这是我在知乎上的回答,问答在此:https://www.zhihu.com/question/27720960/answer/782254350,如果大家也在知乎上玩,欢迎点赞哦。
Excel 有什么好用的技巧,让你相见恨晚?
回答如下:
要说相见恨晚,我只推荐PowerQuery。
PowerQuery不只是Excel的一个技巧,它是一个模块,功能十分强大。
它现在安静的躺在Excel的【数据】选项卡下面,可能很多人压根没有注意过,

点击进去,你就会发现另有一番天地,

简直就是另外一个软件,有木有!
其实不用被这些吓到了,它使用起来十分简单,至少大部分常用的功能都通过点点鼠标就可以完整的。
那么它到底有什么用呢?为什么要从Excel界面来到这个奇怪的地方?
PowerQuery主要用于大数据清洗,就是将各种杂乱的数据整理成我们想要的样子,它的特点:
数据无限制,Excel有1048576行的限制,这里完全没有!
简单的操作,实现各种在传统Excel中很难完成的数据处理,快速成为Excel专家!
一劳永逸:所有的数据处理步骤自动保存,下次点击刷新即可。
可能说到这里大家还是不知道它到底有什么用,怎么用,下面以几个实例来看看它的用法。
一,批量合并多个Excel
如何将多个工作簿的数据合并到一张表上?
可能不同的人有不同的做法?
普通青年用万能的复制粘贴
二逼青年网上百度VBA代码一键汇总
文艺青年找个崇拜自己的实习小MM帮忙
其实都不必这么麻烦,Power Query来了。
下面来看一下PQ是如何汇总多文件的数据的:
假设有一个连锁型零售商店,有北京、广州、杭州三个城市门店,总部每月需要汇总每个城市门店销售明细数据,现在需要汇总2016年1-3月的销售明细,共9个工作簿,保存在一个文件夹内,结构如下:
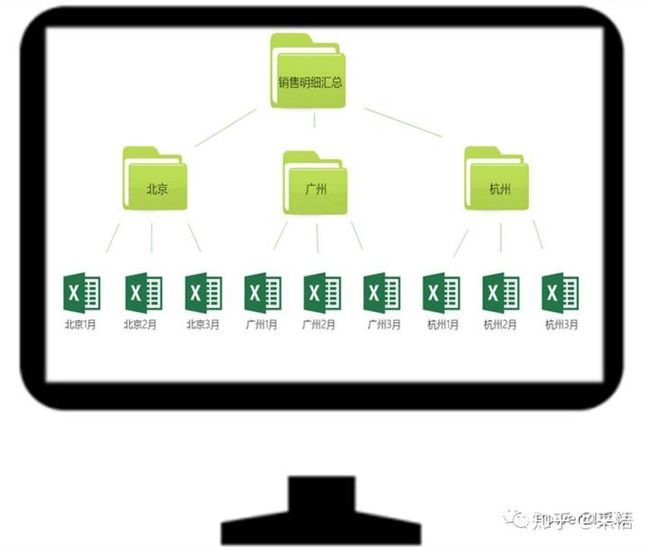
由于只是数据处理的过程,下面的演示就在Excel2016进行,使用Excel2010、Excel2013的插件以及在Power BI Desktop中的操作也都是一样的。
首先我们新建一张空白Excel工作簿,点击"数据"选项卡下"新建查询",从文件夹获取数据:

浏览找到该文件夹的路径,确认后出现这个界面,

点击"编辑",进入查询编辑器:

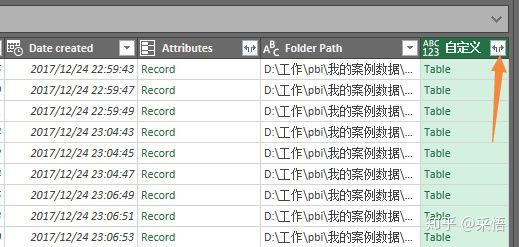
数据就储存在[Content]列,其他列都是每个工作簿的信息,现在要做的就是把Content的内容提取出来,点击"添加列"选项卡,添加自定义列,

自定义列中输入公式=Excel.Workbook([Content]),这里要注意严格区分大小写,不能写错了,这就是提取Excel格式数据的M函数(关于M函数后面会单独介绍)。
确认后就出现了一个自定义列:
点击自[定义列]右上角的双箭头展开数据,出现这个窗口,
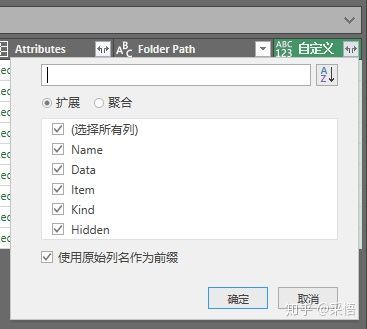
直接点击确定,出现了如下这个界面:

