系统环境:
操作系统:CentOS 6.5
Hadoop:2.6.0
为了方便起见,打印当前系统状态

vim /etc/hosts,host信息如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.211.55.150 master
准备工作
- 安装idk 1.7
- 配置su命令免密码,详见我的另一篇文章《免密码使用sudo和su》
以下流程有些步骤必须需要切换到root权限执行,为了便于叙述,后续所有步骤都在root权限下操作 - 配置ssh免密码登录
ssh-keygen -t rsa -P "" //然后一直回车即可
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
配置完成后可以使用ssh localhost测试下是否配置成功
- 下载hadoop2.6.0 apache官网下载地址
Hadoop安装
+ 解压并移动文件到hadoop文件夹
su root
cd /
tar -zxvf hadoop-2.6.0.tar.gz
mkdir hadoop
mv hadoop-2.6.0 hadoop
- 系统环境变量
export HADOOP_HOME=/hadoop/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- Hadoop环境变量
cd /hadoop/hadoop-2.6.0/etc/hadoop
vi hadoop-env.sh
修改:
export JAVA_HOME=/usr/jdk1.7.0_80
Hadoop单机模式验证
所谓的本地模式:在运行程序的时候,比如wordcount是在本地磁盘运行的
到这一步时,单机模式已经部署完毕,我们可以跑一个小程序验证下。
- 我们先切换到Hadoop目录,创建一个input文件夹,并拷贝一些文件到该文件夹中。
cd $HADOOP_HOME
mkdir input
cp etc/hadoop/*.xml input
- 执行下hadoop自带的wordcound小程序验证
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount input output
- 查看执行结果
cat output/*
这里就不演示运算结果了,一般也不会出什么问题,我们继续配置伪分布模式。
Hadoop伪分布模式
切换路径到/hadoop/hadoop-2.6.0/etc/hadoop
- vi core-site.xml
hadoop.tmp.dir
/hadoop/tmp
fs.default.name
hdfs://master:9000
- vi hfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
/hadoop/dfs/name
dfs.datannode.data.dir
/hadoop/dfs/data
如果不想让程序运行在yarn上,到此为止配置已经完成,我们可以验证下。
首先我们需要创建hadoop临时文件夹和hdfs文件夹
cd /hadoop
mkdir tmp
mkdir dfs/{name,data}
- 格式化namenode
hdfs namenode -format
- 启动集群
start-dfs.sh
启动后我们可以通过管理页面上看到相应的信息,显示如下页面证明启动成功。
浏览器输入:localhost:50070

当然,我们可以运行下wordcount验证下(方法同yarn部分)
yarn配置
还是切换路径到/hadoop/hadoop-2.6.0/etc/hadoop
- vi mapred-site.xml
这里需要注意,2.6.0并没有提供mapred-site.xml文件,而是提供了一个mapred-site.xml.template文件,这里我们需要将扩展名中的.template去掉
mv mapred-site.xml.template mapred-site.xml
接着修改文件内容
mapreduce.framework.name
yarn
这里还要注意下,如果不想程序运行在yarn上,还需要将template后缀加上,要不会运行失败。
- vi yarn-site.xml
mapreduce.framework.name
yarn
yarn.nodemanager.aux-services
mapreduce_shuffle
下面还是验证运行wordcount验证下:
- 先停止集群
stop-all.sh
- 启动集群
start-dfs.sh
start-yarn.sh
- 查看hadoop运行状态
hdfs dfsadmin -report

启动成功后也可以在hadoop进程管理页面中查看,浏览器输入localhost:8088
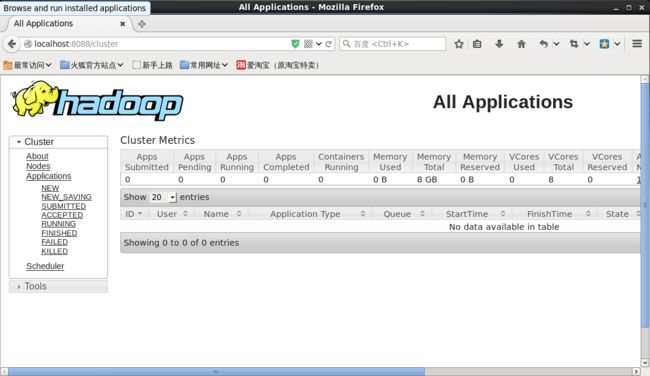
在这里我们可以看到hadoop运行的程序详细信息,由于目前还没有执行任何程序,所以这里什么都没显示。
- 在hdfs上创建input文件夹
hdfs dfs -mkdir -p input
- 拷贝一些本地文件到hdfs的input文件夹中,执行路径切换到/hadoop/hadoop-2.6.0
hdfs dfs -put etc/hadoop input
- 执行wordcount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount input output
执行过程如图:
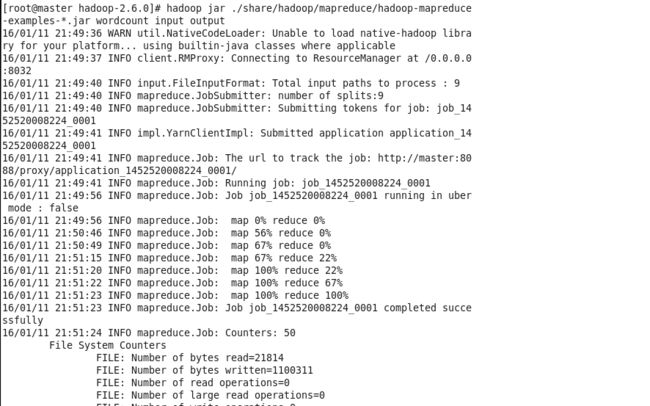
执行成功后,控制台中会显示 Job job_1452520008224_0001 completed successfully。
- 查看结果
hdfs dfs -cat output/*
词频统计结果,部分截图(这个结果和你input文件夹内容相关)

你可以将结果从hdfs内拷贝到当前路径中
hdfs dfs -get output output
hdfs常用命令,可以详见本人另一篇文章 《常用HDFS命令》
到此,Hadoop单机模式和伪分布式模式已经介绍完。
问题说明:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
网上查了查,很多解释说是hadoop-2.6.0.tar.gz安装包是在32位机器上编译的,64位的机器加载本地库.so文件时出错。可我找了下,发现官网上下载的安装包实际上就是64位的。估计有可能是某些系统不支持本地库吧,** 这个不影响使用 **,大家可以无视。