SQLite权威指南(第二版)第七章 The Extension C API
本章介绍有关SQLite的新技术。主要讨论
用户自定义函数、聚合、排序规则
- 用户自定义函数:用户编写的用于特定应用的SQL函数,可以在SQL语句中调用
- 聚合:聚合函数可以从多个字段进行计算(普通函数对单个记录进行操作),SQLite标准的聚合函数有
SUM()/COUNT()/AVG() - 排序规则:对文本进行比较和排序的方法。SQLite默认规则BINARY
一、API
在程序中注册过
函数、聚合、排序规则的回调block实现,才可以在SQL中使用他们(排序规则使用单独的注册函数)
扩展API的生命周期是短暂的,他们是基于连接注册的且不存储在数据库中,需要确保应用程序加载了扩展API并在连接中注册
1.注册函数sqlite3_create_function()
int sqlite3_create_function(
sqlite3 *cnx, /* connection handle */
const char *zFunctionName, /* function/aggregate name in SQL */
int nArg, /* number of arguments. -1 = unlimited. */
int eTextRep, /* encoding (UTF8, 16, etc.) */
void *pUserData, /* application data, passed to callback */
void (*xFunc)(sqlite3_context*,int,sqlite3_value**),
void (*xStep)(sqlite3_context*,int,sqlite3_value**),
void (*xFinal)(sqlite3_context*)
);
- 参数定义如下:
- cnx:数据库连接句柄,函数和聚合的置顶连接。若要使用函数,必须在连接上注册
- zFunctionName:将在SQL中调用的函数名称,长度在255字节以内
- nArg:自定义函数的参数数量。SQLite将会强制函数格式保证参数都输入。-1是不限制参数数量
- eTextRep:首选文本编码。比如:SQLITE_UTF8/SQLITE_UTF16/SQLITE_UTF16BE/SQLITE_UTF16LE/SQLITE_ANY
- pUserData:应用程序数据。该数据可供在xFunc、xStep和xFinal指定的回调函数中使用。
- xFunc:回调函数。这是SQL函数的真是实现。用户自定义函数只需要提供该回调,同时让xStep、xFinal函数指针未null。后两个回调函数是专门给用户自定义聚合实现使用的
- xStep:聚合步骤函数。SQLite每次处理聚合结婚集中的一行都要调用xStep,以便聚合处理该行的相关字段值,并将其包含在聚合计算的结果中
- xFinal:finalize聚合函数。处理完所有的行后,SQLite调用该函数进行整个聚合汇总处理,该干啥通常是由计算追终止和可选的情况不符组成
2.步骤函数
void fn(sqlite3_context* ctx, int nargs, sqlite3_value** values)
- ctx 是 函数/聚合 的上下文。它保持特殊函数调用的实例状态,通过它可以活动
squlite3_create_function()挺的应用程序数据参数(pUserData). - 可以通过
sqlite3_user_data()获取用户数据:
void *sqlite3_user_data(sqlite3_context*);
- 对函数而言,这些数据可以在左右的调用中共享,因此对函数调用的特定实例而言它不是唯一的
- 同样的pUserData可以在给定函数的所有实例中传递或共享,但是聚合可以通过
sqlite3_aggregate_context()为每个特定的实例分配状态:
void *sqlite3_aggregate_context(sqlite3_context*, int nBytes);
- 第一次调用该函数时执行一个特殊的聚合函数,分配n字节内存,赋值为0,并与上下文关联。
- 上下文环境汇总后面的调用(同一个聚合的实例)可以返回这些分配的内存
- 使用该函数是,聚合可以在调用之间存储状态一遍堆积数据
- 打枊聚合完成final()回调时,由SQLite自动释放内存。
注意: API始终以 void 指针形式使用用户数据。因为:API的很多不法会触发回调函数,在实现所谓的回调函数时,只是作为一种维护状态的便捷方法。
3.返回值
- 参数values是sqlite3_value结构体数组,是SQLite实际参数值的句柄。这些值的实际数据可以使用
sqlite3_value_xxx()系列函数获取:xxx sqlite3_value_xxx(sqlite3_value* value); - 比如获取标量值函数
int sqlite3_value_int(sqlite3_value*);
sqlite3_int64 sqlite3_value_int64(sqlite3_value*);
double sqlite3_value_double(sqlite3_value*);
- 比如获取数组值函数
int sqlite3_value_bytes(sqlite3_value*);