又新增加了几列,继续点击[自定义.Data]列的右上角的双箭头,然后还是直接点确认,数据就全部出来了:
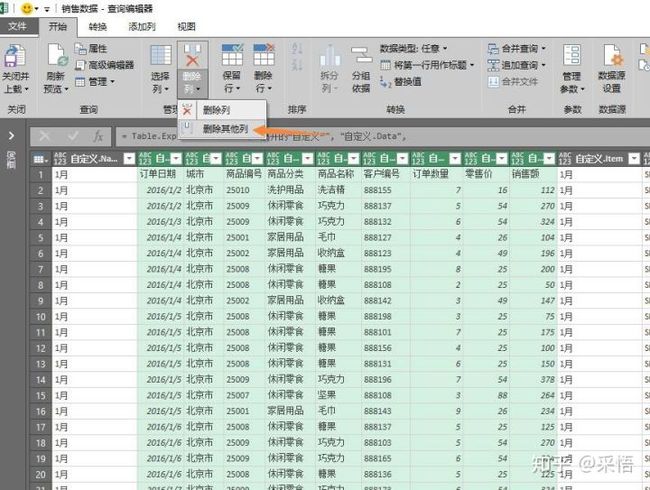
然后只留下下各门店上报的数据了,可以看到列的标题是系统添加的,其实应该用第一行作为列的标题,我们直接点击"转换"选项卡下的将第一行作为标题:

然后标题就提升上去了。
数据导入过程中9个表格的标题行是重复的,另外表格中可能有空行,所有把标题行和空行筛选出去,像在Excel中一样,点击城市的倒三角,去掉这两个勾选:

数据汇总完成,点击上载数据:

然后大功告成,数据就全部汇总到这个Excel表格中了。
看着好像步骤挺多,其实动手做起来,所有这些步骤只需一分钟而已,中间除了那个简单的M函数,一直都是点点鼠标,是不是非常简单呢。
更简单的是,上面操作的所有步骤都被记录下来,下个月销售记录更新的时候,比如把各个门店的4月份的明细数据放到相应的文件夹里面,连点鼠标都不用了,直接刷新数据,然后4月的数据就全部汇总到这个表格了。
如果你说这些其实通过VBA或者简单的复制粘贴还都可以做出来,那么如果有100家门店,每家门店全年12个月的数据呢,复制粘贴显然不现实,如果数据量大用VBA估计也会把电脑卡死。而在PQ中呢,就是打开文件点击刷新,这个文件夹下无论多少文件,无论数据量有多大,汇总也是秒秒钟的事情。
二、合并一个Excel工作簿中的多个sheet
步骤一:获取数据
随便新建一个Excel工作簿,点击数据>获取数据>自文件>从工作簿

步骤二:选择一个表,加载入PowerQuery
选择需要合并的工作簿,然后出现如下界面,

随便选择一个表,点击编辑,。
步骤三:删除系统步骤
进入powerquery编辑器后,找到右边步骤面板,把【源】之后的步骤全部删除

步骤四:展开Data
点击Data列右侧的双箭头,如下图,点击确定。

步骤五:数据整理
到这里已经合并完成,

然后提升标题,删除需要的列。
步骤六:上载数据

然后数据就可以在Excel工作表中看到了。
仅仅点击几下鼠标,没有输入任何公式和代码,合并多个sheet的功能就完成了。
三、二维表转一维表
利用PowerQuery,二维表转为一维表十分方便,以Excel中常见的几种结构的表格为例,看看都是如何操作的。
第一种情形

简单的二维表,如本文的第一张图表,直接使用逆透视功能,就可以快速转为一维表,

可以选择需要透视的列进行“逆透视”,也可以选择不需要透视的列,然后点击“逆透视其他列”来完成。
提示:这些操作,生成的最终一维表的列名,需要自己手动更改一下,下同。
第二种情形
行标题带有层级结构的二维表,如下,
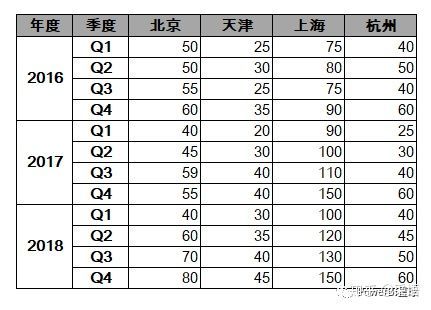
这种结构很清晰,但做数据分析最让人头疼的就是合并单元格,不过在PowerQuery中处理也并不困难,只是多了一些步骤。
将上表导入到PowerQuery编辑器后,先把年度列向下填充,将年度数据补齐,然后再进行逆透视,

