配置VIP实现MHA架构中主库故障自动切换
1.说明
引入keepalived实现MHA架构中主库master故障时,从库slave自动提升为新的maser
vip配置可以采用两种方式:
一种通过keepalived的方式管理虚拟ip的浮动;
另外一种通过脚本方式启动虚拟ip的方式(即不需要keepalived或者heartbeat类似的软件)。
此处先介绍通过安装keepalived来管理虚拟IP的浮动:
1.1下载软件安装keepalived
(两台master,准确的说一台是master,另外一台是备选master,在没有切换以前是slave)
在server02 192.168.2.128操作
1.1.1安装keepalived此处省略,可以参考文档:https://blog.51cto.com/wujianwei/2118499来安装
server03 192.168.2.129也要执行上面的操作,安装是一样的,只是配置文件不一样,这里不演示了。
1.2配置keepalived的配置文件
A、在master上配置(server02 192.168.2.128)操作如下:
[root@server02 scripts]# cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_01
}
vrrp_instance VI_1 {
#state MASTER
state BACKUP
interface eth1
virtual_router_id 51
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.100/24
}
}其中router_id LVS_01表示设定keepalived组的名称,将192.168.2.100这个虚拟ip绑定到该主机的eth1网卡上,并且设置了状态为backup模式,将keepalived的模式设置为非抢占模式(nopreempt),priority 150表示设置的优先级为150。下面的配置略有不同,但是都是一个意思。(还有一个细节要注意的,要看清楚自己的网卡是eth0做模拟VIP,还是eth1)
B、在候选master上配置(server03 192.168.2.129)操作如下:
[root@server03 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_02
}
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 120
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.2.100/24
}
}1.3启动keepalived服务
在master上启动并查看日志(server02 192.168.2.128)操作如下:
[root@server03 ~]# /etc/init.d/keepalived start
Starting keepalived: [ OK ]
[root@server03 ~]#
[root@server03 ~]# tail -100f /var/log/messages
Jul 1 14:42:05 slave01 Keepalived[42132]: Starting Keepalived v1.4.0 (12/29,2017)
Jul 1 14:42:05 slave01 Keepalived[42132]: Running on Linux 3.10.5-3.el6.x86_64 #1 SMP Tue Aug 20 14:10:49 UTC 2013 (built for Linux 2.6.32)
Jul 1 14:42:05 slave01 Keepalived[42132]: Opening file '/etc/keepalived/keepalived.conf'.
Jul 1 14:42:05 slave01 Keepalived[42133]: Starting Healthcheck child process, pid=42135
Jul 1 14:42:05 slave01 Keepalived[42133]: Starting VRRP child process, pid=42136
Jul 1 14:42:05 slave01 Keepalived_healthcheckers[42135]: Opening file '/etc/keepalived/keepalived.conf'.
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: Registering Kernel netlink reflector
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: Registering Kernel netlink command channel
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: Registering gratuitous ARP shared channel
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: Opening file '/etc/keepalived/keepalived.conf'.
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) removing protocol VIPs.
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: Using LinkWatch kernel netlink reflector...
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) Entering BACKUP STATE
Jul 1 14:42:05 slave01 Keepalived_vrrp[42136]: VRRP sockpool: [ifindex(3), proto(112), unicast(0), fd(10,11)]
Jul 1 14:42:52 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) Transition to MASTER STATE
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) Entering MASTER STATE
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) setting protocol VIPs.
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 192.168.2.100
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:53 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:58 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:58 slave01 Keepalived_vrrp[42136]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on eth1 for 192.168.2.100
Jul 1 14:42:58 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:58 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:58 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.100
Jul 1 14:42:58 slave01 Keepalived_vrrp[42136]: Sending gratuitous ARP on eth1 for 192.168.2.1001.4查看绑定情况
[root@server02 ~]# ip a|grep 192.168.2.100
inet 192.168.2.100/24 scope global secondary eth1
[root@server02 ~]# 发现已经将虚拟IP 192.168.2.100绑定了master02 192.168.2.128的网卡eth1上了
从上面的信息可以看到keepalived已经配置成功。
#####特别注意!!!!!
