
【树莓派+Movidius计算棒】实现一个效果尚可的人脸识别系统。
【1】Camera
1)多线程
异步的摄像头接口,可以充分利用系统资源,提高识别效率。
capture_processing 图像捕获线程
camera 配置:数据源,FPS, Color Space, Frame Size。
frame 预处理:frame_preprocessor(frame)可以 resize,flip
inference 预处理:inference_processor(frame)可以 resize, tensor, color space, whiten, data type ...
图像缓存区(自动丢帧):建立图像缓冲区,后边AI应用算法处理不过来时,自动丢帧处理。
inference_processing AI 推断线程
默认是一个推断线程。也可以指定起多个推断线程。要处理好多个推断结果的时序问题。
整个项目总的AI推断接口inference(img, frame, timestamp)
返回一个用于展示的推断结果的集合:result_list
推断结果缓存区(每个推断线程,自有一个推断结果缓存区)
show_processing 图像结果输出线程
展示推断结果
draw(result_list, frame, tmsp)
根据需求也可以有其他的结果数据输出,例如发送到某服务器。send_report(result_list, tmsp)
2)自动跳针
图像缓存区,是一个先进先出的队列。如果排队比较长,可以隔帧丢弃,实现跳针。
排在队列前边的(时间越早)的,有更多机会被丢弃。
最大程度保证输出图像的时间连续。
if len(frame_list) > 10:
frame_list = frame_list[::2]
【2】FaceDetector
1)人脸识别
可设置Filter,控制检出人脸的位置,范围,大小,概率等
接口
inference(frame)
返回值
归一化的 box_list 例如:[{'x':0.1, 'y':0.1, 'w':0.2, 'h':0.2}, ...]
- OpenCV 的 cascade。常用的有模型:lbpcascade 或 haarcascade 系列。加大最小检出人脸的尺寸,可以提高检出效率。
OpenCV 模型:
lbpcascade_frontalface_improved.xml
haarcascade_frontalface_alt2.xml
haarcascade_fullbody.xml
# Demo
def opencv_face_detect(img, scale=1.2):
img_w = image.shape[1]
img_h = image.shape[0]
detector = cv2.CascadeClassifier('~/models/haarcascade_frontalface_alt2.xml')
scaleFactor = 1.1
minSize = (10, 10)
rects = detector.detectMultiScale(image, scaleFactor=scaleFactor, minSize=minSize, minNeighbors=4)
dets = []
for left, top, width, height in rects:
cx = (left + width / 2) / img_w
cy = (top + height / 2) / img_h
w = width / img_w * scale
h = height / img_h * scale
dets.append([cx,cy,w,h])
return dets
- dlib 提供了人脸识别
记得要在自己的 虚拟 python 环境下安装。
下载DLIB:http://dlib.net/files/dlib-19.16.tar.bz2
DLIB 支持 GPU,编译方法如下:
$ wget http://dlib.net/files/dlib-19.16.tar.bz2
$ tar xvf dlib-19.16.tar.bz2
$ cd dlib-19.16
$ python setup.py install --yes DLIB_USE_CUDA
# coding:utf-8
'''
脸部68个特征点检测
'''
import sys
import dlib
from skimage import io
import cv2
# 加载并初始化检测器
# 非 CNN 模型
detector1 = dlib.get_frontal_face_detector() #和opencv类似
# CNN 模型下载地址http://dlib.net/files/mmod_human_face_detector.dat.bz2
detector2 = dlib.cnn_face_detection_model_v1('../models/dlib/mmod_human_face_detector.dat')
detector = detector2
# 模型下载地址http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
predictor = dlib.shape_predictor('../models/dlib/shape_predictor_68_face_landmarks.dat')
camera = cv2.VideoCapture(0)
if not camera.isOpened():
print("cannot open camear")
exit(0)
while True:
ret,frame = camera.read()
if not ret:
continue
frame_new = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# 检测脸部
dets = detector(frame_new, 1)
print("Number of faces detected: {}".format(len(dets)))
# 查找脸部位置
for i, face in enumerate(dets):
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {} ".format(
i, face.left(), face.top(), face.right(), face.bottom()))
# 绘制脸部位置
cv2.rectangle(frame, (face.left(), face.top()), (face.right(), face.bottom()), (0, 255, 0), 1)
shape = predictor(frame_new, face)
# print(shape.part(0),shape.part(1))
# 绘制特征点
for i in range(68):
cv2.circle(frame,(shape.part(i).x,shape.part(i).y),3,(0,0,255),2)
cv2.putText(frame,str(i),(shape.part(i).x,shape.part(i).y),cv2.FONT_HERSHEY_COMPLEX,0.5,(255,0,0),1)
cv2.imshow("Camera",frame)
key = cv2.waitKey(1)
if key == 27:
break
cv2.destroyAllWindows()

