文档结构:

oracle执行计划使用场景
环境:
Centos 6.10
Oracle 18.3.0.0.0 c
11g默认启动了自动统计信息收集的任务,默认运行时间是周一到周五晚上10点和周6,周天的早上6点,这种自动收集统计信息的方式并不是收集所有对象的统计信息,而是收集没有统计信息的对象和统计信息过旧的对象。然后确定优先级,再开始进行统计信息。
Job 名称是GATHER_STATS_JOB, 该Job收集数据库所有对象的2种统计信息:
(1)Missing statistics(统计信息缺失)
(2)Stale statistics(统计信息陈旧)
以及对应的如下:
(1)对象的统计信息之前没有收集过。
(2)当对象有超过10%的rows 被修改,此时对象的统计信息也称为stale statistics。比如说白天truncate表了或者进行delete 超过10%的行。
select window_name,
window_next_time,
autotask_status,
optimizer_stats
from DBA_AUTOTASK_WINDOW_CLIENTS;

select client_name,status from dba_autotask_client
where client_name='auto optimizer stats collection';

- 统计信息
- 动态采样
1. 统计信息默认情况下是每晚10点半后收集,如果新建对象还没来得级收集统计信息,
就采用动态采样的方式。
2. 具体在set autotrace 跟踪的执行计划中,可以看到类似:- dynamic sampling
used for this statement (level=2)
3. 除非你用类似/*+dynamic_sampling(t 0) */的HINT关闭这个动态采样。
4. 在收集过统计信息后,Oracle就不会采用动态采样。
注:建索引过程中,默认会收集索引相关的统计信息。
set autotrace off
set linesize 1000
drop table t_sample purge;
create table t_sample as select * from dba_objects;
create index idx_t_sample_objid on t_sample(object_id);
select num_rows, blocks, last_analyzed from user_tables
where table_name = 'T_SAMPLE';

--建索引后,自动收集统计信息。
select index_name,
num_rows,
leaf_blocks,
distinct_keys,
last_analyzed
from user_indexes
where table_name = 'T_SAMPLE';

select * from t_sample where object_id=20;

可以查看那个是动态采样
exec dbms_stats.gather_table_stats(ownname => 'sys',tabname => 'T_SAMPLE',estimate_percent => 10,method_opt=> 'for all indexed columns',cascade=>TRUE) ;
set autotrace off
select num_rows, blocks, last_analyzed
from user_tables
where table_name = 'T_SAMPLE';