上面两台服务器的keepalived都设置为了BACKUP模式,在keepalived中2种模式,分别是master->backup模式和backup->backup模式。这两种模式有很大区别。在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。为了减少ip漂移次数,通常是把修复好的主库当做新的备库。
++++到此处MHA架构中keepalived服务安装配置完成++++
2、MHA引入keepalived
MySQL服务进程挂掉时通过MHA 停止keepalived:
要想把keepalived服务引入MHA,我们只需要修改切换是触发的脚本文件master_ip_failover即可,在该脚本中添加在master发生宕机时对keepalived的处理。
2.1准备故障切换脚本
编辑脚本/usr/local/bin/master_ip_failover,修改后如下(server04 192.168.2.130)操作:
failover脚本脚本内容如下:(采用的是keepalived 切换方式)
[root@server04 ~]# cat /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '192.168.2.100';
my $ssh_start_vip = "/etc/init.d/keepalived start";
my $ssh_stop_vip = "/etc/init.d/keepalived stop";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
#A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}####提示:
/usr/local/bin/master_ip_failover添加或者修改的内容意思是当主库数据库发生故障时,会触发MHA切换,MHA Manager会停掉主库上的keepalived服务,触发虚拟ip漂移到备选从库,从而完成切换。当然可以在keepalived里面引入脚本,这个脚本监控mysql是否正常运行,如果不正常,则调用该脚本杀掉keepalived进程。
2.2再次执行检查主从复制情况:
[root@server04 bin]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Sun Jul 1 15:05:08 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sun Jul 1 15:05:08 2018 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sun Jul 1 15:05:08 2018 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sun Jul 1 15:05:08 2018 - [info] MHA::MasterMonitor version 0.56.
Sun Jul 1 15:05:09 2018 - [info] GTID failover mode = 0
Sun Jul 1 15:05:09 2018 - [info] Dead Servers:
Sun Jul 1 15:05:09 2018 - [info] Alive Servers:
Sun Jul 1 15:05:09 2018 - [info] 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 15:05:09 2018 - [info] 192.168.2.129(192.168.2.129:3306)
Sun Jul 1 15:05:09 2018 - [info] 192.168.2.130(192.168.2.130:3306)
Sun Jul 1 15:05:09 2018 - [info] Alive Slaves:
Sun Jul 1 15:05:09 2018 - [info] 192.168.2.129(192.168.2.129:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 15:05:09 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 15:05:09 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Jul 1 15:05:09 2018 - [info] 192.168.2.130(192.168.2.130:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 15:05:09 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 15:05:09 2018 - [info] Current Alive Master: 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 15:05:09 2018 - [info] Checking slave configurations..
Sun Jul 1 15:05:09 2018 - [info] read_only=1 is not set on slave 192.168.2.129(192.168.2.129:3306).
Sun Jul 1 15:05:09 2018 - [info] Checking replication filtering settings..
Sun Jul 1 15:05:09 2018 - [info] binlog_do_db= , binlog_ignore_db=
Sun Jul 1 15:05:09 2018 - [info] Replication filtering check ok.
Sun Jul 1 15:05:09 2018 - [info] GTID (with auto-pos) is not supported
Sun Jul 1 15:05:09 2018 - [info] Starting SSH connection tests..
Sun Jul 1 15:05:10 2018 - [info] All SSH connection tests passed successfully.
Sun Jul 1 15:05:10 2018 - [info] Checking MHA Node version..
Sun Jul 1 15:05:11 2018 - [info] Version check ok.
Sun Jul 1 15:05:11 2018 - [info] Checking SSH publickey authentication settings on the current master..
Sun Jul 1 15:05:11 2018 - [info] HealthCheck: SSH to 192.168.2.128 is reachable.
Sun Jul 1 15:05:12 2018 - [info] Master MHA Node version is 0.56.
Sun Jul 1 15:05:12 2018 - [info] Checking recovery script configurations on 192.168.2.128(192.168.2.128:3306)..
Sun Jul 1 15:05:12 2018 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/data/mysql/logs/bin-log --output_file=/tmp/save_binary_logs_test --manager_version=0.56 --start_file=mysql-bin.000004
Sun Jul 1 15:05:12 2018 - [info] Connecting to [email protected](192.168.2.128:22)..
