一、Java8流的引入
对于Java的开发者来说,Java集合的使用是再熟悉不过了。几乎每个Java应用里面都或多或少的会制造和处理集合。但在Java8之前对于集合的操作并不是那么的完美,许多时候你需要书写很多的重复代码来实现对集合的操作,所以Java8引用了流的概念来帮你更优雅的处理集合。
二、流是什么
流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不
是临时编写一个实现)。此外,流还可以透明地并行处理,你无需写任何多线程代码了。(引用《Java8实战》)
此处以Phone类作为通用的模型,来进行说明。
public class Phone {
private final String version; //手机型号
private final String manufacturer; //制造厂商
private final int price; //价格
private final boolean isSupport5G; //是否支持5G
private final Type type; //手机目标人群
public Phone(String version, String manufacturer, int price, boolean isSupport5G, Type type) {
this.version = version;
this.manufacturer = manufacturer;
this.price = price;
this.isSupport5G = isSupport5G;
this.type = type;
}
public String getManufacturer() {
return manufacturer;
}
public int getPrice() {
return price;
}
public boolean isSupport5G() {
return isSupport5G;
}
public Type getType() {
return type;
}
public String getVersion() {
return version;
}
//手机适合的人群类型
public enum Type{
BUSINESSMAN, //商务人士
TEENAGES, //青年
OLDPEOPLE, //老年人
PUBLICPEOPLE, //大众
}
}
假设你需要找出价格低于2000的手机的手机型号,并按照价格进行排序:
(1)使用Java7:
List priceLessThan2000 = new ArrayList<>();
for(Phone phone : Data.phones){
if (phone.getPrice() < 2000) {
priceLessThan2000.add(phone);
}
}
Collections.sort(priceLessThan2000, new Comparator() {
@Override
public int compare(Phone o1, Phone o2) {
return Integer.compare(o1.getPrice(),o2.getPrice());
}
});
List versions = new ArrayList<>();
for(Phone phone : priceLessThan2000){
versions.add(phone.getVersion());
}
(2)使用Java8:
List priceLessThan2000Names_By8 = Data.phones.stream()
.filter(d -> d.getPrice() < 2000)
.sorted(Comparator.comparing(Phone::getPrice))
.map(Phone::getVersion)
.collect(toList());
使用Java8来实现的代码与Java7有很大区别:
1、代码以声明式方式写的:直接说明了这段代码想要完成什么功能,而不是如何实现一个操作(利用循环和if等控制语句)
2、通过把几个基础操作连接起来,来说明复杂的数据处理流水线。filter结果传给sorted方法,再传map方法,最后传collect
三、流简介
从集合入手来了解流,Java 8中的集合支持一个新的stream方法,它会返回一个流(接口定义在java.util.stream.Stream里)。
流到底是什么?(以下引用《Java8实战》)简短的定义就是“从支持数据处理操作的源生成的元素序列”。
(1)元素序列——就像集合一样,流也提供了一个接口,可以访问特定元素类型的一组有序
值。因为集合是数据结构,所以它的主要目的是以特定的时间/空间复杂度存储和访问元素(如ArrayList 与 LinkedList)。但流的目的在于表达计算,集合讲的是数据,流讲的是计算。
(2)源——流会使用一个提供数据的源,如集合、数组或输入/输出资源。 请注意,从有序集合生成流时会保留原有的顺序。由列表生成的流,其元素顺序与列表一致。
(3)数据处理操作——流的数据处理功能支持类似于数据库的操作,以及函数式编程语言中
的常用操作,如filter、map、reduce、find、match、sort等。流操作可以顺序执行,也可并行执行。
