摘要:本套自测题专为SVM及其应用而设计,目前超过550人注册了这个测试,最终得满分的人却很少,[doge],一起来看看你的SVM知识能得多少分吧,顺便还能查漏补缺哦。
Introduction
机器学习强大如一座军械库,里面有各种威力惊人的武器,不过你首先得学会如何使用。举个栗子,回归(Regression)是一把能够有效分析数据的利剑,但它对高度复杂的数据却束手无策。支持向量机(Support Vector Machines,SVM)就好比一把锋利的小刀,特别是在小数据集上建模显得更为强大有力。
本套测试题专为SVM及其应用而设计,目前超过550人注册了这个测试(排行榜),一起来看看你的SVM知识能得多少分吧,顺便还能查漏补缺。
Helpful Resources
1.十大常用机器学习算法(附Python和R代码)
2.SVM原理及代码
Skill test Questions and Answers
假定你用一个线性SVM分类器求解二类分类问题,如下图所示,这些用红色圆圈起来的点表示支持向量,据此回答问题1和2:
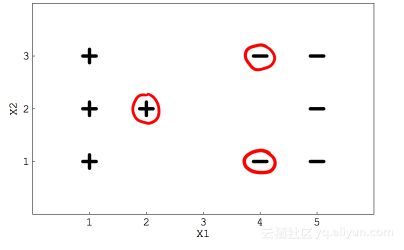
1.如果移除这些圈起来的数据,决策边界(即分离超平面)是否会发生改变?
A.Yes B. No
答案:A
Tips: 如果改变这三个点中任意一个点的位置就会引入松弛约束条件,决策边界就会发生变化。
2. 如果将数据中除圈起来的三个点以外的其他数据全部移除,那么决策边界是否会改变?
A.True B. False
答案:B
Tips: 决策边界只会被支持向量影响,跟其他点无关。
3.关于SVM泛化误差描述正确的是
A.超平面与支持向量之间距离
B.SVM对未知数据的预测能力
C.SVM的误差阈值
答案:B
Tips: 统计学中的泛化误差是指对模型对未知数据的预测能力。
4. 如果惩罚参数C趋于无穷,下面哪项描述是正确的?
A.若最优分离超平面存在,必然能够将数据完全分离
B.软间隔分类器能够完成数据分类
C.以上都不对
答案:A
Tips: 如果误分类惩罚很高,软间隔不会一直存在,因为没有更多的误差空间
5. 以下关于硬间隔描述正确的是
A.SVM允许分类存在微小误差
B.SVM允许分类是有大量误差
C.以上均不正确
答案:A
Tips: 硬间隔意味着SVM在分类时很严格,在训练集上表现尽可能好,有可能会造成过拟合。
6. 训练SVM的最小时间复杂度为O(n2),那么一下哪种数据集不适合用SVM?
A.大数据集 B. 小数据集 C. 中等大小数据集 D. 和数据集大小无关
答案:A
有明确分类边界的数据集最适合SVM
7. SVM的效率依赖于:
A.核函数的选择 B. 核参数 C. 软间隔参数C D. 以上所有
答案:D
Tips: SVM的效率依赖于以上三个基本要求,它能够提高效率,降低误差和过拟合
8. 支持向量是那些最接近决策平面的数据点。
A.TRUE B. FALSE
答案:A
9. SVM在下列那种情况下表现糟糕:
A.线性可分数据 B. 清洗过的数据 C. 含噪声数据与重叠数据点
答案:C
Tips: 当数据中含有噪声数据与重叠的点时,要画出干净利落且无误分类的超平面很难
10. 假定你使用了一个很大γ值的RBF核,这意味着:
A. 模型将考虑使用远离超平面的点建模
B.模型仅使用接近超平面的点来建模
C.模型不会被点到超平面的距离所影响
D.以上都不正确
答案:B
Tips: SVM调参中的γ衡量距离超平面远近的点的影响。对于较小的γ,模型受到严格约束,会考虑训练集中的所有点,而没有真正获取到数据的模式、对于较大的γ,模型能很好地学习到模型。
11.SVM中的代价参数表示:
A.交叉验证的次数
B.使用的核
C.误分类与模型复杂性之间的平衡
D.以上均不是
答案:C
Tips:代价参数决定着SVM能够在多大程度上适配训练数据。如果你想要一个平稳的决策平面,代价会比较低;如果你要将更多的数据正确分类,代价会比较高。可以简单的理解为误分类的代价。