Creating /tmp if not exists.. ok.
Checking output directory is accessible or not..
ok.
Binlog found at /data/mysql/logs/bin-log, up to mysql-bin.000004
Sun Jul 1 15:05:12 2018 - [info] Binlog setting check done.
Sun Jul 1 15:05:12 2018 - [info] Checking SSH publickey authentication and checking recovery script configurations on all alive slave servers..
Sun Jul 1 15:05:12 2018 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='monitor' --slave_host=192.168.2.129 --slave_ip=192.168.2.129 --slave_port=3306 --workdir=/tmp --target_version=5.7.21-log --manager_version=0.56 --relay_log_info=/data/mysql/relay-log.info --relay_dir=/data/mysql/data/ --slave_pass=xxx
Sun Jul 1 15:05:12 2018 - [info] Connecting to [email protected](192.168.2.129:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql/logs/relay-log, up to relay-bin.000003
Temporary relay log file is /data/mysql/logs/relay-log/relay-bin.000003
Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Sun Jul 1 15:05:12 2018 - [info] Executing command : apply_diff_relay_logs --command=test --slave_user='monitor' --slave_host=192.168.2.130 --slave_ip=192.168.2.130 --slave_port=3306 --workdir=/tmp --target_version=5.7.21-log --manager_version=0.56 --relay_log_info=/data/mysql/relay-log.info --relay_dir=/data/mysql/data/ --slave_pass=xxx
Sun Jul 1 15:05:12 2018 - [info] Connecting to [email protected](192.168.2.130:22)..
Checking slave recovery environment settings..
Opening /data/mysql/relay-log.info ... ok.
Relay log found at /data/mysql/logs/relay-log, up to relay-bin.000003
Temporary relay log file is /data/mysql/logs/relay-log/relay-bin.000003
Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Sun Jul 1 15:05:13 2018 - [info] Slaves settings check done.
Sun Jul 1 15:05:13 2018 - [info]
192.168.2.128(192.168.2.128:3306) (current master)
+--192.168.2.129(192.168.2.129:3306)
+--192.168.2.130(192.168.2.130:3306)
Sun Jul 1 15:05:13 2018 - [info] Checking replication health on 192.168.2.129..
Sun Jul 1 15:05:13 2018 - [info] ok.
Sun Jul 1 15:05:13 2018 - [info] Checking replication health on 192.168.2.130..
Sun Jul 1 15:05:13 2018 - [info] ok.
Sun Jul 1 15:05:13 2018 - [info] Checking master_ip_failover_script status:
Sun Jul 1 15:05:13 2018 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.2.128 --orig_master_ip=192.168.2.128 --orig_master_port=3306
IN SCRIPT TEST====/etc/init.d/keepalived stop==/etc/init.d/keepalived start===
Checking the Status of the script.. OK
Sun Jul 1 15:05:13 2018 - [info] OK.
Sun Jul 1 15:05:13 2018 - [warning] shutdown_script is not defined.
Sun Jul 1 15:05:13 2018 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
[root@server04 bin]# 日志输出中会多出:
IN SCRIPT TEST====/etc/init.d/keepalived stop==/etc/init.d/keepalived start===
检测脚本是正常的
3.在monitor监控机器上设置邮件报警
当主库master挂掉的话,监控端会触发邮件报警,提示主库已经切换
监控节点192.168.2.130上操作:
[root@server04 bin]# grep report_script /etc/masterha/app1.cnf
report_script=/usr/local/bin/send_report**send_report这个脚本在安装好软件后就会有,这些脚本有很多地方不够完善,包括send_report的发邮件脚本,所以此脚本是需要修改的,涉及到一些敏感信息此处邮件报警脚本就不粘贴了。
4.故障模拟演示
4.1masterha_manager必须开启
检查下server04 92.168.2.130 机器masterha_manager是否开启,没开启的话一定要提前开启
[root@server03 masterha]# ps -ef|grep perl
root 47441 40702 0 15:28 pts/3 00:00:00 grep perl
所以要开启:
[root@server03 app1]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
[1] 47458
[root@server03 app1]# ps -ef|grep perl
root 47458 40702 0 15:29 pts/3 00:00:00 perl /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover
root 47604 40702 0 15:30 pts/3 00:00:00 grep perl查看日志成功开启:
[root@server04 app1.log]# tail -20f /var/log/masterha/app1/manager.log
Relay log found at /data/mysql/logs/relay-log, up to relay-bin.000005
Temporary relay log file is /data/mysql/logs/relay-log/relay-bin.000005
Testing mysql connection and privileges..mysql: [Warning] Using a password on the command line interface can be insecure.
done.