第三种情形
列标题带有层级结构的二维表,如下,

这种表格可以先转置,转置以后,就是第二种情形,然后再进行逆透视就可以了,
第四种情形
行标题和列标题均带有层次结构,如下图,

看起来更复杂是不是,其实同样是上述几个步骤灵活组合,
a. 将年度列向下填充,补齐数据

b. 将年度列和季度列合并,生成年度季度列,这种结构就变成第三种情形,

c. 转置表、把第一列向下填充,并提升标题,就变成了很简单的结构,也就是第二种情形,

d. 选中前两列,逆透视其他列,就变成了一维表
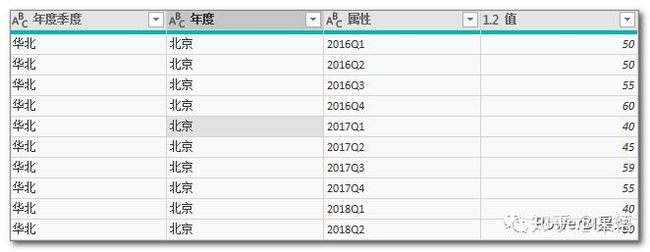
e. 为了和源数据维度一致,将年度季度列进行分列

至此就得到了最终的一维表,看起来步骤很多,其实熟练掌握了也就分分钟的事。
PowerQuery文本处理技巧:移除和提取
PowerQuery两个常用的 M 函数:Text.Remove 和 Text.Select。
看到以 Text 开头的,就知道是文本处理函数,比如原始数据如下,

如果只想要中文名,就是把英文字母都去掉,可以用Text.Remove函数,添加自定义列,
姓名=Text.Remove([客户],{"A".."Z"})

Text.Remove 的参数有两个,第一个就是文本,第二个就是要移除的字符,可以是文本或者是文本的列表,{"A".."Z"}就是生成了一个从A到Z的列表,只要是大写字母,就从客户的信息中移除。
如果有小写字母,需要把所有的字母都移除了,把大写的"Z"替换成小写的"z"就行了,
姓名=Text.Remove([客户],{"A".."z"})
如果只想要英文名,要去掉中文名,可以这样写,
英文名=Text.Remove([客户],{"一".."龟"})
Powerquery 的中文字符以 Unicode 连续储存,"一"的 Unicode最小,正常使用的汉字中,"龟"的 Unicode 最大,因此{"一".."龟"}就包含了所有正常使用的汉字列表,正好利用这个特性,去除了所有的中文字符。
如果有更多种类的文本数据不规则的堆放在一起,比如这样,
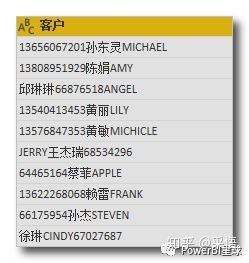
想把联系方式提取出来,第二个参数还可以这样写,
联系方式=Text.Remove([客户],{"A".."z","一".."龟"})
把中文字符和英文字符的列表都放到第二个参数中,全部移除。

不过如果字符种类很多,像这样更加杂乱的,

要提取联系方式,用Text.Remove 就有点麻烦,各种奇怪的符号种类太多了,编码也不一定连续。还好有一个 Text.Select 函数专门用来提取的。
Text.Select 函数和 Text.Remove 正好相反,Text.Select 只提取第二个参数中的字符,上图中提取联系方式,直接这样写,
联系方式=Text.Select([客户],{"0".."9"})