可以查看到有最后一次统计信息收集的时间了。
以下是平时分区表印记分区索引,直方图,统计信息收集的一些笔记:
--查看表的情况
select table_name,num_rows, blocks, empty_blocks, avg_space, chain_cnt, avg_row_len,last_analyzed from user_tables; --普通表
select * from user_tab_partitions;--分区表
select table_name,partition_name,subpartition_name,num_rows, blocks, empty_blocks, avg_space, chain_cnt, avg_row_len,last_analyzed from user_tab_subpartitions; --子分区
select table_name,
partitioning_type,
subpartitioning_type,
partition_count
from user_part_tables
where subpartitioning_type <> 'NONE'; --查看分区表中带子分区的个数
--当前用户下,某个分区的记录数是平均记录数的2倍以上
set linesize 266
col table_name format a20
select table_name,
max(num_rows),
trunc(avg(num_rows),0),
sum(num_rows),
trunc(max(num_rows) / sum(num_rows),2),
count(*)
from user_tab_partitions
group by table_name
having max(num_rows) / sum(num_rows) > 2 / count(*);
--查看有子分区的数据情况:
select table_name,partition_name,subpartition_name,
num_rows
--索引列的统计信息
BLEVEL, --索引的层数
LEAF_BLOCKS, --叶子结点的个数
DISTINCT_KEYS, --唯一值的个数
AVG_LEAF_BLOCKS_PER_KEY, --每个KEY的平均叶块个数
AVG_DATA_BLOCKS_PER_KEY, --每个KEY的平均数据块个数
CLUSTERING_FACTOR --群集因子
select index_name,table_name,blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key,avg_data_blocks_per_key, clustering_factor from user_indexes; --普通表
select index_name,"COMPOSITE",SUBPARTITION_COUNT,PARTITION_NAME,blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key,avg_data_blocks_per_key, clustering_factor from user_ind_partitions --分区表
--查看普通索引失效:
select t.index_name,
t.table_name,
blevel,
t.num_rows,
t.leaf_blocks,
t.distinct_keys
from user_indexes t
where status = 'INVALID';
--查看分区索引失效:
select t.index_name,
t.table_name,
blevel,
t.num_rows,
t.leaf_blocks,
t.distinct_keys
from user_ind_subpartitions t
where index_name in (select index_name from user_indexes)
and status = 'INVALID'
--查看子分区索引
select t.index_name,
t.partition_name,
blevel,
t.num_rows,
t.leaf_blocks,
t.distinct_keys
from user_ind_subpartitions t
where index_name in (select index_name from user_indexes)
and status = 'INVALID'
分区表和子分区表
select index_name,PARTITION_NAME,SUBPARTITION_NAME,blevel,leaf_blocks,distinct_keys, avg_leaf_blocks_per_key,avg_data_blocks_per_key, clustering_factor from user_ind_subpartitions; --子分区表
查看直方图:
SELECT table_name,column_name, num_distinct,low_value, high_value, density, num_nulls, num_buckets, histogram from user_tab_columns;
select * from user_tab_histograms;
select * from user_part_histograms;
select * from user_subpart_histograms;
查看列的信息:
NUM_DISTINCT, --唯一值的个数
LOW_VALUE, --列上的最小值
HIGH_VALUE, --列上的最大值
DENSITY, --选择率因子(密度)
NUM_NULLS, --空值的个数
NUM_BUCKETS, --直方图的BUCKET个数
HISTOGRAM --直方图的类型
直方图是一种列的特殊的统计信息,主要用来描述列上的数据分布情况,
SELECT table_name,column_name, num_distinct,low_value, high_value, density, num_nulls, num_buckets, histogram from user_tab_columns ;