- ssd-face 基于SSD网络的人脸识别
- yolov3 基于yolo 的人脸检测,需要自己来训练。
[yolo-face]

- 其他神经网络:R-CNN、Faster R-CNN、R-FCN 都可以做人脸识别,但需要考虑其效率和效果再选择。
2)人脸特征点对齐
检测出的人脸角度、朝向不统一,这会影响到后期的人脸匹配。
dlib 人脸特征点对齐 参考,进一步做图像处理,统一检出人脸的朝向。

# coding: utf-8
import cv2
import dlib
import sys
import numpy as np
import os
# 获取当前路径
current_path = os.getcwd()
# 指定你存放的模型的路径,我使用的是检测68个特征点的那个模型,
# predicter_path = current_path + '/model/shape_predictor_5_face_landmarks.dat'# 检测人脸特征点的模型放在当前文件夹中
predicter_path = current_path + '/model/shape_predictor_68_face_landmarks.dat'
face_file_path = current_path + '/faces/inesta.jpg'# 要使用的图片,图片放在当前文件夹中
print predicter_path
print face_file_path
# 导入人脸检测模型
detector = dlib.get_frontal_face_detector()
# 导入检测人脸特征点的模型
sp = dlib.shape_predictor(predicter_path)
# 读入图片
bgr_img = cv2.imread(face_file_path)
if bgr_img is None:
print("Sorry, we could not load '{}' as an image".format(face_file_path))
exit()
# opencv的颜色空间是BGR,需要转为RGB才能用在dlib中
rgb_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2RGB)
# 检测图片中的人脸
dets = detector(rgb_img, 1)
# 检测到的人脸数量
num_faces = len(dets)
if num_faces == 0:
print("Sorry, there were no faces found in '{}'".format(face_file_path))
exit()
# 识别人脸特征点,并保存下来
faces = dlib.full_object_detections()
for det in dets:
faces.append(sp(rgb_img, det))
# 人脸对齐
images = dlib.get_face_chips(rgb_img, faces, size=320)
# 显示计数,按照这个计数创建窗口
image_cnt = 0
# 显示对齐结果
for image in images:
image_cnt += 1
cv_rgb_image = np.array(image).astype(np.uint8)# 先转换为numpy数组
cv_bgr_image = cv2.cvtColor(cv_rgb_image, cv2.COLOR_RGB2BGR)# opencv下颜色空间为bgr,所以从rgb转换为bgr
cv2.imshow('%s'%(image_cnt), cv_bgr_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
3)活体检测
a.双目活体检测:
同时实时采集近红外和可见光两种图像,检测是否为真人