直接就可以得到联系方式信息。
提取各种字符的列表如下,

PowerQuery数据分列
Powerquery中还可以按从数字到非数字的转换来分列,

拆分列的常规功能中还可以按大小写字母的转换来进行分列,比如这样,
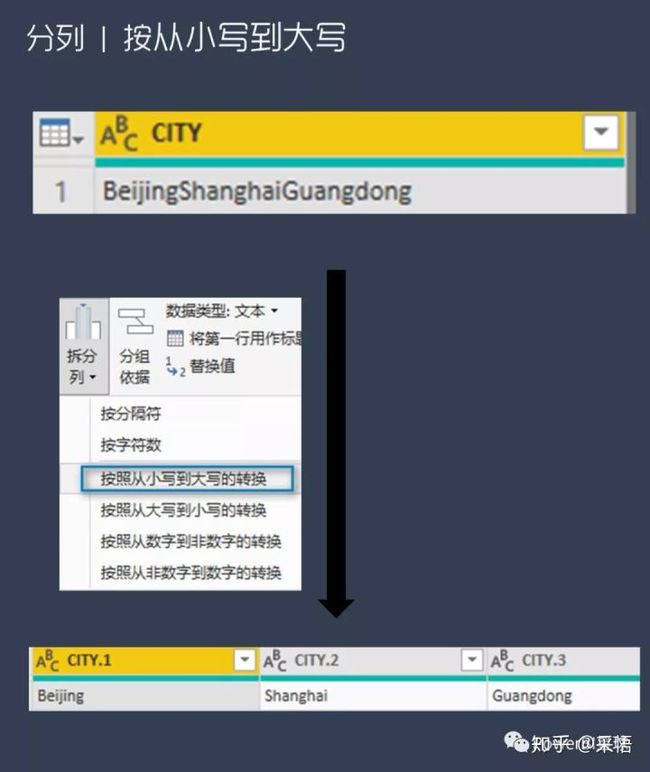
是不是非常方便呢。
分列到行
有时候数据都挤在一个单元格里,直接分列也可以,会分成一行多列的表,使用起来很不方便。
在PQ中,还可以直接分列到行中,直接点击按字符分列,弹出的窗口中展开"高级选项",拆分为行就可以了,
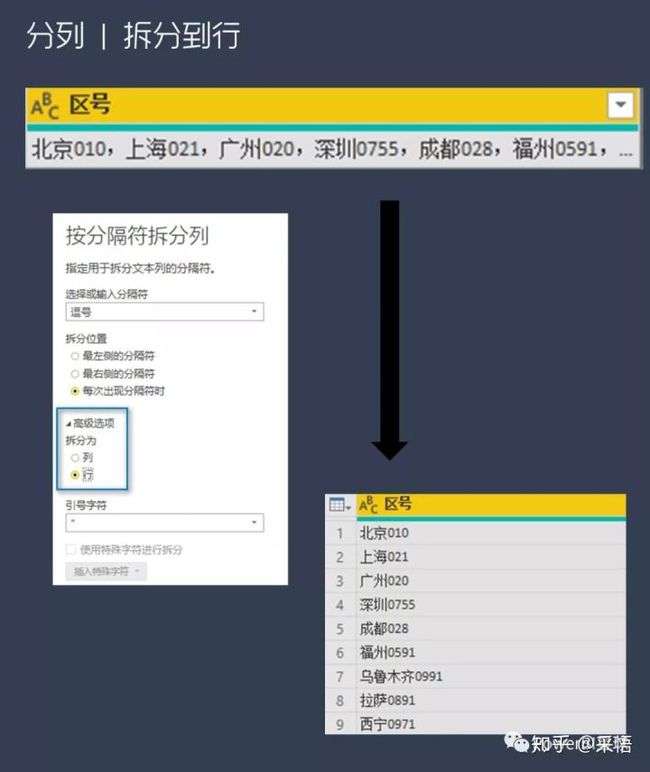
多种分隔符进行分列
有时候拿到的原始数据很不规范,可能是手工录入的很随意,分割符不只是一种,我们无论选择哪个都没法直接分开,像下图这样,
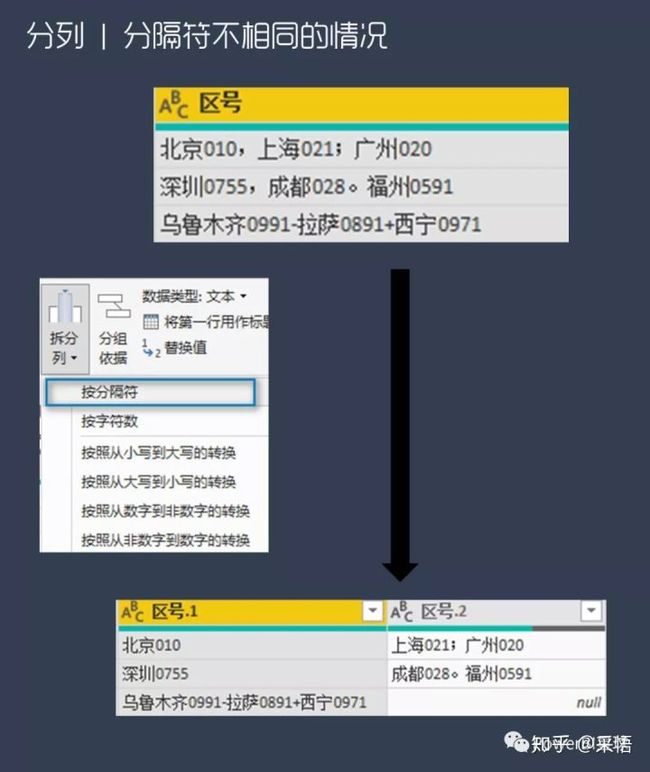
这时候,仅靠界面功能就难以正确分列了,不过PQ里还有丰富的M函数,这里我们就需要用M函数来完成。
以上图数据为例,碰到这种多中字符分割的情况,就不要再用拆分界面功能了,直接添加步骤,编辑框中输入,
=Table.SplitColumn(
提升的标题, "区号",
Splitter.SplitTextByAnyDelimiter(
{",",";","-","+","。"},
QuoteStyle.Csv
)
)
(其中提升的标题是上一个步骤的名称,使用时要更改为实际的步骤名,字符替换为实际数据的分隔符)
看起来有点长,其实主要是使用了Splitter.SplitTextByAnyDelimiter函数,并把所有的分隔符做成一个列表,作为该函数的第一个参数就可以了,效果如下,

