学习Caffe第一件想干的事就是中文OCR。因为虽然数字OCR与英文OCR已经非常成熟(特别是印刷体的),但是如果说到中文OCR,那能搜索到的信息也是寥寥。但不断听说有人用Caffe做了不错的中文OCR识别,因此,内心也是痒痒。这篇文章,想先用Caffe作一个简单的中文OCR的测试。这里,将百家姓作为测试对象,并且只看黑体。希望可以先一窥Caffe识别的整体流程。
0. 训练集与测试集的准备
0.1 准备字符集
首先准备百家姓字符集:我在维基百科中,选择了2007年排名前一百的姓氏:
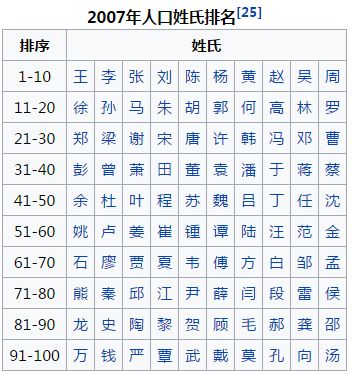
将它存储在family_name.txt中:王李张刘陈杨黄赵吴周徐孙马朱胡郭何高林罗郑梁谢宋唐许韩冯邓曹彭曾萧田董袁潘于蒋蔡余杜叶程苏魏吕丁任沈姚卢姜崔锺谭陆汪范金石廖贾夏韦傅方白邹孟熊秦邱江尹薛闫段雷侯龙史陶黎贺顾毛郝龚邵万钱严覃武戴莫孔向汤
一共100个字。
首先在我的图片库下创建文件夹family_name_db,然后在family_name_db下分别创建db,train_set和test_set三个文件夹
E:\Pictures\ImageDataBase\family_name_db>tree
E:.
├─db
├─test_set
└─train_set
0.2 转换成图片
然后,调用一段python代码,来生成最原始的图片集:
import os
import pygame
import Image
import StringIO
from os.path import join
def paste_word(word, dir_name, font_size, canvas_size):
'''输入一个文字,输出一张包含该文字的图片'''
pygame.init()
font = pygame.font.Font(join("./fonts", "simhei.ttf"), font_size)
#text = word.decode('utf-8')
if os.path.isdir(dir_name):
sub_dir = join(dir_name, word)
if not os.path.isdir(sub_dir):
os.mkdir(sub_dir)
else:
return
img_name = join(sub_dir, str(len(os.listdir(sub_dir))) + ".png")
paste(word, font, img_name, canvas_size, (0,0))
def paste(text, font, imgName, canvas_size, area = (3, 3)):
'''根据字体,将一个文字黏贴到图片上,并保存'''
im = Image.new("RGB", (canvas_size, canvas_size), (255, 255, 255))
rtext = font.render(text, True, (0, 0, 0), (255, 255, 255))
sio = StringIO.StringIO()
pygame.image.save(rtext, sio)
sio.seek(0)
line = Image.open(sio)
im.paste(line, area)
# im.show()
im.save(imgName)
if __name__ == "__main__":
file_path = raw_input('Please input the chinese characters text file: ')
while not os.path.isfile(file_path):
print file_path, ' not exist'
file_path = raw_input('Please re-input the chinese characters text file: ')
dir_path = raw_input('Please input the database dir: ')
while not os.path.isdir(dir_path):
print dir_path, ' not exist'
dir_path = raw_input('Please re-input the database dir: ')
f = open(file_path, 'r')
words = f.read()
words = words.decode('utf-8')
for w in words:
paste_word(w, dir_path, 48, 48)
由于我决定最终将文字都归一化到40x40大小。因此,我实际上运行了这个程序三次,第一次最后一行为:
paste_word(w, dir_path, 40, 40)
第二次为
paste_word(w, dir_path, 44, 44)
第三次为
paste_word(w, dir_path, 48, 48)
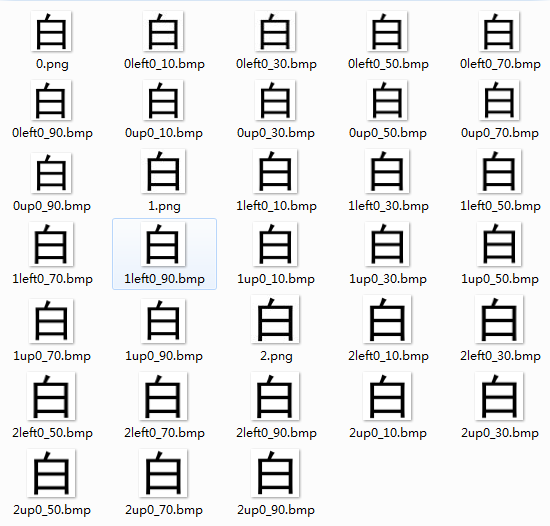
如此,在每个字符对应的文件夹中就得到了这样的三张图片:

0.3 生成训练集与测试集
接下来,利用上述生成的每个字三个样本,利用亚像素精度的位移,生成更多样本的训练集和测试集:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import os
import shutil
import filecmp
from ctypes import *
from os.path import join
def dir_copytree(src, dst):
names = [d.decode('gbk') for d in os.listdir(src)]
# 目标文件夹不存在,则新建
if not os.path.exists(dst):