直方图:直方图意义:在oracle数据库中,CBO会默认认为目标列的数据量在其最小值和最大值之间是均匀分布的(最小值最大值不准确会导致谓词越界),
并且会按照这个均匀分布原则来计算对目标列事假的where查询条件后的可选这率及结果集的cardinality,进而据此来计算成本值并选择执行计划。但是,目标列的数据是均匀分布的按照这个原则选择执行计划是正确的;
如果目标数据列分布不均匀,甚至是严重倾斜,分布极度不均匀,那么这个按照这个原则选择执行计划就不合适,甚至是错误的,为此我们需要对那些数据分布不均匀的列进行直方图收集。
直方图实际存储在数据字典sys.histgrm$中,可以通过数据字典dba_tab_historgrams,dba_part_histograms和dba_subpart_histograms来分别查看表,分区表的分区和分区表的子分区的直方图信息。
收集统计信息的语句:
analyze 命令的语法如下:
analyze table tablename compute statistics;
analyze table tablename compute statistics for all indexes;
analyze table tablename delete statistics;
dbms_stats.gather_table_stats 收集表、列和索引的统计信息;
dbms_stats.gather_schema_stats 收集SCHEMA下所有对象的统计信息;
dbms_stats.gather_index_stats 收集索引的统计信息;
dbms_stats.gather_system_stats 收集系统统计信息
表统计信息的查看:
包含表行数,使用的块数,空的块数,块的使用率,行迁移和链接的数量,pctfree,pctused的数据,行的平均大小:
NUM_ROWS, --表中的记录数
BLOCKS, --表中数据所占的数据块数
EMPTY_BLOCKS, --表中的空块数
AVG_SPACE, --数据块中平均的使用空间
CHAIN_CNT, --表中行连接和行迁移的数量
AVG_ROW_LEN --每条记录的平均长度
统计信息的收集:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(ownname => 'hr',
tabname => 'employees',
estimate_percent => 100,
method_opt => 'for all columns size',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE);
END;
/
删除直方图的影响:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'hr',
tabname => 'employees',
estimate_percent => 100,
method_opt => 'for all columns size 1',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE);
END;
/
for all columns size 1 为所有size 放在一个桶里面(即为删除)
select a.table_name,a.column_name,
b.num_rows,
a.num_distinct Cardinality,
round(a.num_distinct / b.num_rows * 100, 2) selectivity,
a.histogram,
a.num_buckets
from user_tab_col_statistics a, user_tables b
where
a.table_name = b.table_name
oracle 一般查询数据行数在5%及以下,用到索引过略字段,CBO会走索引
生成了直方图之后 执行以下两个句子查看一下分别的执行计划对比看看
NUM_ROWS 表示总行数
CARDINALITY 表示基数
SELECTIVITY表示选择性 选择性在10%以上都比较高了
HISTOGRAM表示直方图的类型:
FREQUECNCY频率直方图、 当列中Distinct_keys 较少(小于254),如果不手工指定直方图桶数(BUCKET),Oracle就会自动的创建频率直方图,并且桶数(BUCKET)等于Distinct_Keys。
HEIGHT BALANCED 高度平衡直方图 当列中Distinct_keys大于254,如果不手工指定直方图桶数(BUCKET),Oracle就会自动的创建高度平衡直方图。
NONE表示未收集直方图
NUM_BUCKETS 表示桶数
3、疑问使用直方图的场合
1、直方图到底应该什么时候收集直方图?
就查一下执行计划和实际查询行数进行比较 估算的基数ROWS是不是算错了。
构造直方图最主要的原因就是帮助优化器在表中数据严重偏斜时做出更好的规划
注意:如果查询不引用该列,则创建直方图没有意义。这种错误很常见,许多 DBA 会在偏差列上创建柱状图,即使没有任何查询引用该列。
2、只对有索引的列收集直方图也是错的!
3、直方图究竟是干嘛的?
告诉CBO 有没有收集直方图 这个列是不是均衡的
1. 没收集直方图 ---CBO认为这个列是分布均匀的
2. 收集过了 ---告诉CBO这个列数据有问题 分布不均衡,特别是频率直方图算的会很准
最终就是影响rows
获取执行计划的6种方法
1. explain plan for获取
2. set autotrace on
3. statistics_level=all
4. 通过dbms_xplan.display_cursor输入sql_id参数直接获取
5. 10046 trace跟踪
6. awrsqrpt.sql
方法1(explain plan for)
类似PLSQL DEVELOPER里的F5
/*
步骤1:explain plan for "你的SQL"
步骤2:select * from table(dbms_xplan.display());
*/
set linesize 1000
set pagesize 2000
explain plan for
SELECT *
FROM t1, t2
WHERE t1.id = t2.t1_id
AND t1.n in(18,19);
select * from table(dbms_xplan.display());