(4)流水线——很多流操作本身会返回一个流,这样多个操作就可以链接起来,形成一个大
的流水线。流水线的操作可以看作对数据源进行数据库式查询
(5)内部迭代——与使用迭代器显式迭代的集合不同,流的迭代操作是在背后进行的。
看这一段代码:
List threeHighPhones = Data.phones.stream()//从手机列表里获取流,建立操作流水线
.filter( d -> d.getPrice() > 2000)//首先选出价钱高于2000的手机
.map(Phone::getVersion)//获取手机型号
.limit(3)//只选择头三个
.collect(toList());//将结果保存在另一个List里面
在这个例子中,一开始对phones这个手机集合调用stream方法,得到一个流。数据源是手机列表,它给流提供一个元素序列。接下来,对流应用一系列数据处理操作:filter、map,limit和collect。除了collect之外,所有这些操作都会返回另一个流,这样它们就可以接成一条流水线,于是就可以看作对源的一个查询。最后,collect操作开始处理流水线,并返回结果(它和别的操作不一样,因为它返回的不是流,在这里是一个List)。在调用collect之前,没有任何结果产生,实际上根本就没有从phones里选择元素。你可以这么理解:链中的方法调用都在排队等待,直到调用collect。
下图为整体流的操作顺序:

(1)filter——接受Lambda,从流中排除某些元素。在本例中,通过传递lambda d -> d.getPrice() > 2000,选择手机价钱高于2000的手机
(2)map——接受一个Lambda,将元素转换成其他形式或提取信息。在本例中,通过传递方法引用Phone::getVersion,相当于Lambda d -> d.getVersion,提取了每部手机的型号
(3)limit——截断流,使其元素不超过给定数量。
(4)collect——将流转换为其他形式。在本例中,流被转换为一个列表。你可以把collect看作能够接受各种方案作为参数,并将流中的元素累积成为一个汇总结果的操作。这里toList()就是将流转换为列表的方案
刚刚这段代码,与逐项处理手机列表的代码有很大不同。首先,我们
使用了声明性的方式来处理手机数据,即你说的对这些数据需要做什么:“查找价格高于2000的三部手机的型号。”你并没有去实现筛选(filter)、提取(map)或截断(limit)功能Streams库已经自带了。因此,Stream API在决定如何优化这条流水线时更为灵活。例如,筛选、提取和截断操作可以一次进行,并在找到这三部手机后立即停止。
只能遍历一次
流只能遍历一次。遍历完之后,我们就说这个流已经被消费掉了。你可以从原始数据源那里再获得一个新的流来重新遍历一遍,就像迭代器一样。例如,以下代码会抛出一个异常,说流已被消费掉了:
List title = Arrays.asList("1","2","3");
Stream stringStream = title.stream();
stringStream.forEach(System.out::println);
stringStream.forEach(System.out::println); //抛出错误,java.lang.IllegalStateException:流已被操作或关闭
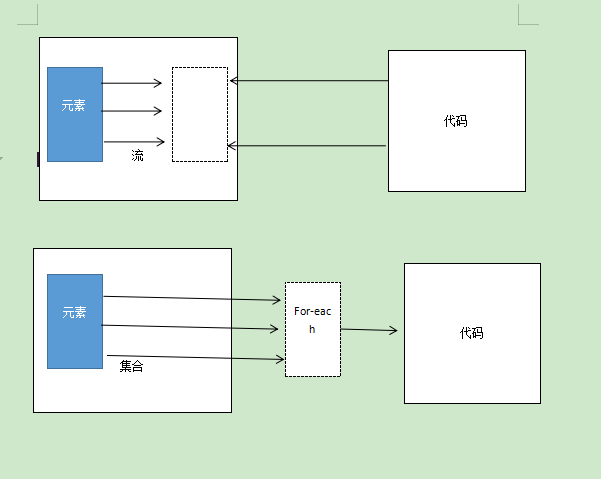
外部迭代与内部迭代
集合和流的另一个关键区别在于它们遍历数据的方式。
使用Collection接口需要用户去做迭代(比如用for-each),这称为外部迭代。 相反,Streams库使用内部迭代——它帮你把迭代做了,还把得到的流值存在了某个地方,你只要给出一个函数说要干什么就可以了
集合:用for-each循环外部迭代:
List names = new ArrayList<>();
for(Phone phone : Data.phones){//显示迭代手机列表
names.add(phone.getVersion());//把型号添加进集合
}
流:内部迭代:
List names_ = Data.phones.stream()
.map(Phone::getVersion)
.collect(toList());
内部迭代与外部迭代(来自《Java8实战》):
流操作
Stream接口定义了许多操作。它们可以分为两大类。
(1)filter、map和limit可以连成一条流水线
(2)collect触发流水线执行并关闭它
可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作
中间操作
等中间操作会返回另一个流。这让多个操作可以连接起来形成一个查
询。重要的是,除非流水线上触发一个终端操作,否则中间操作不会执行任何处理——它们很懒。这是因为中间操作一般都可以合并起来,在终端操作时一次性全部处理(引自《Java8实战》)
看这段代码:
List names = Data.phones.stream()
.filter(d -> {
System.out.println("Filtering : " + d.getVersion());
return d.getPrice() < 2000;
})
.map(d -> {
System.out.println("Maping : " + d.getVersion());