os.mkdir(dst)
# 遍历源文件夹中的文件与文件夹
for name in names:
src_name = os.path.join(src, name)
dst_name = os.path.join(dst, name)
# 是文件夹则递归调用本拷贝函数,否则直接拷贝文件
if os.path.isdir(src_name):
dir_copytree(src_name, dst_name)
else:
if not os.path.exists(dst_name):
shutil.copy2(src_name, dst)
else:
if not filecmp.cmp(src_name, dst_name):
shutil.copy2(src_name, dst)
def sub_pixel_move(from_dir, to_dir, orients, steps):
# windll.LoadLibrary(join(r"D:\project\UniversalOCR\UniversalOCR_alg_dev\build-shared\bin\Debug", \
# "tinyxml2.dll"))
libgg = windll.LoadLibrary(join(r"D:\project\UniversalOCR\UniversalOCR_alg_dev\build-x64\bin\Debug",\
"gg_universal_ocr.dll"))
i_orient = 0
for o in orients:
if o == "up":
i_orient |= 1
elif o == "down":
i_orient |= 2
elif o == "left":
i_orient |= 4
elif o == "right":
i_orient |= 8
cwd = os.getcwd()
os.chdir(from_dir)
sub_dir = [d for d in os.listdir('.') if os.path.isdir(d)]
for sd in sub_dir:
pngs = [join(sd,f) for f in os.listdir(sd) if os.path.splitext(f)[-1] == ".png"]
dst_dir = join(to_dir, sd)
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
for p in pngs:
for s in steps:
ret_status = libgg.ggGenMoreSamples(os.path.abspath(p), dst_dir, c_double(s), i_orient, 2, None)
# print ret_status
os.chdir(cwd)
if __name__ == "__main__":
image_data_base = raw_input('Image data base dir: ')
while not os.path.isdir(image_data_base):
print(image_data_base, ' not exist')
image_data_base = raw_input('Please re-input image data base dir: ')
train_set_dir = raw_input('Train set dir: ')
if not os.path.isdir(train_set_dir):
os.mkdir(train_set_dir)
test_set_dir = raw_input('Test set dir:')
if not os.path.isdir(test_set_dir):
os.mkdir(test_set_dir)
print 'Use sub pixel move to generate more images'
train_sub_pixel_step = [0.1, 0.3, 0.5, 0.7, 0.9]
test_sub_pixel_step = [0.2, 0.4, 0.6, 0.8]
print 'image data base is: ', image_data_base
print 'train set dir: ', train_set_dir
print 'train sub-pixel step up and left: ', train_sub_pixel_step
print 'test sub-pixel step up and left: ', test_sub_pixel_step
print 'test set dir: ', test_set_dir
print 'Copying images from image data base to train set directory...'
dir_copytree(image_data_base, train_set_dir)
print 'Done.'
print 'Train set images generating: sub-pixel move upward and left...'
sub_pixel_move(image_data_base, train_set_dir, ["up", "left"], train_sub_pixel_step)
print 'Done.'
print 'Test set images generating: sub-pixel move upward and left...'
sub_pixel_move(image_data_base, test_set_dir, ["up", "left"], test_sub_pixel_step)
print 'Done.'