Testing mysqlbinlog output.. done.
Cleaning up test file(s).. done.
Sun Jul 1 15:29:59 2018 - [info] Slaves settings check done.
Sun Jul 1 15:29:59 2018 - [info]
192.168.2.128(192.168.2.128:3306) (current master)
+--192.168.2.129(192.168.2.129:3306)
+--192.168.2.130(192.168.2.130:3306)
Sun Jul 1 15:29:59 2018 - [info] Checking master_ip_failover_script status:
Sun Jul 1 15:29:59 2018 - [info] /usr/local/bin/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.2.128 --orig_master_ip=192.168.2.128 --orig_master_port=3306
Sun Jul 1 15:30:00 2018 - [info] OK.
Sun Jul 1 15:30:00 2018 - [warning] shutdown_script is not defined.
Sun Jul 1 15:30:00 2018 - [info] Set master ping interval 1 seconds.
Sun Jul 1 15:30:00 2018 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.2.128 --master_port=3306
Sun Jul 1 15:30:00 2018 - [info] Starting ping health check on 192.168.2.128(192.168.2.128:3306)..
Sun Jul 1 15:30:00 2018 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..4.2模拟主Master(192.168.2.128)down了:
pkill掉192.168.2.128机器mysql
[root@server02 ~]# pkill mysqld
[root@server03 masterha]# tailf /var/log/masterha/app1/manager.log
Sun Jul 1 17:04:27 2018 - [warning] Got error on MySQL select ping: 2006 (MySQL server has gone away)
Sun Jul 1 17:04:27 2018 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/data/mysql/logs/bin-log --output_file=/tmp/save_binary_logs_test --manager_version=0.56 --binlog_prefix=mysql-bin
Sun Jul 1 17:04:27 2018 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.2.128 --master_port=3306 --user=root --master_host=192.168.2.128 --master_ip=192.168.2.128 --master_port=3306 --master_user=monitor --master_password=123456 --ping_type=SELECT
Monitoring server server03 is reachable, Master is not reachable from server03. OK.
Sun Jul 1 17:04:28 2018 - [info] HealthCheck: SSH to 192.168.2.128 is reachable.
Monitoring server server02 is reachable, Master is not reachable from server02. OK.
Sun Jul 1 17:04:28 2018 - [info] Master is not reachable from all other monitoring servers. Failover should start.
Sun Jul 1 17:04:28 2018 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at 'reading initial communication packet', system error: 111)
Sun Jul 1 17:04:28 2018 - [warning] Connection failed 2 time(s)..
Sun Jul 1 17:04:29 2018 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at 'reading initial communication packet', system error: 111)
Sun Jul 1 17:04:29 2018 - [warning] Connection failed 3 time(s)..
Sun Jul 1 17:04:30 2018 - [warning] Got error on MySQL connect: 2013 (Lost connection to MySQL server at 'reading initial communication packet', system error: 111)
Sun Jul 1 17:04:30 2018 - [warning] Connection failed 4 time(s)..
Sun Jul 1 17:04:30 2018 - [warning] Master is not reachable from health checker!
Sun Jul 1 17:04:30 2018 - [warning] Master 192.168.2.128(192.168.2.128:3306) is not reachable!
Sun Jul 1 17:04:30 2018 - [warning] SSH is reachable.
Sun Jul 1 17:04:30 2018 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/masterha/app1.cnf again, and trying to connect to all servers to check server status..
Sun Jul 1 17:04:30 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sun Jul 1 17:04:30 2018 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sun Jul 1 17:04:30 2018 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sun Jul 1 17:04:31 2018 - [info] GTID failover mode = 0
Sun Jul 1 17:04:31 2018 - [info] Dead Servers:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Alive Servers:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.129(192.168.2.129:3306)
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.130(192.168.2.130:3306)
Sun Jul 1 17:04:31 2018 - [info] Alive Slaves:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.129(192.168.2.129:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.130(192.168.2.130:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Checking slave configurations..
