在连续写了Android DisplayList 构建过程和Android 同步DisplayList信息后,接下来就是绘制DisplayList了
不过有个问题? 要将这些DisplayList绘制到什么地方去呢? 答案是Surface的Buffer中,
在syncFrameState中会调用makeCurrent会将EGL surface与RenderThread绑定,在绑定过程中会触发Native Window(也就是Surface)dequeueBuffer/requestBuffer去向SurfaceFlinger申请一块图形缓冲区(也就是一块与SurfaceFlinger都同时映射到的一块共享匿名内存, 由GraphicBuffer表示出map的地址,文件句柄相关). 这部分内容请参考SurfaceFlinger中Buffer的创建与显示. 所以在绘制之前Buffer已经准备好啦!
回到DrawFrameTask::run, 调用CanvasContext->draw便开始绘制DisplayList了
void DrawFrameTask::run() {
...
if (CC_LIKELY(canDrawThisFrame)) {
context->draw();
}
...
}
一、 计算dirty区域
Android 同步DisplayList信息已经计算出了脏区域,但是这个脏区域是画布的脏区域,画布是无限大的,那么有可能dirty区域就是无限大的。事实上如果第一次绘制时确实是无限大的。
而现在计算脏区域是相对于具体的屏幕。
在 CanvasContext::draw函数里
SkRect dirty;
mDamageAccumulator.finish(&dirty); //从DamageAccumulator中获得脏区域
由Android 同步DisplayList信息可知,在完成syncFrameState(也就是DisplayList信息同步完成)后,当前的脏区域保存在DamageAccumulator里, 通过调用DamageAccumulator.finish后就可以获得脏区域。
本文的例子是第一次绘制,所以这里的脏区域是整张画布,也就是无限大的区域。
Frame frame = mEglManager.beginFrame(mEglSurface); //获得frame
if (frame.width() != mLastFrameWidth || frame.height() != mLastFrameHeight) {
dirty.setEmpty();
mLastFrameWidth = frame.width();
mLastFrameHeight = frame.height();
} else if (mHaveNewSurface || frame.bufferAge() == 0) {
// New surface needs a full draw
dirty.setEmpty();
} else {
if (!dirty.isEmpty() && !dirty.intersect(0, 0, frame.width(), frame.height())) {
dirty.setEmpty();
}
profiler().unionDirty(&dirty);
}
if (dirty.isEmpty()) {
dirty.set(0, 0, frame.width(), frame.height());
}
bufferAge something... (略过)
mEglManager.damageFrame(frame, dirty); //通过android extension调用
beginFrame函数有两个作用
一个是查询真正画布(mEGLSurface)的大小(长,宽),
本例的大小是(1200x1920)另一个是校验 EGLDisplay和 Surface
最后脏区域就被重新设置成了(0, 0, 1200, 1920)了, 并通过damageFrame中的eglSetDamageRegionKHR来设置 dirty 区域,以标明脏区域。
二、绘制
脏区域已经计算好,并且在EGLsurface中设置了脏区域,那么下面就要绘制了
回到Canvas::draw()函数
2.1 创建 FrameBuilder
auto& caches = Caches::getInstance();