关于分列,主要是找出数据排列的规律,是有固定的分隔符、有固定的字符数,还是有规律的从数字到文本等等,找到规律以后,就按规律进行拆分就可以了。
powerquery批量爬取网页数据
这里带你认识一下PowerQuery作为爬虫的功能。
(一)分析网址结构
打开智联招聘网站,搜索工作地点在上海的数据,
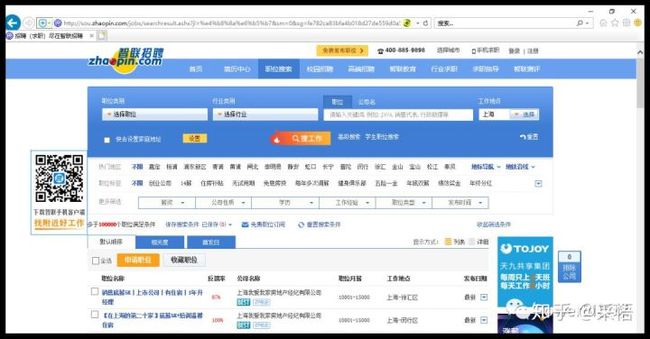
下拉页面到最下面,找到显示页码的地方,点击前三页,网址分别如下,
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字就是页码的ID,是控制分页数据的变量。
(二)使用PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,从弹出的窗口中选择【高级】,根据上面分析的网址结构,把除了最后一个页码ID的网址输入第一行,页码输入第二行,

从URL预览中可以看出,已经自动把上面两行的网址合并到一起;这里分开输入只是为了后面更清晰的区分页码变量,其实直接输入全网址也是一样可以操作的。
(如果页码变量不是最后一位,而是在中间,应该分三行输入网址)
点击确定后,发现出来很多表,

从这里可以看出,智联招聘网站上每一条招聘信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击编辑进入Power Query编辑器。
在PQ编辑器中直接删除掉【源】之后的所有步骤,然后展开数据,并把前面没有的几列数据删除。

这样第一页的数据就采集过来了。然后对这一页的数据进行整理,删除掉无用信息,添加字段名,可以看出一页包含60条招聘信息。
这里整理好第一页数据以后,下面进行采集其他页面时,数据结构都会和第一页整理后的数据结构一致,采集的数据可以直接拿来用;这里不整理也没关系,可以等到采集所有网页数据后一起整理。
如果要大批量的抓取网页数据,为了节省时间,对第一页的数据可以先不整理,直接进入下一步。
(三)根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p as number) as table =>

并把let后面第一行的网址中,&后面的"1"改为(这就是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后【源】的网址变为:
"http://sou.zhaopin.com/jobs/searchresult.ashx?jl=%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定以后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,把这个函数重命名为Data_Zhaopin.
到这里自定义函数完成,p是该函数的变量,用来控制页码,随便输入一个数字,比如7,将抓取第7页的数据,