const void *sqlite3_value_blob(sqlite3_value*);
const unsigned char *sqlite3_value_text(sqlite3_value*);
- 函数
sqlite3_value_bytes()返回blob缓冲去中数据的长度 - 函数
sqlite3_value_blob()返回指向缓冲区的数据的指针 - 有了空间和指针,就可以复制出数据。eg。:自定义函数的第一个参数是blob,复制数据如下:
int len;
void* data;
len = sqlite3_value_bytes(values[0]);
data = sqlite3_malloc(len);
memcpy(data, sqlite3_value_blob(values[0]), len);
- 获取值类型
sqlite3_value_type()
int sqlite3_value_type(sqlite3_value*);
#define SQLITE_INTEGER 1
#define SQLITE_FLOAT 2
#define SQLITE_TEXT 3
#define SQLITE_BLOB 4
#define SQLITE_NULL 5
二、函数
- 举个栗子说明实现简单的函数
hello_newman(),接收一个参数,访问人名
sqlite > select hello_newman('Jerry') as reply;
reply
------------------
Hello Jerry
sqlite > select hello_newman('Kramer') as reply;
reply
------------------
Hello Kramer
sqlite > select hello_newman('George') as reply;
reply
------------------
Hello George
- 代码实现如下
int main(int argc, char **argv)
{
int rc; sqlite3 *db;
sqlite3_open_v2("test.db", &db);
sqlite3_create_function( db, "hello_newman", 1, SQLITE_UTF8, NULL,
hello_newman, NULL, NULL);
/* Log SQL as it is executed. 执行时记录SQL日志 */
log_sql(db,1);
/* Call function with one text argument.传入1个文本参数调用函数 */
fprintf(stdout, "Calling with one argument.\n");
print_sql_result(db, "select hello_newman('Jerry')");
/* Call function with two arguments. 传入两个参数调用函数(会失败,因为注册时只接收1个参数)
** It will fail as we registered the function as taking only one argument.*/
fprintf(stdout, "\nCalling with two arguments.\n");
print_sql_result(db, "select hello_newman ('Jerry', 'Elaine')");
/* Call function with no arguments. This will fail too 不传参调用函数也失败 */
fprintf(stdout, "\nCalling with no arguments.\n");
print_sql_result(db, "select hello_newman()");
/* Done */
sqlite3_close(db);
return 0;
}
void hello_newman(sqlite3_context* ctx, int nargs, sqlite3_value** values)
{
const char *msg;
/* Generate Newman's reply 生成 Newman的 回复 */
msg = sqlite3_mprintf("Hello %s", sqlite3_value_text(values[0]));
/* Set the return value. Have sqlite clean up msg w/ sqlite_free().
设置返回值,用 sqlite3_free清理msg
*/
sqlite3_result_text(ctx, msg, strlen(msg), sqlite3_free);
}
- 运行结果:
Calling with one argument.
TRACE: select hello_newman('Jerry')
hello_newman('Jerry')
---------------------
Hello Jerry
Calling with two arguments.
execute() Error: wrong number of arguments to function hello_newman()
Calling with no arguments.