FrameBuilder frameBuilder(dirty, frame.width(), frame.height(), mLightGeometry, caches);
FrameBuilder::FrameBuilder(...) {
// Prepare to defer Fbo0
//生成一个默认的LayerBuilder, FB0
auto fbo0 = mAllocator.create(viewportWidth, viewportHeight, Rect(clip));
mLayerBuilders.push_back(fbo0);
mLayerStack.push_back(0);
mCanvasState.initializeSaveStack(viewportWidth, viewportHeight,
clip.fLeft, clip.fTop, clip.fRight, clip.fBottom,
lightGeometry.center);
}
在FrameBuilder构造函数中,会生成一幅默认的LayerBuilder, 也就是FB0, 由mLayerBuilders/mLayerStack指定。本例并没有其它的Layer, 所以后续的的操作都是在这个默认的LayerBuilder中进行的。
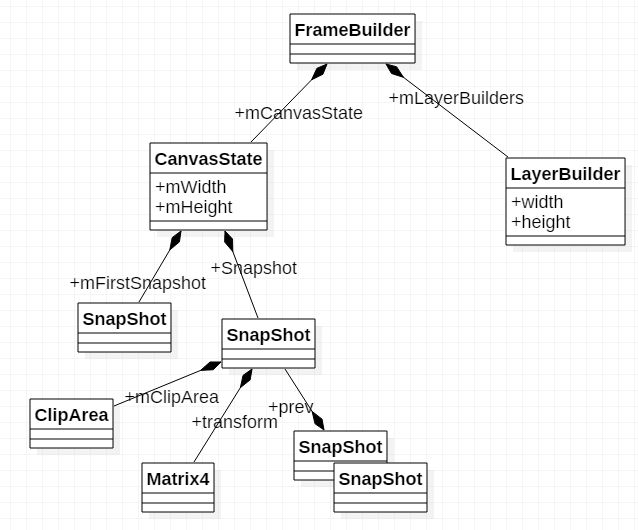
FrameBuilder 摘自 Android N中UI硬件渲染(hwui)的HWUI_NEW_OPS(基于Android 7.1)
FrameBuilder 管理某一帧的构建,用于处理,优化和存储从RenderNode和LayerUpdateQueue中来的渲染命令。
FrameBuilder主要工作是算出来最后的绘制状态(主要是裁剪, 透明度计算,以及矩阵计算), 并且对每个绘制命令合并、重新排序,以提高绘制效率。
同时它的replayBakedOps()方法还用于该帧的绘制命令重放。一帧中可能需要绘制多个层,每一层的上下文都会存在相应的LayerBuilder中。在FrameBuilder中通过mLayerBuilders和mLayerStack存储一个layer stack。它替代了原Snapshot类的一部分功能。LayerBuilder:
用于存储"绘制某一层"的操作和状态。对于所有View通用,即如果View有render layer,它对应一个FBO;如果对于普通View,它对应的是SurfaceFlinger提供的surface。 其中的mBatches存储了当前层defer后(即batch/merge好)的绘制操作。
创建好FrameBuilder后,调用frameBuilder.deferRenderNodeScene(mRenderNodes, mContentDrawBounds); 来延迟 RenderNode的处理? 奇怪,按理说,DisplayList 都准备好了,Dirty区域也已经计算出来了,为啥还不直接绘制,还要延迟处理呢?
2.2 deferRenderNodeScene
延迟处理主要是对绘制命令进行合并,这样有什么好处呢????
void FrameBuilder::deferRenderNodeScene(const std::vector< sp >& nodes,
const Rect& contentDrawBounds) {
if (nodes.size() == 1) {
if (!nodes[0]->nothingToDraw()) {
deferRenderNode(*nodes[0]);
}
return;
}
...
}
在本例中,只有一个RootRenderNode, 来看下notingToDraw的判断条件
bool nothingToDraw() const {
const Outline& outline = properties().getOutline();
return mDisplayList == nullptr
|| properties().getAlpha() <= 0
|| (outline.getShouldClip() && outline.isEmpty())
|| properties().getScaleX() == 0
|| properties().getScaleY() == 0;
}
noting to draw的判断条件
- 没有DisplayList -- 没有绘制命令还画啥呢
- 全透明的View -- 透明还画啥呢?