return d.getVersion();
})
.limit(3)
.collect(Collectors.toList());
执行后打印:
Filtering : 红米7
Maping : 红米7
Filtering : 小米8
Filtering : 魅蓝6
Maping : 魅蓝6
Filtering : 诺基亚N9
Maping : 诺基亚N9
[红米7, 魅蓝6, 诺基亚N9]
(1)只选出了前三个符合条件的手机型号!
(2)filter和map是两个独立的操作,但它们合并到同一次遍历中了。
终端操作
终端操作会从流的流水线生成结果。其结果是任何不是流的值,比如List、Integer,甚
至void。
如:在下面的流水线中,forEach是一个返回void的终端操作,它会对源中的每道
菜应用一个Lambda。
Data.phones.stream().forEach(System.out::println);
使用流
筛选和切片
用谓词筛选
Streams接口支持filter方法。该操作会接受一个谓词(一个返回boolean的函数)作为参数,并返回一个包括所有符合谓词的元素的流。
filter方法源码:
/**
* Returns a stream consisting of the elements of this stream that match
* the given predicate.
*
* This is an intermediate
* operation.
*
* @param predicate a non-interfering,
* stateless
* predicate to apply to each element to determine if it
* should be included
* @return the new stream
*/
Stream filter(Predicate predicate);
Predicate的意思是:谓语。该方法会返回一个新的对应的流,该流包含了与所给谓语匹配的元素,该操作是一个中间操作(intermediate operation)。
从手机列表中筛选支持5G的手机:
List phoneSupported5G = Data.phones.stream()
.filter(Phone::isSupport5G)
.collect(Collectors.toList());
筛选各异的元素
流还支持一个叫作distinct的方法,它会返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流
distinct方法源码:
/**
* Returns a stream consisting of the distinct elements (according to
* {@link Object#equals(Object)}) of this stream.
*
* For ordered streams, the selection of distinct elements is stable
* (for duplicated elements, the element appearing first in the encounter
* order is preserved.) For unordered streams, no stability guarantees
* are made.
*
*
This is a stateful
* intermediate operation.
*
* @apiNote
* Preserving stability for {@code distinct()} in parallel pipelines is
* relatively expensive (requires that the operation act as a full barrier,
* with substantial buffering overhead), and stability is often not needed.
* Using an unordered stream source (such as {@link #generate(Supplier)})
* or removing the ordering constraint with {@link #unordered()} may result
* in significantly more efficient execution for {@code distinct()} in parallel
* pipelines, if the semantics of your situation permit. If consistency
* with encounter order is required, and you are experiencing poor performance
* or memory utilization with {@code distinct()} in parallel pipelines,
* switching to sequential execution with {@link #sequential()} may improve
* performance.