通过红外散点和双目图像,还原出图像的“深度”,获得脸部的立体3D模型。


b.连续性检测,即通过视频流连续检测,判断目标人物"是活的"
眨眼、张嘴 做活体识别

眨眼检测

摇头检测
弱:判断人脸是否在摇头。
强:根据特征点相对位置关系的变化,可判断出是否是一张2D人脸照片。
4)人脸匹配
计算128/512维向量的欧式距离,判定是否是一个人。
FaceNet 人脸ID
FaceNet 参考文章
FaceNet的好处是,可以在 CUDA 或 Movidius计算棒上运行。
[FaceNet Github]
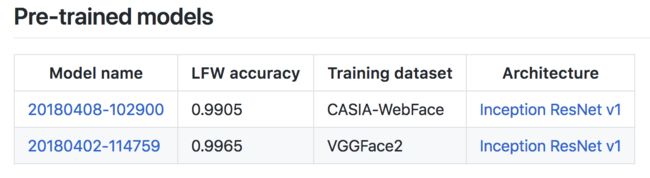
新的FaceNet模型是512维的人脸descriptor
dlib 人脸ID
dlib 参考文章
dlib 有CPU版本,和 CUDA 版本。但没办法在Movidius上跑。
shape_predictor_68_face_landmarks.dat:
http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
dlib_face_recognition_resnet_model_v1.dat:
http://dlib.net/files/dlib_face_recognition_resnet_model_v1.dat.bz2
批量欧式距离计算
欧式距离
2范数
需要匹配的人脸较多的时候,矩阵运算(而不是循环)计算欧式距离,可大幅提高效率。
def find_descriptor(face_db, descriptor):
temp = face_db.descriptors - descriptor
e = np.square(temp)
e = np.sum(e, axis=1)
# e = np.linalg.norm(temp, ord=2, axis=1, keepdims=True)
min_diff = e.min()
# min_diff *= min_diff
index = np.argmin(e)
return face_db.infos[index], min_diff
注意:
diff 通常是小于1的,如果开 , diff 会变大。训练的时候是有好处的,增加收敛速度。推断的时候就没必要了,反而不好看。所以我在推断的时候,就直接
5)视频中的人脸截取
我们在视频中,对一个人,连续截取人脸,与人脸库进行比对。但如何挑选质量最好的图像记录下来呢?人脸挑优问题,通常选清晰和正面朝向的人脸,认为这样会好。要计算图像清晰度,脸部3D朝向等。实现复杂,且实测效果不佳。
连续比对中,我选去 distance 最小的那个人脸图片,作为挑优的结果。(这么做有个前提,人脸库必须都是清晰且正向的人脸图片)。
6)人脸库比对动态阀值
如果一个人,我们并不知道他是不是我们人脸库里的人,此时就需要一个阀值来比较他与人脸库的 min_distance。

同一个人,站在不同位置,随着远近,截取的人脸图像尺寸有着近大远小。
大的照片清晰,小的照片不清晰。它们与人脸库的 min_distance 也随着距离增大而变大。
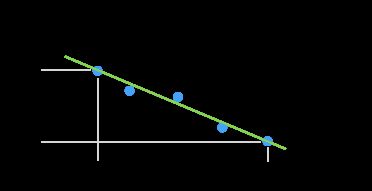
如图所示,实测 min_distance 随着与头像尺寸关系,用一次线性关系来表示。
FACE_THRESHOLD = lambda shape: (-43 / 40000) * min(shape[0], 160) + 0.453
特别注意,不同规格摄像头,成像质量不一致,镜头焦距不一致。同台阀值参数的设定,需要根据实测值重新计算。
7) 人脸画像:年龄、性别、表情、种族等
[人脸属性分析--性别、年龄和表情识别] 这里有很多开源的实现
我们采用的是:https://github.com/BoyuanJiang/Age-Gender-Estimate-TF
8)人脸聚类
将人脸映射到128 或 512维的数据空间中,计算彼此之间的距离。距离近的视作一个人,距离远的视作不是一个人,而判定的标准阈值由自己选定,通常是0.6
人脸聚类
【3】Face Tracking
通过检出人脸的时空属性,跟踪人脸位置,确定连续的两次检出是同一个人。
当 检出率>90% 和 FPS > 10时,才能有比较好的追踪效果。
1) 时空连续
时间关联衰减函数 attenuator( diff_time, k=1)
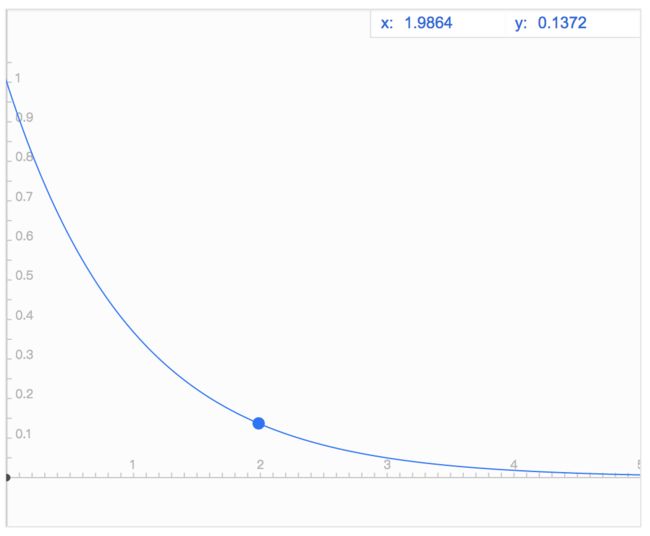 时间关联度函数
时间关联度函数
空间关联函数 :IoU_IoMin(box1, box2)

