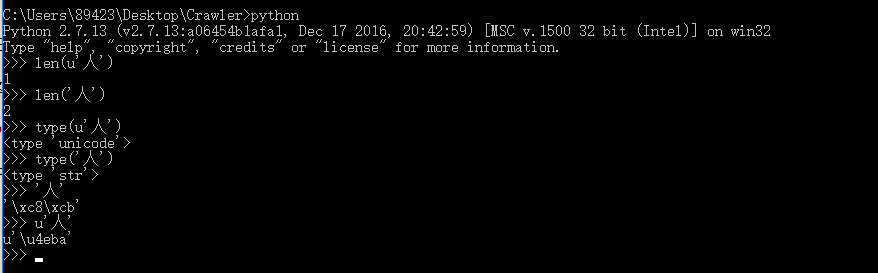
从图片中,我们可以可以清楚的看到,一个‘人’字,由于它的类型不一样,当我们取长度时,得到的结果不一样。
现在是不是对字节和字符有了更好的认识了呢?
3. 编码格式的互相转换
decode :解码,实现其他编码格式到unicode的转换
encode :编码,实现unicode到的转换其他编码格式
常见的其他编码格式:utf-8,gbk,gb2312
这是有一个问题我们一定要重视:decode既然是其他编码格式到unicode的转换,达到解码的目的,也就是说unicode本身不是一种编码格式。因此,我们在进行编码与解码的时候,我们要弄清楚,这个被操作的对象是谁?否则,出现编码问题的几率会大大增加。
4. unicode的深刻理解
unicode实际上是一种字符集,神奇之处在于所有语言的字符都用这一种字符集来表示,它是全人类都承认的一种统一标准。unicode映射了各种字符应该用哪种方式来表示,而没有指明具体的传输和储存方式,这个工作是由utf来完成的,如utf-8,utf-16。
5. 编码解码前后的差别
一个str类型的字节串解码后就成了unicode的字符串,相反,一个unicode类型的字符串解码后就成了str的字节串。
以下是我的实验代码:
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
country = '中国'
print type(country)
print country
country = country.decode('utf-8')
print type(country)
print country
country = country.encode('gbk')
print type(country)
print country
下面是执行结果:
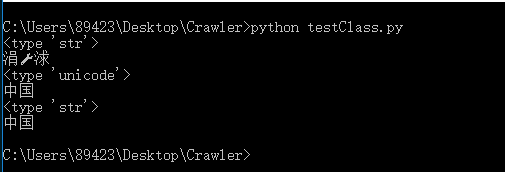
实验结果很好的验证了刚刚的结论。
6. 建议
6.1 更改文本编码格式
#coding:utf-8
6.2 更改程序默认编码格式
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
6.3 尽可能的采用unicode作为过渡,输出时编码为需要的编码格式
文/浅斟低唱