*
* @return the new stream
*/
Stream distinct();
该方法属于中间操作,会返回一个新的流,包含了独一无二的元素。
以下代码筛选出列表中所有的偶数,并确保没有重复。
List numbers = Arrays.asList(1,2,5,9,4,4,8,9,5);
numbers.stream()
.filter( i -> i % 2 == 0)
.distinct()
.forEach(System.out::println);
截短流
流支持limit(n)方法,该方法会返回一个不超过给定长度的流。所需的长度作为参数传递
给limit。如果流是有序的,则最多会返回前n个元素
limit方法源码:
/**
* Returns a stream consisting of the elements of this stream, truncated
* to be no longer than {@code maxSize} in length.
*
* This is a short-circuiting
* stateful intermediate operation.
*
* @apiNote
* While {@code limit()} is generally a cheap operation on sequential
* stream pipelines, it can be quite expensive on ordered parallel pipelines,
* especially for large values of {@code maxSize}, since {@code limit(n)}
* is constrained to return not just any n elements, but the
* first n elements in the encounter order. Using an unordered
* stream source (such as {@link #generate(Supplier)}) or removing the
* ordering constraint with {@link #unordered()} may result in significant
* speedups of {@code limit()} in parallel pipelines, if the semantics of
* your situation permit. If consistency with encounter order is required,
* and you are experiencing poor performance or memory utilization with
* {@code limit()} in parallel pipelines, switching to sequential execution
* with {@link #sequential()} may improve performance.
*
* @param maxSize the number of elements the stream should be limited to
* @return the new stream
* @throws IllegalArgumentException if {@code maxSize} is negative
*/
Stream limit(long maxSize);
该方法属于中间操作,会返回一个新的流,里面包含的元素的个数不会超过所给参数的大小。
找出前三个价格高于2000的手机:
List phones = Data.phones.stream()
.filter( d -> d.getPrice() > 2000)
.limit(3)
.collect(Collectors.toList());
跳过元素
流还支持skip(n)方法,返回一个扔掉了前n个元素的流。如果流中元素不足n个,则返回一
个空流
skip方法源码:
/**
* Returns a stream consisting of the remaining elements of this stream
* after discarding the first {@code n} elements of the stream.
* If this stream contains fewer than {@code n} elements then an
* empty stream will be returned.
*
* This is a stateful
* intermediate operation.
*
* @apiNote
* While {@code skip()} is generally a cheap operation on sequential
* stream pipelines, it can be quite expensive on ordered parallel pipelines,
* especially for large values of {@code n}, since {@code skip(n)}
* is constrained to skip not just any n elements, but the
* first n elements in the encounter order. Using an unordered
* stream source (such as {@link #generate(Supplier)}) or removing the
* ordering constraint with {@link #unordered()} may result in significant
* speedups of {@code skip()} in parallel pipelines, if the semantics of
* your situation permit. If consistency with encounter order is required,
* and you are experiencing poor performance or memory utilization with
* {@code skip()} in parallel pipelines, switching to sequential execution
* with {@link #sequential()} may improve performance.
*
* @param n the number of leading elements to skip
* @return the new stream
* @throws IllegalArgumentException if {@code n} is negative
*/
Stream skip(long n);
该方法属于中间操作,它会返回全新的流,这个流会把前n个元素去除掉,如果原来的流中元素个数不足n个,则返回一个空的流。
先选出价格高于2000的手机,然后跳过前两个
List phones_skip = Data.phones.stream()
.filter( d -> d.getPrice() > 2000)
.skip(2)
.collect(Collectors.toList());
映射
对流中每一个元素应用函数
流支持map方法,它会接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”)(引自《Java8实战》)
以下代码用于提取手机的型号:
List names = Data.phones.stream()
.map(Phone::getVersion)
.collect(Collectors.toList());
因为getVersion方法返回一个String,所以map方法输出的流的类型就是Stream
map方法源码:
/**
* Returns a stream consisting of the results of applying the given
* function to the elements of this stream.
*
* This is an intermediate
* operation.