- View是可裁剪,且被裁剪区域为(0, 0, 0, 0) -- 意思是已经把View裁剪没啦
- 水平(scaleX)或垂直(scaleY)缩放为0时 -- 意思是view 缩放到无限小了,
deferRenderNode开始具体去推迟RenderNode draw了
void FrameBuilder::deferRenderNode(RenderNode& renderNode) {
renderNode.computeOrdering();
mCanvasState.save(SaveFlags::MatrixClip);
deferNodePropsAndOps(renderNode);
mCanvasState.restore();
}
computeOrdering 找到那些需要投影到它的Background上的子RenderNode, 这些RenderNode被称为Projected RenderNode. 参考老罗的Android应用程序UI硬件加速渲染的Display List构建过程分析一文, 但Projected RenderNode不在本文讲解范围。
CanvasState.save 在Android DisplayList 构建过程中有讲,就是生成一个新的快照来保存经过计算的RenderNode的相关属性到快照中
CanvasState.restore()与CanvasState.save相互对应
接着看deferNodePropsAndOps
void FrameBuilder::deferNodePropsAndOps(RenderNode& node) {
const RenderProperties& properties = node.properties();
const Outline& outline = properties.getOutline();
//如果View的left,top不在原点(0,0), 则将坐标平移到具体的(left, top)
if (properties.getLeft() != 0 || properties.getTop() != 0) {
mCanvasState.translate(properties.getLeft(), properties.getTop());
}
//对静态矩阵或Animation矩阵进行计算
if (properties.getStaticMatrix()) {
mCanvasState.concatMatrix(*properties.getStaticMatrix());
} else if (properties.getAnimationMatrix()) {
mCanvasState.concatMatrix(*properties.getAnimationMatrix());
}
//对View本身的转换矩阵进行计算
if (properties.hasTransformMatrix()) {
if (properties.isTransformTranslateOnly()) {
mCanvasState.translate(properties.getTranslationX(), properties.getTranslationY());
} else {
mCanvasState.concatMatrix(*properties.getTransformMatrix());
}
}
const int width = properties.getWidth();
const int height = properties.getHeight();
int clipFlags = properties.getClippingFlags();
//计算快照中的alpha值,这个和layer相关,略过
if (properties.getAlpha() < 1) {
...
}
//是否需要裁剪
if (clipFlags) {
Rect clipRect;
//拿到裁剪区域
properties.getClippingRectForFlags(clipFlags, &clipRect);
//开始裁剪,这个针对的快照中mClipArea, 它代表裁剪区域,也就是求两个区域的交集。
mCanvasState.clipRect(clipRect.left, clipRect.top, clipRect.right, clipRect.bottom,
SkRegion::kIntersect_Op);
}
//和RevealAnimator有关,outline 略过...
if (properties.getRevealClip().willClip()) {
Rect bounds;
properties.getRevealClip().getBounds(&bounds);
mCanvasState.setClippingRoundRect(mAllocator,
bounds, properties.getRevealClip().getRadius());
} else if (properties.getOutline().willClip()) {
mCanvasState.setClippingOutline(mAllocator, &(properties.getOutline()));
}
// 接下来会deferNodeOps, 但是考虑是否reject, 一般这里都为false
//1. 判断View的裁剪区域是否为空,不能把View裁剪为空的
//2. 设置了裁剪区域,但是最后裁剪出来的区域与原本View的大小都没有交集了,这种情况会reject,
bool quickRejected = mCanvasState.currentSnapshot()->getRenderTargetClip().isEmpty()
|| (properties.getClipToBounds()
&& mCanvasState.quickRejectConservative(0, 0, width, height));
if (!quickRejected) {
...
deferNodeOps(node);
...
}
}
下面看下deferNodeOps
#define OP_RECEIVER(Type) \
[](FrameBuilder& frameBuilder, const RecordedOp& op) {
frameBuilder.defer##Type(static_cast(op)); },
void FrameBuilder::deferNodeOps(const RenderNode& renderNode) {
typedef void (*OpDispatcher) (FrameBuilder& frameBuilder, const RecordedOp& op);
static OpDispatcher receivers[] = BUILD_DEFERRABLE_OP_LUT(OP_RECEIVER);
// can't be null, since DL=null node rejection happens before deferNodePropsAndOps
const DisplayList& displayList = *(renderNode.getDisplayList());
//chunks记录着ops的位置
for (auto& chunk : displayList.getChunks()) {
//计算子View Z轴的大小,并接顺序保存在 zTranslatedNodes中, 这里略过
FatVector zTranslatedNodes;
buildZSortedChildList(&zTranslatedNodes, displayList, chunk);
//略过,defer3dChildren只针对Z轴有效的情况
defer3dChildren(chunk.reorderClip, ChildrenSelectMode::Negative, zTranslatedNodes);
for (size_t opIndex = chunk.beginOpIndex; opIndex < chunk.endOpIndex; opIndex++) {
const RecordedOp* op = displayList.getOps()[opIndex];
//与所以的RecordedOp执行对应的defer动作
receivers[op->opId](*this, *op);
...