Sun Jul 1 17:04:31 2018 - [info] read_only=1 is not set on slave 192.168.2.129(192.168.2.129:3306).
Sun Jul 1 17:04:31 2018 - [info] Checking replication filtering settings..
Sun Jul 1 17:04:31 2018 - [info] Replication filtering check ok.
Sun Jul 1 17:04:31 2018 - [info] Master is down!
Sun Jul 1 17:04:31 2018 - [info] Terminating monitoring script.
Sun Jul 1 17:04:31 2018 - [info] Got exit code 20 (Master dead).
Sun Jul 1 17:04:31 2018 - [info] MHA::MasterFailover version 0.56.
Sun Jul 1 17:04:31 2018 - [info] Starting master failover.
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] * Phase 1: Configuration Check Phase..
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] GTID failover mode = 0
Sun Jul 1 17:04:31 2018 - [info] Dead Servers:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Checking master reachability via MySQL(double check)...
Sun Jul 1 17:04:31 2018 - [info] ok.
Sun Jul 1 17:04:31 2018 - [info] Alive Servers:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.129(192.168.2.129:3306)
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.130(192.168.2.130:3306)
Sun Jul 1 17:04:31 2018 - [info] Alive Slaves:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.129(192.168.2.129:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.130(192.168.2.130:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Starting Non-GTID based failover.
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] ** Phase 1: Configuration Check Phase completed.
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] * Phase 2: Dead Master Shutdown Phase..
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] Forcing shutdown so that applications never connect to the current master..
Sun Jul 1 17:04:31 2018 - [info] Executing master IP deactivation script:
Sun Jul 1 17:04:31 2018 - [info] /usr/local/bin/master_ip_failover --orig_master_host=192.168.2.128 --orig_master_ip=192.168.2.128 --orig_master_port=3306 --command=stopssh --ssh_user=root
Sun Jul 1 17:04:31 2018 - [info] done.
Sun Jul 1 17:04:31 2018 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Sun Jul 1 17:04:31 2018 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] * Phase 3: Master Recovery Phase..
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] The latest binary log file/position on all slaves is mysql-bin.000006:154
Sun Jul 1 17:04:31 2018 - [info] Latest slaves (Slaves that received relay log files to the latest):
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.129(192.168.2.129:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.130(192.168.2.130:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] The oldest binary log file/position on all slaves is mysql-bin.000006:154
Sun Jul 1 17:04:31 2018 - [info] Oldest slaves:
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.129(192.168.2.129:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Jul 1 17:04:31 2018 - [info] 192.168.2.130(192.168.2.130:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:31 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase..
Sun Jul 1 17:04:31 2018 - [info]
Sun Jul 1 17:04:31 2018 - [info] Fetching dead master's binary logs..
Sun Jul 1 17:04:31 2018 - [info] Executing command on the dead master 192.168.2.128(192.168.2.128:3306): save_binary_logs --command=save --start_file=mysql-bin.000006 --start_pos=154 --binlog_dir=/data/mysql/logs/bin-log --output_file=/tmp/saved_master_binlog_from_192.168.2.128_3306_20180701170431.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.56
Creating /tmp if not exists.. ok.
Concat binary/relay logs from mysql-bin.000006 pos 154 to mysql-bin.000006 EOF into /tmp/saved_master_binlog_from_192.168.2.128_3306_20180701170431.binlog ..
Binlog Checksum enabled
Dumping binlog format description event, from position 0 to 154.. ok.
No need to dump effective binlog data from /data/mysql/logs/bin-log/mysql-bin.000006 (pos starts 154, filesize 154). Skipping.
Binlog Checksum enabled
/tmp/saved_master_binlog_from_192.168.2.128_3306_20180701170431.binlog has no effective data events.
Event not exists.
Sun Jul 1 17:04:32 2018 - [info] Additional events were not found from the orig master. No need to save.
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 3.3: Determining New Master Phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] Finding the latest slave that has all relay logs for recovering other slaves..
Sun Jul 1 17:04:32 2018 - [info] All slaves received relay logs to the same position. No need to resync each other.