*
* @param The element type of the new stream
* @param mapper a non-interfering,
* stateless
* function to apply to each element
* @return the new stream
*/
Stream map(Function mapper);
该方法是一个中间操作,返回一个新的流,该流包含了使用参数中所给函数之后得到的结果。
流的扁平化
假设对于一个单词字符串的集合,想要找出各不相同的字符。(例子来源于《Java8实战》)
Version1:
words.stream()
.map(word -> word.split(""))
.distinct()
.collect(Collectors.toList());
这个方法的问题在于,传递给map方法的Lambda为每个单词返回了一个String[](String
列表)。因此,map返回的流实际上是Stream
Stream
尝试解决:
使用map和Arrays.stream():
首先,你需要一个字符流,而不是数组流。有一个叫作Arrays.stream()的方法可以接受
一个数组并产生一个流,如:
String[] arrayOfWords = {"Goodbye", "World"};
Stream streamOfwords = Arrays.stream(arrayOfWords);
按照前面例子实现:
words.stream()
.map(word -> word.split(""))
.map(Arrays::stream)
.distinct()
.collect(toList());
当前的解决方案仍然搞不定!这是因为,你现在得到的是一个流的列表(更准确地说是
Stream
最终方案(使用flatMap):
List uniqueCharacters =
words.stream()
.map(w -> w.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(Collectors.toList());
使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所
有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流
总之,flatmap方法让你把一个流中的每个值都换成另一个流,然后把所有的流连接
起来成为一个流。
查找和匹配
检查谓词是否至少匹配一个元素
比如可以用来查找手机列表里面是否有手机支持5G:
if (Data.phones.stream()
.anyMatch(Phone::isSupport5G)) {
System.out.println("有手机支持5G");
}
anyMatch方法源码:
/**
* Returns whether any elements of this stream match the provided
* predicate. May not evaluate the predicate on all elements if not
* necessary for determining the result. If the stream is empty then
* {@code false} is returned and the predicate is not evaluated.
*
* This is a short-circuiting
* terminal operation.
*
* @apiNote
* This method evaluates the existential quantification of the
* predicate over the elements of the stream (for some x P(x)).
*
* @param predicate a non-interfering,
* stateless
* predicate to apply to elements of this stream
* @return {@code true} if any elements of the stream match the provided
* predicate, otherwise {@code false}
*/
boolean anyMatch(Predicate predicate);
该方法是一个终端操作,返回一个布尔值。如果流里面有任何一个元素能够匹配的所给参数谓语,那么就返回true;否则返回false。
检查谓词是否匹配所有元素
以下代码如果手机列表中的手机都支持5G则打印输出:
if(Data.phones.stream()
.allMatch(Phone::isSupport5G)){
System.out.println("都支持5G");
}
allMatch方法源码:
/**
* Returns whether all elements of this stream match the provided predicate.
* May not evaluate the predicate on all elements if not necessary for
* determining the result. If the stream is empty then {@code true} is
* returned and the predicate is not evaluated.
*
* This is a short-circuiting
* terminal operation.
*
* @apiNote
* This method evaluates the universal quantification of the
* predicate over the elements of the stream (for all x P(x)). If the
* stream is empty, the quantification is said to be vacuously
* satisfied and is always {@code true} (regardless of P(x)).
*
* @param predicate a non-interfering,
* stateless
* predicate to apply to elements of this stream
* @return {@code true} if either all elements of the stream match the
* provided predicate or the stream is empty, otherwise {@code false}
*/
boolean allMatch(Predicate predicate);
该方法是一个终端操作,返回布尔值。如果流中所有元素都匹配所给谓语,那么返回true;否则返回false。
查找元素
findAny方法将返回当前流中的任意元素。它可以与其他流操作结合使用。
以下代码在手机列表中查找支持5G的手机:
Optional phone = Data.phones.stream()
.filter(Phone::isSupport5G)
.findAny();
findAny方法源码:
/**
* Returns an {@link Optional} describing some element of the stream, or an
* empty {@code Optional} if the stream is empty.
*
* This is a short-circuiting
* terminal operation.