交并比
交比最小
一些特殊情况,可能会用到 交比最小。
时空关联函数:relateFace2Face(face1,face2)
当r小于一个阀值的时候,我们认为在时空关系上是连续的。
人脸检出率和FPS高时,可以设一个较高的r(如0.4)
人脸检出率和FPS较低时,r需要设一个较小值(如0.15)否则很容易跟丢。
这个办法的好处是,计算量非常小,非常的快。缺点是检出率和FPS比较低的时候,时空关联会非常小。容易跟丢了。
注意:用dlib的单目标追踪技术可以达到更好的追踪效果,计算成本会高些。
[dlib 目标追踪参考]
2)Face Profile
- 用face描述一张检测到的人脸,用 profile 来描述一个人。
- 根据不同帧,face的时空连续属性,来判定这个脸(face)属于哪个人(profile)
face
□[face] ├─□[box] │ ├─ ☞[h]: 0.40 │ ├─ ☞[w]: 0.30 │ ├─ ☞[x]: 0.10 │ └─ ☞[y]: 0.10 ├─ ☞[category]: 1 # 0:finding... 1:staff 2:visitor ├─ ☞[feature]: np.ndarray:(1, 128) ├─ ☞[diff]: 0.24 ├─ ☞[img]: 'cv_img' ├─ ☞[name]: '张三' └─ ☞[tmsp]: 1534604717.47
Profile
□[profile] ├─ ☞[cap_flag]: 1 ├─ ☞[category]: 1 ├─ ☞[color]: (255,0,0) ├─ ☞[display_name]: '张三' ├─□[faces]: list(1) │ └─□[0] │ ├─□[box] │ │ ├─ ☞[h]: 0.40 │ │ ├─ ☞[w]: 0.30 │ │ ├─ ☞[x]: 0.10 │ │ └─ ☞[y]: 0.10 │ ├─ ☞[category]: 1 │ ├─ ☞[diff]: 0.24 │ ├─ ☞[feature]: np.ndarray:(1, 128) │ ├─ ☞[img]: 'cv_img' │ ├─ ☞[name]: '张三' │ └─ ☞[tmsp]: 1534605778.75 ├─□[latest_face] │ ├─□[box] │ │ ├─ ☞[h]: 0.40 │ │ ├─ ☞[w]: 0.30 │ │ ├─ ☞[x]: 0.10 │ │ └─ ☞[y]: 0.10 │ ├─ ☞[name]: '张三' │ └─ ☞[tmsp]: 1534605778.75 └─ ☞[uudi]: '96a17322-a2fa-11e8-973a-8c85907905a8'
3)Tracking Update
step1:删除 超时 profiles
接口:del_timeout_profiles(cur_tmsp)
说明:删除连续 x 秒(例如:2秒)没有更新跟踪状态的人脸profile。识别率 和 FPS越高,阀值x可以设置的越小,效果越好。
step2:根据时空连续性,匹配人脸。
匹配上了,更新profile:update_profile(profile, face)
没匹配上,创建profile:create_profile(face)