Sun Jul 1 17:04:32 2018 - [info] Searching new master from slaves..
Sun Jul 1 17:04:32 2018 - [info] Candidate masters from the configuration file:
Sun Jul 1 17:04:32 2018 - [info] 192.168.2.129(192.168.2.129:3306) Version=5.7.21-log (oldest major version between slaves) log-bin:enabled
Sun Jul 1 17:04:32 2018 - [info] Replicating from 192.168.2.128(192.168.2.128:3306)
Sun Jul 1 17:04:32 2018 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Jul 1 17:04:32 2018 - [info] Non-candidate masters:
Sun Jul 1 17:04:32 2018 - [info] Searching from candidate_master slaves which have received the latest relay log events..
Sun Jul 1 17:04:32 2018 - [info] New master is 192.168.2.129(192.168.2.129:3306)
Sun Jul 1 17:04:32 2018 - [info] Starting master failover..
Sun Jul 1 17:04:32 2018 - [info]
From:
192.168.2.128(192.168.2.128:3306) (current master)
+--192.168.2.129(192.168.2.129:3306)
+--192.168.2.130(192.168.2.130:3306)
To:
192.168.2.129(192.168.2.129:3306) (new master)
+--192.168.2.130(192.168.2.130:3306)
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 3.3: New Master Diff Log Generation Phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 3.4: Master Log Apply Phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed.
Sun Jul 1 17:04:32 2018 - [info] Starting recovery on 192.168.2.129(192.168.2.129:3306)..
Sun Jul 1 17:04:32 2018 - [info] This server has all relay logs. Waiting all logs to be applied..
Sun Jul 1 17:04:32 2018 - [info] done.
Sun Jul 1 17:04:32 2018 - [info] All relay logs were successfully applied.
Sun Jul 1 17:04:32 2018 - [info] Getting new master's binlog name and position..
Sun Jul 1 17:04:32 2018 - [info] mysql-bin.000003:154
Sun Jul 1 17:04:32 2018 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.2.129', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=154, MASTER_USER='repmha', MASTER_PASSWORD='xxx';
Sun Jul 1 17:04:32 2018 - [info] Executing master IP activate script:
Sun Jul 1 17:04:32 2018 - [info] /usr/local/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.2.128 --orig_master_ip=192.168.2.128 --orig_master_port=3306 --new_master_host=192.168.2.129 --new_master_ip=192.168.2.129 --new_master_port=3306 --new_master_user='monitor' --new_master_password='123456'
Undefined subroutine &main::FIXME_xxx_create_user called at /usr/local/bin/master_ip_failover line 88.
Set read_only=0 on the new master.
Creating app user on the new master..
Sun Jul 1 17:04:32 2018 - [error][/usr/share/perl5/vendor_perl/MHA/MasterFailover.pm, ln1588] Failed to activate master IP address for 192.168.2.129(192.168.2.129:3306) with return code 10:0
Sun Jul 1 17:04:32 2018 - [warning] Proceeding.
Sun Jul 1 17:04:32 2018 - [info] ** Finished master recovery successfully.
Sun Jul 1 17:04:32 2018 - [info] * Phase 3: Master Recovery Phase completed.
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 4: Slaves Recovery Phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] -- Slave diff file generation on host 192.168.2.130(192.168.2.130:3306) started, pid: 49563. Check tmp log /var/log/masterha/app1.log/192.168.2.130_3306_20180701170431.log if it takes time..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] Log messages from 192.168.2.130 ...
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Sun Jul 1 17:04:32 2018 - [info] End of log messages from 192.168.2.130.
Sun Jul 1 17:04:32 2018 - [info] -- 192.168.2.130(192.168.2.130:3306) has the latest relay log events.
Sun Jul 1 17:04:32 2018 - [info] Generating relay diff files from the latest slave succeeded.
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] -- Slave recovery on host 192.168.2.130(192.168.2.130:3306) started, pid: 49565. Check tmp log /var/log/masterha/app1.log/192.168.2.130_3306_20180701170431.log if it takes time..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] Log messages from 192.168.2.130 ...
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] Starting recovery on 192.168.2.130(192.168.2.130:3306)..