execute() Error: wrong number of arguments to function hello_newman()
-
log_sql()简单的调用了sqlite3_trace(),在追踪函数中传递哪些带有TRACE的SQL追踪内容。记录SQL的执行 -
print_sql_result()的声明:int print_sql_result(sqlite3 *db, const char* sql, ...),是对sqlite3_prepare_v2()的简单封装,它将执行SQL预计并打印结果
1.返回值
-
sqlite3_result_text()是sqlite3_result_xxx()系列之一,该系列函数是用户用来自定义函数和聚合返回值的。标量函数如下:
void sqlite3_result_double(sqlite3_context*, double);
void sqlite3_result_int(sqlite3_context*, int);
void sqlite3_result_int64(sqlite3_context*, long long int);
void sqlite3_result_null(sqlite3_context*);
- 这些函数在函数名称中接收一个指定类型的参数(第二个参数),将其设置为函数的返回值。数组函数如下:
void sqlite3_result_text(sqlite3_context*, const char*, int n, void(*)(void*));
void sqlite3_result_blob(sqlite3_context*, const void*, int n, void(*)(void*));
- 这些函数接收数组数据并将该数组设置为函数返回值
void sqlite3_result_xxx(
sqlite3_context *ctx, /* function context */
const xxx* value, /* array value */
int len, /* array length */
void(*free)(void*)); /* array cleanup function */
- 这里xxx是特殊的数组类型(void代表blob,char代表text)
2.数组与内存清理器
- 与在SQL预计中绑定数组只一样,这些函数与
sqlite3_bind_xxx()的工作方式相同。他们需要一个指向数组的指针、一个数组的长度、指向清理函数的函数指针。清理函数的指针可以像sqlite3_bind_xxx()中的一样是预定义好的。
#define SQLITE_STATIC ((void(*)(void *))0)
#define SQLITE_TRANSIENT ((void(*)(void *))-1)
-
SQLITE_STATIC意味着数组内存驻留在非托管空间,因此SQLite不需要数据副本,也不会视图清理它。 -
SQLITE_TRANSIENT提示SQLite数组数据有可能改变,因此SQLite需要使用sqlite3_malloc()为自己复制一份数据。当函数返回时,分配的内存将会释放。 - 第三选项是传递一个指向如下形式的清理函数的指针:
void cleanup(void*); - 这种情况下,SQLite在洪湖自定义函数完成后,调用清理函数
- 例子:我们用
sqlite3_mprintf()生成前面定义的hello_newman()回复,该回复在堆上分配字符串。我们将sqlite3_free()作为清理函数传递给sqlite3_result_text(),这样当扩展函数完成时,可以释放字符串内存。
3.错误处理
- 函数遇到错误时应该设置恰当的返回值。
sqlite3_result_error()
void sqlite3_result_error(
sqlite3_context *ctx, /* the function context */
const char *msg, /* the error message */
int len); /* length of the error message */
- 它通知SQLite出现错误,详细信息在msg中。SQLite会终止调用函数并将错误信息包含在msg中
4.返回输入值
- 场景:将输入的参数原样返回
-
sqlite3_column_xxx()获取值,sqlite3_result_xxx()设置返回值
void sqlite3_result_value(
sqlite3_context *ctx, /* the function context */
sqlite3_value* value); /* the argument value */
- eg。 创建一个可以回显首个参数的
echo():
void echo(sqlite3_context* ctx, int nargs, sqlite3_value** values)
{
sqlite3_result_value(ctx, values[0]);
}
三、聚合
- 自定义函数实现一个回调,聚合必须实现两个
- 步骤函数计算进行汇总的值
- finalize函数完成最终计算和清理工作
st=>start: select sum(id) from foo;
e=>end: sum(id)
op=>operation: sqlite_prepare()
op0=>operation: sqlite_step()
op1=>operation: xStep()
op2=>operation: xFinal()
cond=>condition: SQLITE_ROW
st->op->op0->cond
cond(yes)->op1->op0
cond(no)->op2->e
1.注册函数
int sqlite3_create_function(