}
defer3dChildren(chunk.reorderClip, ChildrenSelectMode::Positive, zTranslatedNodes);
}
}
receivers是一组函数指针数组,它与RecordedOp子类相对应, deferXXXX, 如下所示
receivers[0] = (*deferRenderNodeOp)(FrameBuilder& frameBuilder, const RecordedOp& op)
receivers[1] = (*deferCirclePropsOp)(FrameBuilder& frameBuilder, const RecordedOp& op)
receivers[2] = (*deferRoundRectPropsOp)(FrameBuilder& frameBuilder, const RecordedOp& op)
...
receivers[21] = (*deferRectOp)(FrameBuilder& frameBuilder, const RecordedOp& op)
...
而RecordedOp分为两类,一类是RenderNodeOp, 一类是specific的RecordedOp也就是绘制命令, 针对这两种情况
2.2.1 RenderNodeOp
从名字大概可以猜测它的意思,也就是推迟下一个RenderNode, 这样就能递归遍历整个DisplayList Tree.
void FrameBuilder::deferRenderNodeOp(const RenderNodeOp& op) {
if (!op.skipInOrderDraw) {
deferRenderNodeOpImpl(op);
}
}
void FrameBuilder::deferRenderNodeOpImpl(const RenderNodeOp& op) {
if (op.renderNode->nothingToDraw()) return;
//生成一个新的快照用来保存新的RenderNode相关信息
int count = mCanvasState.save(SaveFlags::MatrixClip);
//进行相应的矩阵计算,
//注意,这里的op.localClip与op.localMatrix都是在canvas里进行操作的(如 canvas.translate ...),而非View的属性
// apply state from RecordedOp (clip first, since op's clip is transformed by current matrix)
mCanvasState.writableSnapshot()->applyClip(op.localClip,
*mCanvasState.currentSnapshot()->transform);
mCanvasState.concatMatrix(op.localMatrix);
// then apply state from node properties, and defer ops
deferNodePropsAndOps(*op.renderNode);
mCanvasState.restoreToCount(count);
}
从deferRenderNodeOpImpl主要工作之一就是应用canvas做的一些矩阵运算(translate/scale 裁剪), 另一个就是递归调用子RenderNode,这样就能遍历完所有的DisplayList相关的绘制命令,以及计算出canvas的矩阵。
2.2.2 具体的RecordedOp, 以deferRectOp为例
deferRectOp就是处理具体的绘制命令
void FrameBuilder::deferRectOp(const RectOp& op) {
deferStrokeableOp(op, tessBatchId(op));
}
BakedOpState* FrameBuilder::deferStrokeableOp(const RecordedOp& op, batchid_t batchId,
BakedOpState::StrokeBehavior strokeBehavior) {
// Note: here we account for stroke when baking the op
BakedOpState* bakedState = BakedOpState::tryStrokeableOpConstruct(
mAllocator, *mCanvasState.writableSnapshot(), op, strokeBehavior);
...
currentLayer().deferUnmergeableOp(mAllocator, bakedState, batchId);
return bakedState;
}
tessBatchId(op)通过Paint去获得batch id, 对于一般的绘制形状的命令如(RectOp,ArcOp,OvalOp,RoundRectOp)都是Vertics类型.
deferStrokeableOp会生成一个BakedOpState,然后通过deferUnmergeableOp将BakedOpState插入到Layer的对应的mBatches里面, 同时插入到mBatchLookup,一个查找表,里面的元素表示的是不可merge的ops.