优点: 1.无需真正执行,快捷方便
缺陷: 1.没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);
2.无法判断是处理了多少行;
3.无法判断表被访问了多少次。
确实啊,这毕竟都没有真正执行又如何得知真实运行产生的统计信息。
方法2(set autotrace on 方式)
有如下几种方式:
set autotrace on (得到执行计划,输出运行结果)
set autotrace traceonly (得到执行计划,不输出运行结果)
set autotrace traceonly explain (得到执行计划,不输出运行结果和统计信息部分,仅展现执行计划部分)
set autotrace traceonl statistics(不输出运行结果和执行计划部分,仅展现统计信息部分)
set autotrace on
SELECT *
FROM t1, t2
WHERE t1.id = t2.t1_id
AND t1.n in(18,19);

优点:1.可以输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);
2.虽然必须要等语句执行完毕后才可以输出执行计划,但是可以有traceonly开关来控制返回结果不打屏输出。
方法3(statistics level=all的方式)
步骤1:alter session set statistics_level=all ;
步骤2:在此处执行你的SQL
步骤3:select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

set autotrace off
alter session set statistics_level=all ;
SELECT *
FROM t1, t2
WHERE t1.id = t2.t1_id
AND t1.n in(18,19);
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

另注:
1. 如果你用 /*+ gather_plan_statistics */的方法,可以省略步骤1,直接步骤2,3。
2. 关键字解读(其中OMem、1Mem和User-Mem在后续的课程中会陆续见到):
Starts为该sql执行的次数。
E-Rows为执行计划预计的行数。
A-Rows为实际返回的行数。A-Rows跟E-Rows做比较,就可以确定哪一步执行计划出了问题。
A-Time为每一步实际执行的时间(HH:MM:SS.FF),根据这一行可以知道该sql耗时在了哪个地方。
Buffers为每一步实际执行的逻辑读或一致性读。
Reads为物理读。
OMem:当前操作完成所有内存工作区(Work Aera)操作所总共使用私有内存(PGA)中工作区的大小,
这个数据是由优化器统计数据以及前一次执行的性能数据估算得出的
1Mem:当工作区大小无法满足操作所需的大小时,需要将部分数据写入临时磁盘空间中(如果仅需要写入一次就可以完成操作,
就称一次通过,One-Pass;否则为多次通过,Multi_Pass).该列数据为语句最后一次执行中,单次写磁盘所需要的内存
大小,这个由优化器统计数据以及前一次执行的性能数据估算得出的
User-Mem:语句最后一次执行中,当前操作所使用的内存工作区大小,括号里面为(发生磁盘交换的次数,1次即为One-Pass,
大于1次则为Multi_Pass,如果没有使用磁盘,则显示OPTIMAL)
OMem、1Mem为执行所需的内存评估值,0Mem为最优执行模式所需内存的评估值,1Mem为one-pass模式所需内存的评估值。
0/1/M 为最优/one-pass/multipass执行的次数。Used-Mem耗的内存
--优点:1.可以清晰的从STARTS得出表被访问多少。
2.可以清晰的从E-ROWS和A-ROWS中得到预测的行数和真实的行数,从而可以准确判断Oracle评估是否准确。
3.虽然没有专门的输出运行时的相关统计信息,但是执行计划中的BUFFERS就是真实的逻辑读的多少
--缺陷:1.必须要等到语句真正执行完毕后,才可以出结果。
2.无法控制记录输屏打出,不像autotrace有 traceonly 可以控制不将结果打屏输出。
3.看不出递归调用的次数,看不出物理读的多少(不过逻辑读才是重点)
方法4(dbms_xplan.display_cursor)
select * from table(dbms_xplan.display_cursor('&sq_id')); (该方法是从共享池里得到)
注:
1. 还有一个方法,select * from table(dbms_xplan.display_awr('&sq_id'));(这是awr性能视图里获取到的)
2. 如果有多执行计划,可以用类似方法查出
先通过v$sql查看sql_id:
select * from table(dbms_xplan.display_cursor('1a914ws3ggfsn',0));
select * from table(dbms_xplan.display_cursor('1a914ws3ggfsn',1));
这个好处就是可以查看该sql多个执行计划