这里的关键代码
ret_status = libgg.ggGenMoreSamples(os.path.abspath(p), dst_dir, c_double(s), i_orient, 2, None)
我是调用的我自己写的另外一个C++程序。
/** 通过一个样本,生成多个样本
@param[in] in_img 输入图像
@param[in] out_dir 输出目录
@param[in] subpixel_step 亚像素步长,应当小于1
@param[in] orient 方向
@param[in] n_in 需要多少个样本
@param[out] n_out 实际生成了多少个样本
*/
GGAPI(int) ggGenMoreSamples(const char* in_img, const char* out_dir, double subpixel_step, int orient, int n_in, int* n_out);
至此,train_set中每个样本文件夹包含了33个对象,test_set中每个样本文件夹包含了24个对象。
1. 图像数据转换为db文件
参考:https://www.cnblogs.com/denny402/p/5082341.html
通过上述步骤,已经获得了训练集和测试集,它们是.bmp格式的图像,而且大小是不一致的。而在caffe中经常使用的数据类型是lmdb或leveldb。那么如何从原始的.bmp格式的文件转换到db格式文件呢?
打开caffe解决方案,可以看到在tools下,有一个工程,叫convert_imageset。使用这个工具,可以将图片文件转换成caffe框架中可以直接使用的db文件。在convert_imageset.cpp中,开头的注释是这么写的:
// This program converts a set of images to a lmdb/leveldb by storing them
// as Datum proto buffers.
// Usage:
// convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
//
// where ROOTFOLDER is the root folder that holds all the images, and LISTFILE
// should be a list of files as well as their labels, in the format as
// subfolder1/file1.JPEG 7
// ....
需要四个参数:
- FLAGS: 参数
-
-gray: 是否以灰度图的方式打开图片。程序调用opencv库中的imread()函数来打开图片,默认为false -
-shuffle: 是否随机打乱图片顺序。默认为false -
-backend: 需要转换成的db文件格式,可选为leveldb或lmdb,默认为lmdb -
-resize_width/resize_height: 改变图片的大小。在运行中,要求所有图片的尺寸一致,因此需要改变图片大小。 程序调用opencv库的resize()函数来对图片放大缩小,默认为0,不改变 -
-check_size: 检查所有的数据是否有相同的尺寸。默认为false,不检查 -
-encoded: 是否将原图片编码放入最终的数据中,默认为false -
-encode_type: 与前一个参数对应,将图片编码为哪一个格式:‘png','jpg'......
-
- ROOTFOLDER/: 图片存放的绝对路径
- LISTFILE: 图片文件列表清单,一般为一个txt文件,一行一张图片
- DB_NAME: 最终生成的db文件存放目录
现在首先来生成LISTFILE。注意,标签要从0开始!我一开始没注意,将标签设置为从1开始,结果训练的时候出现问题
import os
from os.path import join, isdir
def gen_listfile(dir):
cwd = os.getcwd()
os.chdir(dir)
sd = [d for d in os.listdir('.') if isdir(d)]
class_id = 0
with open(join(dir, 'listfile.txt'), 'w') as f:
for d in sd:
fs = [join(d,x) for x in os.listdir(d)]
for img in fs:
f.write(img + ' ' + str(class_id) + '\n')
class_id += 1
os.chdir(cwd)
if __name__ == "__main__":
root_dir = raw_input('image root dir: ')
while not isdir(root_dir):
raw_input('not exist, re-input please: ')
gen_listfile(root_dir)
生成后的列表为:
丁\0left0_20.bmp 0
丁\0left0_40.bmp 0
丁\0left0_60.bmp 0
丁\0left0_80.bmp 0
丁\0up0_20.bmp 0
丁\0up0_40.bmp 0
丁\0up0_60.bmp 0
丁\0up0_80.bmp 0
丁\1left0_20.bmp 0
丁\1left0_40.bmp 0
丁\1left0_60.bmp 0
丁\1left0_80.bmp 0
丁\1up0_20.bmp 0
丁\1up0_40.bmp 0
丁\1up0_60.bmp 0
丁\1up0_80.bmp 0
丁\2left0_20.bmp 0
丁\2left0_40.bmp 0
丁\2left0_60.bmp 0
丁\2left0_80.bmp 0
丁\2up0_20.bmp 0
丁\2up0_40.bmp 0
丁\2up0_60.bmp 0
丁\2up0_80.bmp 0
万\0left0_20.bmp 1
万\0left0_40.bmp 1
万\0left0_60.bmp 1
万\0left0_80.bmp 1
万\0up0_20.bmp 1
万\0up0_40.bmp 1
......