sqlite3 cnx*, /* connection handle */
const char *zFunctionName, /* function/aggregate name in SQL */
int nArg, /* number of arguments. -1 = unlimited. */
int eTextRep, /* encoding (UTF8, 16, etc.) */
void *pUserData, /* application data, passed to callback */
void (*xFunc)(sqlite3_context*,int,sqlite3_value**),
void (*xStep)(sqlite3_context*,int,sqlite3_value**),
void (*xFinal)(sqlite3_context*)
);
2.实例
int main(int argc, char **argv)
{
int rc; sqlite3 *db; char *sql;
sqlite3_open_v2("foods.db", &db);
/* Register aggregate. */
fprintf(stdout, "Registering aggregate str_agg()\n");
/* Turn SQL tracing on. */
log_sql(db, 1);
/* Register aggregate. */
sqlite3_create_function( db, "str_agg", 1, SQLITE_UTF8, db,
NULL, str_agg_step, str_agg_finalize);
/* Test. */
fprintf(stdout, "\nRunning query: \n");
sql = "select season, str_agg(name, ', ') from episodes group by season";
print_sql_result(db, sql);
sqlite3_close(db);
return 0;
}
- 注意,步骤函数
str_agg_step(),finalize函数str_agg_finalize() - 该聚合函数注册成只接收一个参数
3.步骤函数
void str_agg_step(sqlite3_context* ctx, int ncols, sqlite3_value** values)
{
SAggCtx *p = (SAggCtx *) sqlite3_aggregate_context(ctx, sizeof(*p));
static const char delim [] = ", ";
char *txt = sqlite3_value_text(values[0]);
int len = strlen(txt);
if (!p->result) {
p->result = sqlite_malloc(len + 1);
memcpy(p->result, txt, len + 1);
p->chrCnt = len;
} else {
const int delimLen = sizeof(delim);
p->result = sqlite_realloc(p->result, p->chrCnt + len + delimLen + 1);
memcpy(p->result + p->chrCnt, delim, delimLen);
p->chrCnt += delimLen;
memcpy(p->result + p->chrCnt, txt, len + 1);
p->chrCnt += len;
}
}
// SAggCtx是本例中的结构体
typedef struct SAggCtx SAggCtx;
struct SAggCtx {
int chrCnt;
char *result;
};
- SAggCtx充当聚合迭代(对步骤函数的调用)之间的状态,维持不断增长的拼接文本和字符数
4.聚合上下文
- 通过
sqlite3_aggregate_context()为给定的聚合实例获取结构体 -
sqlite3_aggregate_context()首次调用会为该上下文分配数据,之后调用直接获取 - 聚合完成后(
str_agg_finalize()后),结构体内存自动释放 - 注意:若系统内存不足,
sqlite3_aggregate_context()可能返回null,本例中没处理这种异常,实际开发必须处理 - 若返回
null,需触发sqlite3_resut_error_nomem() - 在
str_agg_step()中,可以用sqlite3_value_text()从首个参数获取被聚合的文本值,然后将其谈价到结构体SAggCtx的result成员中,该及饿哦固体中介拼接字符串 - 注意2:若SQL参数是
null,or内存不足,sqlite3_value_text()可能返回null,需要检查处理
5.Finalize函数
- 每次显示结果的记录都会触发
str_agg_step()调用 - 所有记录完事后,SQLite调用
str_agg_finalize()
void str_agg_finalize(sqlite3_context* ctx)
{
SAggCtx *p = (SAggCtx *) sqlite3_aggregate_context(ctx, sizeof(*p));
if( p && p->result ) sqlite3_result_text(ctx, p->result, p->chrCnt, sqlite_free);
}
-
str_agg_finalize()像用户滴定仪的回调函数一样工作。它获取及饿哦固体sAggctx,若该结构体存在,通过sqlite3_result_text()将聚合的返回值设置为结构体中存储的成员result - 若内存不足,or未调用步骤函数,p->zResult 可能为null,SQLite会返回错误