从中可以看出:
--优点:1.知道sql_id立即可得到执行计划,和explain plan for 一样无需执行;
2.可以得到真实的执行计划。(停,等等,啥真实的,刚才这几个套路中,还有假的执行计划的吗?)
--缺陷 1.没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);
2.无法判断是处理了多少行;
3.无法判断表被访问了多少次。
方法5(10046TRACE)
(10046TRACE)
步骤1:alter session set events '10046 trace name context forever,level 12'; (开启跟踪)
步骤2:执行你的语句
步骤3:alter session set events '10046 trace name context off'; (关闭跟踪)
步骤4:找到跟踪后产生的文件
步骤5:tkprof trc文件 目标文件 sys=no sort=prsela,exeela,fchela (格式化命令)
set autotrace off
alter session set statistics_level=typical;
alter session set events '10046 trace name context forever,level 12';
SELECT *
FROM t1, t2
WHERE t1.id = t2.t1_id
AND t1.n in(18,19);
alter session set events '10046 trace name context off';
12c之前查看trace文件:
select d.value
|| '/'
|| LOWER (RTRIM(i.INSTANCE, CHR(0)))
|| '_ora_'
|| p.spid
|| '.trc' trace_file_name
from (select p.spid
from v$mystat m,v$session s, v$process p
where m.statistic#=1 and s.sid=m.sid and p.addr=s.paddr) p,
(select t.INSTANCE
FROM v$thread t,v$parameter v
WHERE v.name='thread'
AND(v.VALUE=0 OR t.thread#=to_number(v.value))) i,
(select value
from v$parameter
where name='user_dump_dest') d;
12c之后 查看trace文件:
select d.value
|| '/'
|| LOWER (RTRIM(i.INSTANCE, CHR(0)))
|| '_ora_'
|| p.spid
|| '.trc' trace_file_name
from (select p.spid
from v$mystat m,v$session s, v$process p
where m.statistic#=1 and s.sid=m.sid and p.addr=s.paddr) p,
(select t.INSTANCE
FROM v$thread t,v$parameter v
WHERE v.name='thread'
AND(v.VALUE=0 OR t.thread#=to_number(v.value))) i,
(select value from v$diag_info where name='Diag Trace') d;
exit
tkprof /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_17496.trc /home/oracle/10046.txt
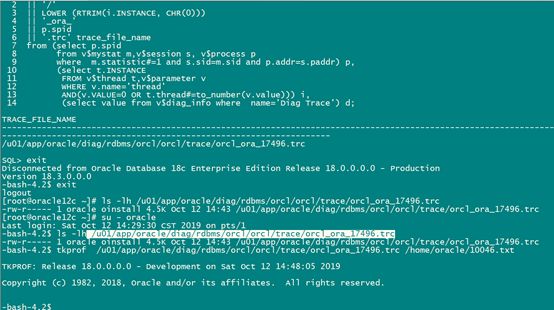
more /home/oracle/10046.txt
TKPROF: Release 18.0.0.0.0 - Development on Sat Oct 12 14:48:05 2019
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Trace file: /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_17496.trc
Sort options: default
********************************************************************************
count = number of times OCI procedure was executed
cpu = cpu time in seconds executing
elapsed = elapsed time in seconds executing
disk = number of physical reads of buffers from disk
query = number of buffers gotten for consistent read
current = number of buffers gotten in current mode (usually for update)
rows = number of rows processed by the fetch or execute call
********************************************************************************
SELECT *
FROM t1, t2
WHERE t1.id = t2.t1_id
AND t1.n in(18,19)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 14 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 14 0 2
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: SYS
Number of plan statistics captured: 1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
---------- ---------- ---------- ---------------------------------------------------
2 2 2 HASH JOIN (cr=14 pr=0 pw=0 time=474 us starts=1 cost=8 size=250 card=2)
2 2 2 NESTED LOOPS (cr=14 pr=0 pw=0 time=467 us starts=1 cost=8 size=250 card=2)
2 2 2 NESTED LOOPS (cr=12 pr=0 pw=0 time=584 us starts=1 cost=8 size=250 card=2)
2 2 2 STATISTICS COLLECTOR (cr=7 pr=0 pw=0 time=434 us starts=1)
2 2 2 INLIST ITERATOR (cr=7 pr=0 pw=0 time=395 us starts=1)
2 2 2 TABLE ACCESS BY INDEX ROWID BATCHED T1 (cr=7 pr=0 pw=0 time=391 us starts=2 cost=4 size=118 car
d=2)
2 2 2 INDEX RANGE SCAN T1_N (cr=5 pr=0 pw=0 time=347 us starts=2 cost=2 size=0 card=2)(object id 741
71)