Sun Jul 1 17:04:32 2018 - [info] This server has all relay logs. Waiting all logs to be applied..
Sun Jul 1 17:04:32 2018 - [info] done.
Sun Jul 1 17:04:32 2018 - [info] All relay logs were successfully applied.
Sun Jul 1 17:04:32 2018 - [info] Resetting slave 192.168.2.130(192.168.2.130:3306) and starting replication from the new master 192.168.2.129(192.168.2.129:3306)..
Sun Jul 1 17:04:32 2018 - [info] Executed CHANGE MASTER.
Sun Jul 1 17:04:32 2018 - [info] Slave started.
Sun Jul 1 17:04:32 2018 - [info] End of log messages from 192.168.2.130.
Sun Jul 1 17:04:32 2018 - [info] -- Slave recovery on host 192.168.2.130(192.168.2.130:3306) succeeded.
Sun Jul 1 17:04:32 2018 - [info] All new slave servers recovered successfully.
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] * Phase 5: New master cleanup phase..
Sun Jul 1 17:04:32 2018 - [info]
Sun Jul 1 17:04:32 2018 - [info] Resetting slave info on the new master..
Sun Jul 1 17:04:32 2018 - [info] 192.168.2.129: Resetting slave info succeeded.
Sun Jul 1 17:04:32 2018 - [info] Master failover to 192.168.2.129(192.168.2.129:3306) completed successfully.
Sun Jul 1 17:04:32 2018 - [info] Deleted server1 entry from /etc/masterha/app1.cnf .
Sun Jul 1 17:04:32 2018 - [info]
----- Failover Report -----
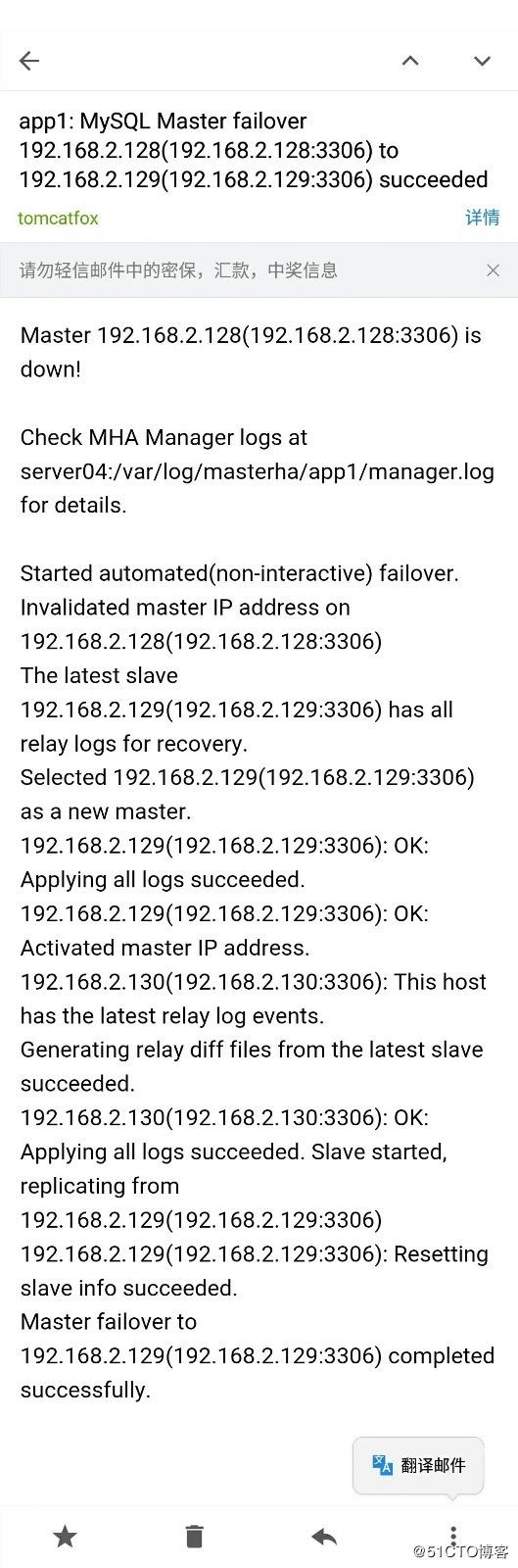
app1: MySQL Master failover 192.168.2.128(192.168.2.128:3306) to 192.168.2.129(192.168.2.129:3306) succeeded
Master 192.168.2.128(192.168.2.128:3306) is down!