*
*
The behavior of this operation is explicitly nondeterministic; it is
* free to select any element in the stream. This is to allow for maximal
* performance in parallel operations; the cost is that multiple invocations
* on the same source may not return the same result. (If a stable result
* is desired, use {@link #findFirst()} instead.)
*
* @return an {@code Optional} describing some element of this stream, or an
* empty {@code Optional} if the stream is empty
* @throws NullPointerException if the element selected is null
* @see #findFirst()
*/
Optional findAny();
该方法是一个终端操作,返回一个Optional类,里面包含了一些符合前面流操作之后的元素。或者返回一个空的Optional类,如果流是空的话。
查找第一个元素
有些流有一个出现顺序(encounter order)来指定流中项目出现的逻辑顺序(比如由List或排序好的数据列生成的流)。对于这种流,如果想要找到第一个元素,你可以使用findFirst方法。
以下代码能找出第一个平方能被3整除的数:
List someNums = Arrays.asList(1,2,3,4,5,6,7,8,9);
Optional f = someNums.stream()
.map( x -> x * x)
.filter( x -> x % 3 == 0)
.findFirst();
findFirst方法源码:
/**
* Returns an {@link Optional} describing the first element of this stream,
* or an empty {@code Optional} if the stream is empty. If the stream has
* no encounter order, then any element may be returned.
*
* This is a short-circuiting
* terminal operation.
*
* @return an {@code Optional} describing the first element of this stream,
* or an empty {@code Optional} if the stream is empty
* @throws NullPointerException if the element selected is null
*/
Optional findFirst();
该方法是一个终端操作,返回一个Optional类,里面包含前面流操作之后的第一个元素;或者返回一个空的Optional类,如果流是空的话。
归约
将流中所有元素反复结合起来,得到一个值,比如一个Integer。这样的查询可以被归类为归约操作
(将流归约成一个值)。(引自《Java8实战》)
元素求和
(1)for-each循环版本:
int sum = 0;
for (int x : numbers) {
sum += x;
}
(Java8版本):
List nums = Arrays.asList(1,2,3,4,5,6,7,8,9);
int sum = nums.stream()
.reduce(0,(x,y) -> x + y);
reduce方法源码:
/**
* Performs a reduction on the
* elements of this stream, using the provided identity value and an
* associative
* accumulation function, and returns the reduced value. This is equivalent
* to:
* {@code
* T result = identity;
* for (T element : this stream)
* result = accumulator.apply(result, element)
* return result;
* }
*
* but is not constrained to execute sequentially.
*
* The {@code identity} value must be an identity for the accumulator
* function. This means that for all {@code t},
* {@code accumulator.apply(identity, t)} is equal to {@code t}.
* The {@code accumulator} function must be an
* associative function.
*
*
This is a terminal
* operation.
*
* @apiNote Sum, min, max, average, and string concatenation are all special
* cases of reduction. Summing a stream of numbers can be expressed as:
*
*
{@code
* Integer sum = integers.reduce(0, (a, b) -> a+b);
* }
*
* or:
*
* {@code
* Integer sum = integers.reduce(0, Integer::sum);
* }
*
* While this may seem a more roundabout way to perform an aggregation
* compared to simply mutating a running total in a loop, reduction
* operations parallelize more gracefully, without needing additional
* synchronization and with greatly reduced risk of data races.
*
* @param identity the identity value for the accumulating function
* @param accumulator an associative,
* non-interfering,
* stateless
* function for combining two values
* @return the result of the reduction
*/
T reduce(T identity, BinaryOperator accumulator);
该方法是一个终端操作,方法接受两个参数:
(1)第一个是初始值
(2)第二个是BinaryOperator,它对两个相同类型的操作数进行操作,返回一个操作之后的相同类型的结果。
使用方法引用让这段代码更简洁:
int sums = nums.stream()
.reduce(0,Integer::sum);
计算流中的最大值:
Optional max = nums.stream()
.reduce(Integer::max);