输入参数只能一次抓取一个网页,要想批量抓取,还需要下面这一步。
(四)批量调用自定义函数
首先使用空查询建立一个数字序列,如果想抓取前100页的数据,就建立从1到100的序列,在空查询中输入
={1..100}
回车就生成了从1到100的序列,然后转为表格。gif操作图如下:
然后调用自定义函数,
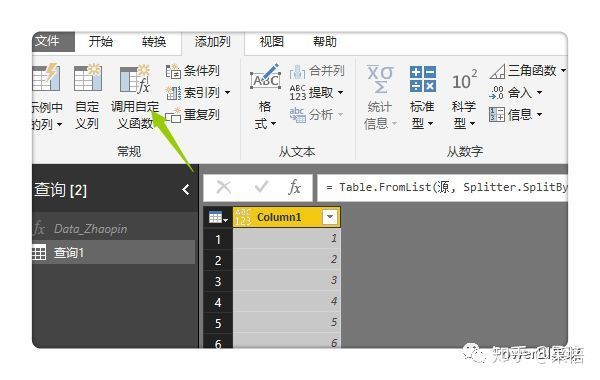
在弹出的窗口中点击【功能查询】下拉框,选择刚才建立的自定义函数Data_Zhaopin,其他都按默认就行,

点击确定,就开始批量抓取网页了,因为100页数据比较多,耗时5分钟左右,这也是我第二步提前数据整理造成的后果,导致抓取比较慢。展开这一个表格,就是这100页的数据,

至此,批量抓取智联招聘100页的信息完成,上面的步骤看起来很多,实际上熟练掌握以后,10分钟左右就可以搞定,最大块的时间还是最后一步进行抓取数据的过程比较耗时。
网页的数据是不断更新的,在操作完以上的步骤之后,在PQ中点击刷新,可以随时一键提取网站实时的数据,一次做好,终生受益!
PowerQuery调用API获取经纬度
关于什么是API就不再细说,可以自行搜索相关信息,下面直接介绍PowerQuery如何调用API,并返回一个位置信息的相关维度。
各大地图网站都有可供调用的API,这里我们使用高德地图的API,首先需要申请一个key,关于如何申请,请自行百度,有了这个key以后,就可以在PQ中开始操作了。
以返回"中央电视台总部大楼"所在的城市、辖区、经纬度等信息为例,来分步操作。
1、获取数据>web,输入网址:
https://restapi.amap.com/v3/geocode/geo?address=中央电视台总部大楼&output=XML&key=你申请的key
2、点击编辑进入pq编辑器中,

3、逐步展开Table中的数据并删除不必要的列,就可以得到我们想要的信息,

(调出来的信息很丰富,也包括国家、区号、结构化地址等信息,可以根据自己的需要来选择保留哪些列)
上面的这些步骤只是获取地址信息的sample,我们不能每查询一个地址都要操作一遍这些步骤,下面才是重点。
还记得之前介绍的自定义函数吗?(认识Power Query的自定义函数),这里就是将以上的步骤封装成一个函数,随时调用。
右键该表>创建函数,

输入一个函数名,自己随便写,不冲突就可以,我这里用location作为函数名,这样就建好了一个自定义函数location。
然后打开这个自定义函数的代码,在括号中输入参数,并将地址更改为参数,比如参数设为x,将上面步骤中的“中央电视台总部大楼”替换为参数x。然后这个自定义函数就建好了。
如果想找到上海东方明珠的位置信息,直接输入参数框并调用即可,

对于批量的地址,还可以直接通过添加列来批量调用自定义函数location,

利用PowerQuery调用API是不是很强大呢,全程没有输入一行代码,只是通过界面操作,点点鼠标,就批量获得你想要的各类地址信息。
PDF转Excel
可以从多种数据格式、多种来源获取数据,PDF格式的数据文件也不例外。
下面来看看操作步骤。
假设有一个PDF文件,128页,

点击获取数据,选择PDF格式,

点击确认后,连接本地PDF文件,

可以看到有128个表格,每页PDF就是一张表格,这里随便选择一个文件,点击编辑,进入查询编辑器,

其实到此处,数据都已经导入到PowerBI中了,剩下的就是整理的过程,把128页文件合并到一张表中,和合并128个excel文件的步骤是一样的,




合并后的数据可以加载,直接进行数据分析。
如果你刚开始接触Power BI,可在微信公众号“PowerBI星球”后台回复"PowerBI",获取《七天入门PowerBI》电子书,轻松上手。