Check MHA Manager logs at server04:/var/log/masterha/app1/manager.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.2.128(192.168.2.128:3306)
The latest slave 192.168.2.129(192.168.2.129:3306) has all relay logs for recovery.
Selected 192.168.2.129(192.168.2.129:3306) as a new master.
192.168.2.129(192.168.2.129:3306): OK: Applying all logs succeeded.
Failed to activate master IP address for 192.168.2.129(192.168.2.129:3306) with return code 10:0
192.168.2.130(192.168.2.130:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.2.130(192.168.2.130:3306): OK: Applying all logs succeeded. Slave started, replicating from 192.168.2.129(192.168.2.129:3306)
192.168.2.129(192.168.2.129:3306): Resetting slave info succeeded.
Master failover to 192.168.2.129(192.168.2.129:3306) completed successfully.
Sun Jul 1 17:04:32 2018 - [info] Sending mail..
Unknown option: conf从日志中查看数据库已经成功切换完成了,邮箱收到邮件提示数据库切换成功了
邮件内容如下:
5.检查故障切换后MHA集群相关服务的变化
5.1配置文件/etc/masterha/app1.cnf变化
在server04 192.168.2.130管理节点查看一下配置文件/etc/masterha/app1.cnf可以发现[server1]的内容已经被自动去掉了:
[root@server03 masterha]# cat /etc/masterha/app1.cnf
[server default]
manager_log=/var/log/masterha/app1/manager.log
manager_workdir=/var/log/masterha/app1.log
master_binlog_dir=/data/mysql/logs/bin-log
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
password=123456
ping_interval=1
remote_workdir=/tmp
repl_password=123456
repl_user=repmha
report_script=/usr/local/bin/send_report
secondary_check_script=/usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.2.128 --master_port=3306
shutdown_script=""
ssh_port=10280
ssh_user=root
user=monitor
[server2]
candidate_master=1
check_repl_delay=0
hostname=192.168.2.129
port=3306
[server3]
hostname=192.168.2.130
port=3306
You have new mail in /var/spool/mail/root
[root@server03 masterha]# 5.2.masterha_manager 服务自动退出
5.3源master192.168.2.128机器上keepalived服务被停掉了
[root@server02 ~]# ps -ef|grep keep*
192.168.2.129上停掉的keepalived被启动了
VIP漂移到了192.168.2.129 机器
[root@server03 ~]# ip a|grep 192.168.2.100
inet 192.168.2.100/24 scope global secondary eth1#######重要提示!!!
当server02 192.168.2.128 机器上的mysql挂掉后,server03 192.168.2.129机器提升为master时,192.168.2.128 机器上的keepalived会停掉,而 192.168.2.129机器的keepalived会开启,VIP票到129机器上。
此时需要重启192.168.2.128上的mysql,一般都是要恢复它作为129新主的从库,此时192.168.2.128机器上的keepalived千万不要开启,因为开启keepalived,会抢占129机器上的VIP,导致程序连接数据库出现混乱。同时192.168.2.128机器和192.168.2.129机器上的keepalived服务不要设置为开机自启动
6.MHA集群支持ssh端口不是默认22端口
修改服务器的端口为10280 ,MHA也是支持的,它自动切换默认的密码是22
MHA监控端的配置文件,配置ssh端口为10280
[root@server04 masterha]#grep 10280 /etc/masterha/app1.cnf
ssh_port=10280故障切换脚本中添加-p10280
[root@server04 masterha]# grep 10280 /usr/local/bin/master_ip_failover
`ssh -p10280 $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
`ssh -p10280 $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;##########
修改此处默认的22端口为10280
[root@server04 masterha]# grep 10280 /usr/local/bin/masterha_secondary_check
$ssh_port = 10280 unless ($ssh_port);开启MHA监控:
#######
[root@server04 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1 &
#########MHA+keepalived方案到此处演示完毕了,博主能力有限,如有不对的地方,希望指正,不喜勿喷