- 若内存不足,or未调用步骤函数,
sqlite3_result_text()可能返回null,聚合结构体也会是null
6.结果
Registering aggregate str_agg()
Running query:
TRACE: select season, str_agg(name, ', ') from episodes group by season
…
season str_agg(name, ', ')
0 Good News Bad News
1 Male Unbonding, The Stake Out, The Robbery, The Stock Tip
2 The Ex-Girlfriend, The Pony Remark, The Busboy, The Baby Shower, …
3 The Note, The Truth, The Dog, The Library, The Pen, The Parking Garage …
…
四、排序规则(Collations)
- 单词是校对的意思,这里翻译成了排序规则,我挺疑惑的
- 排序的目的:对事物进行分类比较。
- SQLite对结果集中的字段进行排序时(SQLite使用比较操作符,如:< or >=, 在字段内对值进行比较)
- 首先根据存储类对字段值进行排列
- 在每种存储类中,根据该类指定的方法进行排序
1. NULL values
2. INTEGER and REAL values
3. TEXT values
4. BLOB values
- SQLite 对每种存储类使用对应的排序算法
- NULL没有排序
- 数字按照大小进行排序
- BLOB按照二进制进行排序
- 最后,文本是我们要讨论的排序规则的重点
1.排序规则定义(Collation Defined)
- 排序规则是比较字符串的方法,定义如下
- 与逐个byte比较数字代码相反,排序规则使用语言敏感的规则对文本进行比较
- 通常,排序规则必须处理字符串和字符的 排序、比较、排列
- 排序规则通常使用 排序序列
- 排序序列是一局拍好像的字符串列表,通常都有数字编码,以便记忆和使用
- 字符串列表是用来判断字符是如何排序、比较以及分类的
- 给定俩字符,排序规则必须判断出那个在前or相等
1.1 排序规则原理(How Collation Works)
-
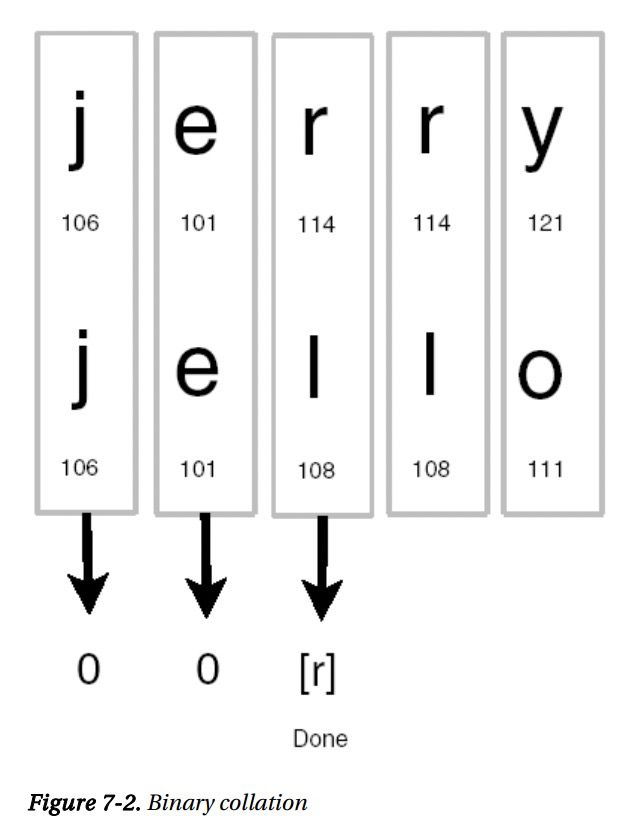
排序方法对将要比较的两个字符串进行切分,共同管排序序列逐一比较每个字符。从左到右进行比较 eg。 jerry与jello进行比较
 378D1ACC-3582-4C40-AB9F-FD36C989AD6A.png
378D1ACC-3582-4C40-AB9F-FD36C989AD6A.png
- 本例排序规则是ASCII字符集,图中显示了每个字符的ASCII值,使用刚描述的排序规则,字符串比较到第三个字符时,jerry胜出114>108,jerry>jello
- 若jerry变Jerry,那么jello胜出,因为J是74,74<106
1.2 标准排序规则类型(Standard Collation Types)
- SQLite中唯一内置的排序规则binary使用标准的C函数库memcmp()比较两个字符串。binary排序规则对于英文文本使用很好。但对于其它语言,可能需要其它的排序规则。SQLite还提供了另一种排序规则nocase,它是大小写不敏感的。
- 排序规则是通过表字段or索引定义以及在查询中指定的方法和字段关联起来的。例如,在foo中创建大小写不敏感的bar字段,使用如下定义
create table foo(bar text collate nocase, baz integer); - 从那时起,SQLite处理bar字段时,就用使用nocase排序规则。如不想将排序规则附加到数据库对象上,而是在需要时在查询中指定,可以直接在查询中指定他们,如:
select * from foo order by bar collate nocase; - SQLite 也可以对
cast()表达式的结果应用排序规则,cast()表达式可以将非文本数据转文本数据。我们可以将bar数字值转文本,并像下面这样应用nocase排序:select cast(baz) collate nocase as baz_as text from foo order by baz_as text;
2.简单例子
- 实现 length_first 排序规则,接收俩字符串,根据长度排序;比如在店里吃名字短的食物
-
shlite3_create_collation_v2()注册排序规则
int sqlite3_create_collation_v2(
sqlite3* db, /* database handle */
const char *zName, /* collation name in SQL */
int pref16, /* encoding */
void* pUserData, /* application data */
int(*xCompare)(void*,int,const void*,int,const void*)
void(*xDestroy)(void*)
);
- 与
sqlite3_create_function()相似。第一个参数是标准的数据库句柄,第二个是在SQL中使用的排序规则名称(与函数、聚合名称类似),然后编码方式(编码方式从属于传递给比较函数时被比较字符串的格式) - pUserData是另一个API的主要支撑,该真真传递给回调函数。函数
sqlite3_create_collation_v2()基本上是删减版的sqlite3_create_function()-