在deferUnmergeableOp, 肯定也对应有deferMergeableOp. mMergingBatchLookup是一个可merge ops的查找表,
如图所示
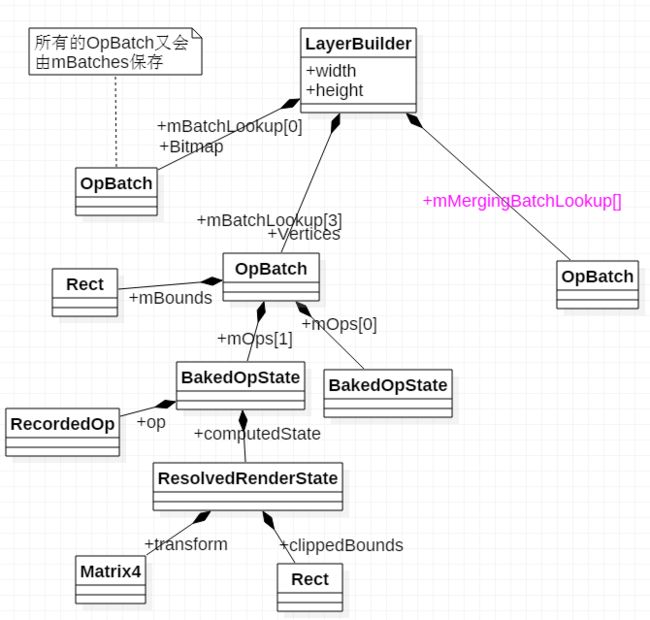
这样经过所有的2.2.1节对所有的RenderNode递归调用后,所有的Ops都已经插入到LayerBuilder中的mBatches里,并且将Mergeable的op插入到mMergingBatchLookup,将unMergeable的op插入到了mBatchLookup中了。
2.3 replayBakedOps
伴随着DisplayList信息全部已经保存到了LayerBuilder里了, 下一步就是将这些绘制命令真正的绘制出来,最终结果就是转换成openGL API接口,
在CanvasContext::draw()里,具体是通过 replayBakedOps 命令操作的。
BakedOpRenderer renderer(caches, mRenderThread.renderState(),
mOpaque, mLightInfo);
frameBuilder.replayBakedOps(renderer);
bool drew = renderer.didDraw();
template
void replayBakedOps(Renderer& renderer) {
// Replay through layers in reverse order, since layers
// later in the list will be drawn by earlier ones
for (int i = mLayerBuilders.size() - 1; i >= 1; i--) { //针对其它layer, 本例代码并没有其它layer,这里直接就略过
...
}
if (CC_LIKELY(mDrawFbo0)) { //默认的layer FB0
const LayerBuilder& fbo0 = *(mLayerBuilders[0]);
renderer.startFrame(fbo0.width, fbo0.height, fbo0.repaintRect);
fbo0.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
renderer.endFrame(fbo0.repaintRect);
}
...
}
startFrame通过调用 glViewPort来设置视见区位置, 并且通过glBindFramebuffer将要渲染的数据绑定到fb0中.
void LayerBuilder::replayBakedOpsImpl(void* arg,
BakedOpReceiver* unmergedReceivers, MergedOpReceiver* mergedReceivers) const {
for (const BatchBase* batch : mBatches) {
size_t size = batch->getOps().size();
if (size > 1 && batch->isMerging()) {
int opId = batch->getOps()[0]->op->opId;
const MergingOpBatch* mergingBatch = static_cast(batch);
MergedBakedOpList data = {
batch->getOps().data(),
size,
mergingBatch->getClipSideFlags(),
mergingBatch->getClipRect()
};
mergedReceivers[opId](arg, data);
} else {
for (const BakedOpState* op : batch->getOps()) {
unmergedReceivers[op->op->opId](arg, *op);
}
}
}
}
而replayBakedOpsImpl遍历LayerBuilder中的mBatches(记录了所有的绘制操作),然后分别针对Merged(如onMergedBitmapOps)或unmerged(如onRectOp)的op调用具体的函数将绘制命令封装成Glop,
然后通过BakedOpRenderer中的renderGlop将Glop转换成openGL函数. 这部分涉及 openGL相关命令,就不继续下去。
2.4 swapBuffer
2.3小节已经将绘制操作全部转换成openGl了, 最后就通过EglManager的eglSwapBuffersWithDamageKHR去swap back buffer和front buffer, 这样新的一帧数据就显示出来了
mEglManager.swapBuffers(frame, screenDirty)
eglSwapBuffersWithDamageKHR(mEglDisplay, frame.mSurface, rects, screenDirty.isEmpty() ? 0 : 1);
参考
EGL doc