前言
前面的android项目刚完,项目总结文章还未写完,公司需要研究大数据处理应用平台,任务下达到我们部门了,鉴于部门物理机只有一台,而虚拟机启动太慢的原因,自己动手在Docker搭建了三个三节点的数据分析集群,主要包括Hdfs集群(分布式存储集群),YARN集群(分布式资源管理集群),Spark集群(分布式计算集群)。
在开始正文之前,需要掌握以下基础知识:
- Linux基础知识(推荐《鸟哥的Linux私房菜》,我早年看的时候是第三版,现在已经有了新版本);
- Doceker镜像,容器和仓库的概念(推荐《Docker — 从入门到实践》);
- Hadoop的基础概念和原理;
在Centos7上搭建数据分析集群过程包括:
- 在Cnetos7上安装Docker并创建Hadoop镜像和三节点容器
- 在Docker上配置三节点Hdfs集群
- 在Docker上配置三节点Yarn集群
- 在Docker上配置三节点Spark集群
(一)安装Docker与创建Hadoop镜像和三节点容器
1.1 安装Dcoker
本文在Cnetos7系统上安装Docker,安装Docker对于Linux系统的要求是
64 位操作系统,内核版本至少为 3.10。
1.1.1 安装Docker
curl -sSL https://get.docker.com/ | sh
1.1.2 配置Docker加速器和开机启动服务
这里需要注册一个阿里云账号,每个账号有自己专属的加速器,专属加速器的地址,根据自己的地址配。
sudo cp -n /lib/systemd/system/docker.service /etc/systemd/system/docker.service
sudo systemctl daemon-reload
sudo service docker restart
1.2 在Docker上创建Hadoop镜像
1.2.1 从Docker Hub官网仓库上获取centos镜像库
docker pull centos
#查看镜像库
docker images
1.2.2 生成带有SSH功能的centos的镜像文件
为了后面配置各节点之间的SSH免密码登陆,需要在pull下的centos镜像库种安装SSH,
这里利用 Dockerfile 文件来创建镜像
cd /usr/local
# 创建一个存放带ssh的centos镜像Dockerfile文件的目录
mkdir DockerImagesFiles/centos7.shh
#创建带ssh的centos的Dockerfile 文件
vi Dockerfile
# Dockerfile文件内容
#基于centos镜像库创建
FROM centos
MAINTAINER dys
#安装ssh
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
RUN yum install -y openssh-clients
#配置root名
RUN echo "root:123456" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
#生成ssh key
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
#配置sshd服务
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
1.2.3 根据上面的Dockerfile生成centos7-ssh镜像
docker build -t="centos7-ssh" .
#执行完成后,查看已安装的镜像库
docker images
1.2.4 生成Hadoop镜像库文件
在构建Hadoop镜像库的Dockerfile所在目录下,上传已经下载的 jdk-8u101-linux-x64.tar.gz, hadoop-2.7.3.tar.gz,scala-2.11.8.tgz,spark-2.0.1-bin-hadoop2.7.tgz。
注意:这里要提前在Dockerfile文件配置环境变量,如果镜像库构建完成后,在
容器中配置环境变量是不起作用的。
cd /usr/local
# 创建一个存放hadoop镜像Dockerfile文件的目录
mkdir DockerImagesFiles/hadoop
#创建带ssh的centos的Dockerfile 文件
vi Dockerfile
# Dockerfile文件内容
#基于centos7-ssh构建
FROM centos7-ssh
#安装java
ADD jdk-8u101-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_101 /usr/local/jdk1.8
#配置JAVA环境变量
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
#安装hadoop
ADD hadoop-2.7.3.tar.gz /usr/local
RUN mv /usr/local/hadoop-2.7.3 /usr/local/hadoop
#配置hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
#安装scala 注意Spark2.0.1对于Scala的版本要求是2.11.x
ADD scala-2.11.8.tgz /usr/local
RUN mv /usr/local/scala-2.11.8 /usr/local/scala2.11.8
#配置scala环境变量
ENV SCALA_HOME /usr/local/scala
ENV PATH $SCALA_HOME/bin:$PATH
#安装spark
ADD spark-2.0.1-bin-hadoop2.7.tgz /usr/local
RUN mv /usr/local/spark-2.0.1-bin-hadoop2.7.tgz /usr/local/spark2.0.1
#配置spark环境变量
ENV SPARK_HOME /usr/local/spark
ENV PATH $SPARK_HOME/bin:$PATH
#创建hdfs账号
RUN useradd hdfs
RUN echo "hdfs:12345678" | chpasswd
RUN yum install -y which sudo
1.2.5 根据上面的Dockerfile构建Hadoop镜像库
docker build -t="hadoop" .