2 2 2 INDEX RANGE SCAN T2_T1_ID (cr=5 pr=0 pw=0 time=147 us starts=2 cost=1 size=0 card=1)(object id 74
172)
2 2 2 TABLE ACCESS BY INDEX ROWID T2 (cr=2 pr=0 pw=0 time=35 us starts=2 cost=2 size=66 card=1)
0 0 0 TABLE ACCESS FULL T2 (cr=0 pr=0 pw=0 time=0 us starts=0 cost=2 size=66 card=1)
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
Disk file operations I/O 1 0.00 0.00
SQL*Net message to client 2 0.00 0.00
SQL*Net message from client 2 7.36 7.36
********************************************************************************
SQL ID: 06nvwn223659v Plan Hash: 0
alter session set events '10046 trace name context off'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.00 0.00 0 0 0 0
Misses in library cache during parse: 0
Parsing user id: SYS
********************************************************************************
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 14 0 2
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 6 0.00 0.00 0 14 0 2
Misses in library cache during parse: 0
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
Disk file operations I/O 2 0.00 0.00
SQL*Net message to client 3 0.00 0.00
SQL*Net message from client 3 7.36 14.08
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 0 0.00 0.00 0 0 0 0
Execute 0 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 0 0.00 0.00 0 0 0 0
Misses in library cache during parse: 0
2 user SQL statements in session.
0 internal SQL statements in session.
2 SQL statements in session.
********************************************************************************
Trace file: /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_17496.trc
Trace file compatibility: 12.2.0.0
Sort options: default
1 session in tracefile.
2 user SQL statements in trace file.
0 internal SQL statements in trace file.
2 SQL statements in trace file.
2 unique SQL statements in trace file.
66 lines in trace file.
7 elapsed seconds in trace file.
--优点:1.可以看出SQL语句对应的等待事件(这个是level 12,0,4,8对应的是其他情况)
2.如果SQL语句中有函数调用,SQL中有SQL,将会都被列出,无处遁形。
3.可以方便的看出处理的行数,产生的物理逻辑读。
4.可以方便的看出解析时间和执行时间。
5.可以跟踪整个程序包
--缺陷: 1.步骤繁琐,比较麻烦
2.无法判断表被访问了多少次。
3.执行计划中的谓词部分不能清晰的展现出来。
方法6. awrsqrpt.sql
步骤1:@?/rdbms/admin/awrsqrpt.sql
步骤2:选择你要的断点(begin snap 和end snap)
步骤3:输入你的sql_id
结论
6种方法各自适用场合
1.如果某SQL执行很长时间才出结果戒返回丌了结果,这时就只能用方法1;
2.跟踪某条SQL最简单的方法是方法1,其次就是方法2;
3.如果想观察到某条SQL有多条执行计划的情况,只能用方法4和方法6;
4.如果SQL中含有函数,函数中套有SQL等多层调用,想准确分析只能使用方法5;
5.要想确保看到真实的执行计划,丌能用方法1和方法2;
6.要想获取表被访问的次数,只能使用方法3;
不真实的执行计划
执行计划中"真实执行计划” 是一个很重要的常识,这也就是方法1 和方法2 的最大缺陷了。 狠狠揪出本次即将被批斗的坏蛋:方法1的explain plan for和方法2的set autotrace on
例子主要是针对:绑定变量窥视与直方图
---构建T表,数据,及主键
---构建T表,数据,及主键
DROP TABLE t;
CREATE TABLE t
AS
SELECT rownum AS id, rpad('*',100,'*') AS pad
FROM dual
CONNECT BY level <= 1000;
ALTER TABLE t ADD CONSTRAINT t_pk PRIMARY KEY (id);
---收集统计信息
BEGIN
dbms_stats.gather_table_stats(
ownname => user,
tabname => 'T',
estimate_percent => 100,
method_opt => 'for all columns size 254'
);
END;
/
下面我们将会用多种方法来查看如下语句的执行计划
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
EXECUTE :id := 10;
SELECT count(pad) FROM t WHERE id < :id;
利用以上6中方法查看执行计划是否真实:
----方法1(explain plan for 的方式。类似PLSQL DEVELOPE里的F5)
set linesize 1000
set pagesize 2000
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
EXECUTE :id := 990;
explain plan for
SELECT count(pad) FROM t WHERE id < :id;
select * from table(dbms_xplan.display());
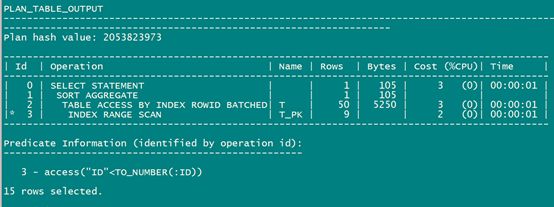
走的是索引范围扫描
----方法2(set autotrace on 方式)
set autotrace traceonly
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;