sqlite3_create_function()输入俩文本参数,返回一个int -
sqlite3_create_collation_v2()去掉了聚合回调函数指针
-
2.1 Compare函数
参数xCompare指向实际解析文本值的比较函数。比较函数格式如下:
int compare( void* data, /* application data */
int len1, /* length of string 1 */
const void* str1, /* string 1 */
int len2, /* length of string 2 */
const void* str2) /* string 2 */
- 字符串关系 < 返回负值,=返回0,>返回正值
int length_first_collation( void* data, int l1, const void* s1,
int l2, const void* s2 )
{
int result, opinion;
/* Compare lengths */
if ( l1 == l2 ) result = 0;
if ( l1 < l2 ) result = 1;
if ( l1 > l2 ) result = 2;
/* Form an opinion: is s1 really < or = to s2 ? */
switch(result) {
case 0: /* Equal length, collate alphabetically */
opinion = strcmp(s1,s2);
break;
case 1: /* String s1 is shorter */
opinion = -result;
break;
case 2: /* String s2 is shorter */
opinion = result
break;
default: /* Assume equal length just in case */
opinion = strcmp(s1,s2);
}
return opinion;
}
2.2 测试程序
int main(int argc, char **argv)
{
char *sql; sqlite3 *db; int rc;
sqlite3_open("foods.db", &db);
/* Register Collation. */
fprintf(stdout, "1. Register length_first Collation\n\n");
sqlite3_create_collation_v2( db, "LENGTH_FIRST", SQLITE_UTF8, db,
length_first_collation, length_first_collation_del );
/* Turn SQL logging on. */
log_sql(db, 1);
/* Test default collation. */
fprintf(stdout, "2. Select records using default collation.\n");
sql = "select name from foods order by name";
print_sql_result(db, sql);
/* Test Length First collation. */
fprintf(stdout, "\nSelect records using length_first collation. \n");
sql = "select name from foods order by name collate LENGTH_FIRST";
print_sql_result(db, sql);
/* Done. */
sqlite3_close(db);
return 0;
}
2.3 结果
======================================================
1. Register length_first Collation
2. Select records using default collation.
TRACE: select name from foods order by name
name
-----------------
A1 Sauce
All Day Sucker
Almond Joy
Apple
Apple Cider
Apple Pie
Arabian Mocha Java (beans)
Arby's Roast Beef
Artichokes
Atomic Sub
...
Select records using length_first collation.
TRACE: select name from foods order by name collate LENGTH_FIRST
issue
-----------------
BLT
Gum
Kix
Pez
Pie
Tea
Bran
Duck
Dill
Life
...
======================================================
3.按需排序
- SQLite提供一种知道实际需要时才注册排序的懒加载方式。
- 若不确定您的 程序是否需要一些想
length_first的排序规则,可以用sqlite3_collation_needed(),将注册延时到使用时 - 只需提供回调函数,SQLite会在需要时注册未知排序规则,并给定名称
总结
- 使用扩展C API 向SQLite核心库添加这些自定义函数是对SQLite核心库的重要补充。因此,您可以深挖和修改SQLite的核心内容,甚至可以说SQLite提供了友好的、易于使用的、可以更大范围扩展和定制自身的用户接口,特别是和SQLite汇总已有功能结合时