#执行完成后,查看已安装的镜像库
docker images
1.2.6 生成三节点Hadoop容器集群
1.2.6.1首先规划一下节点的主机名称,IP地址(局域网内构建docker镜像时,自动分配172.17.0.1/16网段的IP)和端口号
master 172.17.0.2
slave01 172.17.0.3
slave02 172.17.0.4
1.2.6.2下面在Hadoop镜像上创建三个容器,做为集群的节点
#创建master容器,50070和8088,8080是用来在浏览器中访问hadoop yarn spark #WEB界面,这里分别映射到物理机的50070和8088,8900端口。
#重点注意:容器启动后,映射比较麻烦,最好在这里映射。
docker run -d -P -p 50070:50070 -p 8088:8088 -p 8080:8900 --name master -h master --add-host slave01:172.17.0.3 --add-host slave02:172.17.0.4 hadoop
#创建slave01容器,在容器host文件,添加hostname,并配置其他节点主机名称和IP地址
docker run -d -P --name slave01 -h slave01 --add-host master:172.17.0.2 --add-host slave02:172.17.0.4 hadoop
#创建slave02容器
docker run -d -P --name slave02 -h slave02 --add-host master:172.17.0.2 --add-host slave01:172.17.0.3 hadoop
1.2.6.3 查看已创建的容器并更改hadoop和spark2.0.1目录所属用户
#查看已创建的容器
docker ps -a
#更改hadoop和spark2.0.1目录所属用户
chown -R hdfs:hdfs /usr/local/hadoop
chown -R hdfs:hdfs /usr/local/spark2.0.1
(二)在Docker上配置三节点Hdfs集群
2.1开启三个容器终端
docker exec -it master /bin/bash
docker exec -it slave01 /bin/bash
docker exec -it slave02 /bin/bash
2.1 配置hdfs账号容器各节点间的SSH免密码登陆
分别进入master,slave01,slave02三个容器节点,执行下面命令
#切换到hdfs账号
su hdfs
#生成hdfs账号的key,执行后会有多个输入提示,不用输入任何内容,全部直接回车即可
ssh-keygen
#拷贝到其他节点
ssh-copy-id -i /home/hdfs/.ssh/id_rsa -p 22 hdfs@master
ssh-copy-id -i /home/hdfs/.ssh/id_rsa -p 22 hdfs@slave01
ssh-copy-id -i /home/hdfs/.ssh/id_rsa -p 22 hdfs@slave02
#验证是否设置成功
ssh slave01
2.2 配置hadoop
这里主要配置hdfs,因为我们的计算框架要用spark,所以maprreduce的不需要配置。
进入master容器的hadoop配置目录,需要配置有以下7个文件:hadoop-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml
2.2.1 在hadoop-env.sh中配置JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8
2.2.2 在slaves中配置子节点主机名
进入slaves文件,添加下面名称
slave01
slave02
2.2.3 修改core-site.xml
fs.defaultFS
hdfs://master:9000/
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
2.2.4 修改hdfs-site.xml
dfs.namenode.secondary.http-address
master:9001
dfs.webhdfs.enabled
true
dfs.namenode.name.dir
file:/usr/local/hadoop/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/dfs/data
dfs.replication
2
2.2.5 修改mapred-site.xml
2.2.5.1 复制mapred-site.xml文件
#这个文件默认不存在,需要从 mapred-site.xml.template 复制过来
cp mapred-site.xml.template mapred-site.xml
2.2.5.2 修改mapred-site.xml
mapreduce.framework.name
yarn
2.2.6 修改yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8035
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
2.2.7 master容器配置的hadoop目录分别分发到slave01,slave02节点
scp -r hadoop slave01:/usr/local/
scp -r hadoop slave02:/usr/local/
2.3 启动HDFS集群,验证是否搭建成功
#如果配置环境变量,就直接执行
hdfs namenode -format #格式化namenode
start-dfs.sh #启动dfs
# 在 master上执行jps
$ jps
#运行结果应该包含下面的进程
1200 SecondaryNameNode
3622 Jps
988 NameNode
# 在 slave上执行jps
$ jps
#运行结果应该包含下面的进程
2213 Jps
1962 DataNode
浏览器输入http://本机ip地址:50070 ,可以浏览hadoop node管理界面
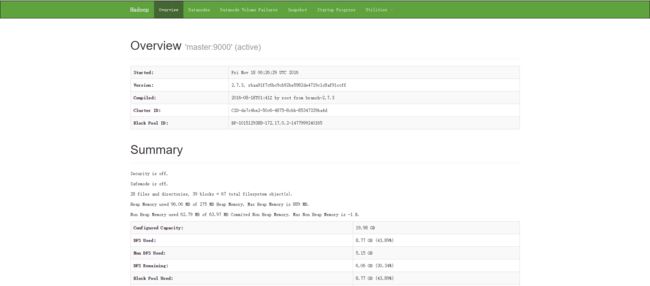
(二)在Docker上配置三节点Yarn集群
上面已经配置成功,直接启动yarn集群
#启动yarn
start-yarn.sh
浏览器输入http://本机ip地址:8088/cluster 可以浏览节点;

(三) 在Docker上配置三节点spark集群
3.1 配置spark
进入master容器的spark配置目录,需要配置有两个文件:spark-env.sh,slaves
3.1.1 配置spark-env.sh
cd /usr/lcoal/spark2.0.1/conf
#从配置模板复制
cp spark-env.sh.template spark-env.sh
#添加配置内容
vi spark-env.sh
在spark-env.sh末尾添加以下内容:
export SCALA_HOME=/usr/local/scala2.11.8
export JAVA_HOME=/usr/local/jdk1.8
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/spark2.0.1
SPARK_DRIVER_MEMORY=1G
3.1.2 在slaves文件下填上slave主机名
slave01
slave02
3.1.3 master容器配置的spark目录分别分发到slave01,slave02节点
scp -r spark2.0.1 slave01:/usr/local/
scp -r spark2.0.1 slave02:/usr/local/
3.2 启动spark集群
start-all.sh
浏览Spark的Web管理页面: http://本机ip地址:8900

总结
本文只是搭建了数据分析的开发环境,作为开发测试使用,距离生成环境的标准还很远。例如容器节点的自动化扩容,容器的CPU内存,调整,有待继续研究。
参考文章
1.https://www.sdk.cn/news/5278 . Docker部署Hadoop集群
2.http://wuchong.me/blog/2015/04/04/spark-on-yarn-cluster-deploy/ .Spark On YARN 集群安装部署
3.http://shinest.cc/static/post/scala/hadoop_cluster_on_docker.md.html . Hadoop Cluster On Docker