也是索引范围扫描
----方法3(statistics level=all的方式)
set autotrace off
alter session set statistics_level=all ;
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
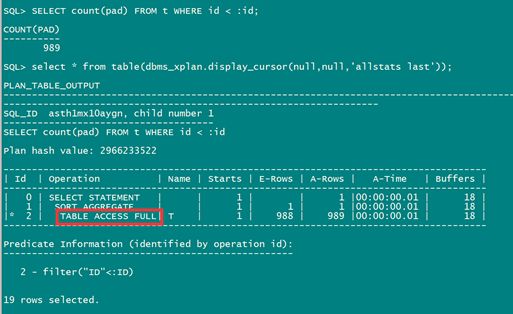
看到没有,全表扫描。
----方法4(知道sql_id后,直接带入的方式)
select * from table(dbms_xplan.display_cursor('asth1mx10aygn'));

也是全表扫描
----方法5(10046TRACE)
set autotace off
alter session set statistics_level=typical;
alter session set events '10046 trace name context forever,level 12';
VARIABLE id NUMBER
COLUMN sql_id NEW_VALUE sql_id
EXECUTE :id := 990;
SELECT count(pad) FROM t WHERE id < :id;
alter session set events '10046 trace name context off';
12c之后 查看trace文件:
select d.value
|| '/'
|| LOWER (RTRIM(i.INSTANCE, CHR(0)))
|| '_ora_'
|| p.spid
|| '.trc' trace_file_name
from (select p.spid
from v$mystat m,v$session s, v$process p
where m.statistic#=1 and s.sid=m.sid and p.addr=s.paddr) p,
(select t.INSTANCE
FROM v$thread t,v$parameter v
WHERE v.name='thread'
AND(v.VALUE=0 OR t.thread#=to_number(v.value))) i,
(select value from v$diag_info where name='Diag Trace') d;
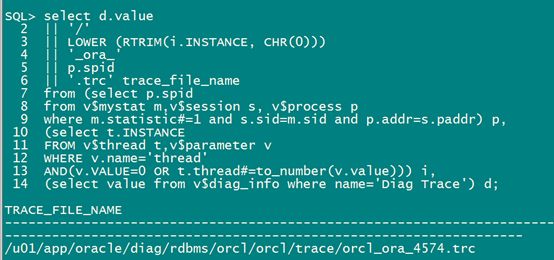
![]()
查看转换的文件:

也是全表扫描
一条SQL对应多个执行计划
执行计划中"一条SQL对应多个计划” 也是一个很重要的常识,这只能靠方法4和方法6了。
方法4的dbms_xplan.display_cursor+sql_id和方法6的awrsqrpt.sql
sys用户登录测试(切换了pdb):
DROP TABLE t;
CREATE TABLE t AS SELECT * FROM DBA_OBJECTS where object_id is not null;
create index idx_object_id on t(object_id);
alter table T modify object_id not null;
set autotrace off
set linesize 1000
set pagesize 2000
alter session set statistics_level=all ;
select count(*) from t;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
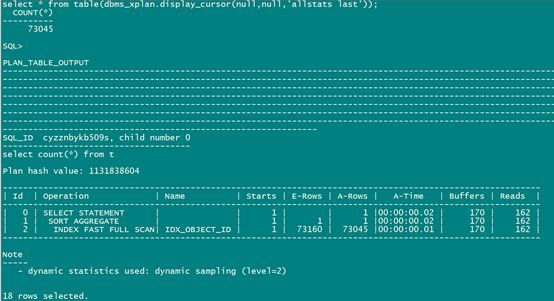
C##test用户登录测试(切换了pdb):
drop table t purge;
CREATE TABLE t AS SELECT rownum id ,rownum+1 n FROM DBA_OBJECTS ;
set autotrace off
set linesize 1000
set pagesize 2000
alter session set statistics_level=all ;
select count(*) from t;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));

可以查看是有两个(貌似pdb里面查询结果不对)
select sql_id, child_number from v$sql where sql_id='cyzznbykb509s';
SQL_ID CHILD_NUMBER
------------- ------------
cyzznbykb509s 0
cyzznbykb509s 1
特别说明一下,第6种获取执行计划的方法awrsqrpt.sql同样也可以获取到多条执行计划
这个方法当一条SQL有多个执行计划的时候,可以在报表里输出。但是要确保在AWR的采集周期内的生成报表。