然后用以下的命令来生成数据库
F:\OpenSource\caffe\build\tools\Release\convert_imageset --shuffle ^
--gray --resize_height=40 --resize_width=40 ^
E:\Pictures\ImageDataBase\family_name_db\train_set\ ^
E:\Pictures\ImageDataBase\family_name_db\train_set\listfile.txt ^
E:\Pictures\ImageDataBase\family_name_db\train_set\fn_train_lmdb
F:\OpenSource\caffe\build\tools\Release\convert_imageset --shuffle ^
--gray --resize_height=40 --resize_width=40 ^
E:\Pictures\ImageDataBase\family_name_db\test_set\ ^
test_set\listfile.txt test_set\fn_test_lmdb
此时,即会生成fn_train_lmdb文件夹和fn_test_lmdb文件夹
2. 创建模型并测试
我借用了MNIST例子中的lenet模型。并且在caffe\examples目录下创建了family_name文件夹来存放各种模型的配置文件。并且将fn_train_lmdb文件夹和fn_test_lmdb文件夹也都拷贝到这个文件夹下:
F:\OPENSOURCE\CAFFE\EXAMPLES\FAMILY_NAME
│ lenet_solver.prototxt
│ lenet_train_test.prototxt
│ train_lenet.sh
│
├─fn_test_lmdb
│ data.mdb
│ lock.mdb
│
└─fn_train_lmdb
data.mdb
lock.mdb
lenet_solver.prototxt设置了训练需要的参数:
# The train/test net protocol buffer definition
net: "examples/family_name/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of family_name, we have test batch size 100 and 24 test iterations,
# covering the full 2,400 testing images.
test_iter: 24
# Carry out testing every 100 training iterations.
test_interval: 100
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/family_name/lenet"
# solver mode: CPU or GPU
solver_mode: GPU
lenet_train_test.prototxt定义了网络结构:
name: "LeNet"
layer {
name: "family_name"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/family_name/fn_train_lmdb"
batch_size: 33
backend: LMDB
}
}
layer {
name: "family_name"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/family_name/fn_test_lmdb"
batch_size: 100
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 1000
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 100
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
train_lenet.sh为运行训练的bash命令脚本
#!/usr/bin/env sh
set -e
./build/tools/Release/caffe train --solver=examples/family_name/lenet_solver.prototxt $@
在caffe的主目录下用cygwin运行这个脚本。
zhongc@zhongc-PC /cygdrive/f/OpenSource/caffe
$ ./examples/family_name/train_lenet.sh
最终生成的结果为:
I0418 08:11:10.970157 7868 solver.cpp:398] Test net output #0: accuracy = 1
I0418 08:11:10.970157 7868 solver.cpp:398] Test net output #1: loss = 0.000447432 (* 1 = 0.000447432 loss)
I0418 08:11:10.970157 7868 solver.cpp:316] Optimization Done.
I0418 08:11:10.970157 7868 caffe.cpp:260] Optimization Done.
说明测试集的正确率为100%。由于篇幅原因,暂且罢笔。下一篇文章将尝试使用c++ API识别单个图片。也就是再次探讨如何将自己训练的结果应用起来。