假定你使用SVM学习数据X,数据X里面有些点存在错误。现在如果你使用一个二次核函数,多项式阶数为2,使用松弛变量C作为超参之一,请回答12-13。
12.当你使用较大的C(C趋于无穷),则:
A.仍然能正确分类数据
B.不能正确分类
C.不确定
D.以上均不正确
答案:A
Tips: 采用更大的C,误分类点的惩罚就更大,因此决策边界将尽可能完美地分类数据。
13.如果使用较小的C(C趋于0),则:
A.误分类
B.正确分类
C.不确定
D.以上均不正确
答案:A
Tips:分类器会最大化大多数点之间的间隔,少数点会误分类,因为惩罚太小了。
14.如果我使用数据集的全部特征并且能够达到100%的准确率,但在测试集上仅能达到70%左右,这说明:
A.欠拟合 B.模型很棒 C.过拟合
答案:C
Tips:如果在训练集上模型很轻易就能达到100%准确率,就要检查是否发生过拟合。
15.下面哪个属于SVM应用
A.文本和超文本分类
B.图像分类
C.新文章聚类
D.以上均是
答案:D
Tips: SVM广泛应用于实际问题中,包括回归,聚类,手写数字识别等。
假设你训练SVM后,得到一个线性决策边界,你认为该模型欠拟合。据此回答16-18题:
16.在下次迭代训练模型时,应该考虑:
A.增加训练数据
B.减少训练数据
C.计算更多变量
D.减少特征
答案:C
Tips:由于是欠拟合,最好的选择是创造更多特征带入模型训练。
17.假设你在上一题做出了正确的选择,那么以下哪一项会发生:
1.降低偏差
2.降低方差
3.增加偏差
4.降低方差
A.1和2
B.2和3
C.1和4
D.2和4
答案:C
Tips:更好的模型会降低偏差并提高方差
18.假如你想修改SVM的参数,同样达到模型不会欠拟合的效果,应该怎么做?
A.增大参数C
B.减小参数C
C.改变C并不起作用
D.以上均不正确
答案:A
Tips:增大参数C会得到正则化模型
19.SVM中使用高斯核函数之前通常会进行特征归一化,以下关于特征归一化描述正确的是?
1.经过特征正则化得到的新特征优于旧特征
2.特征归一化无法处理类别变量
3.SVM中使用高斯核函数时,特征归一化总是有用的
A.1 B. 1 and 2 C. 1 and 3 D. 2 and 3
答案:B
假定你使用SVM来处理4类分类问题,你使用了one-vs-all策略,据此回答20-22
20.此种情况下要训练SVM模型多少次?
A.1
B.2
C. 3
D. 4
答案:D
Tips:使用one-vs-all策略就要训练4次 ,每次把一个类当成正类,其他的类当作负类,然后学习出4个模型,对新数据取函数值最大的那个类作为预测类别
21. 假定用one-vs-all训练一次SVM要10秒,那么总共应该训练多少秒?
A.20
B.40
C.60
D.80
答案:B
Tips:每个训练10秒,要训练4次,那就是40秒
22. 假设现在只有两个类,这种情况下SVM需要训练几次?
A.1
B.2
C.3
D.4
答案:A
Tips:两个类训练1次就可以了
假设你训练了一个基于线性核的SVM,多项式阶数为2,在训练集和测试集上准确率都为100%,据此回答23-24
23. 如果增加模型复杂度或核函数的多项式阶数,将会发生什么?
A.导致过拟合
B.导致欠拟合
C.无影响,因为模型已达100%准确率
D.以上均不正确
答案:A
Tips:增加模型复杂度会导致过拟合
24. 如果增加模型复杂度之后,你发现训练集上准确率还是100%,可能是什么原因造成的?
1.数据不变,适配更多的多项式项或参数,算法开始记忆数据中的一切
2.数据不变,SVM不必在更大的假设空间中搜索分类超平面
A.1
B.2
C.1 and 2
D.以上均不正确
答案:C
25.以下关于SVM核函数说法正确的是
1. 核函数将低维数据映射到高维空间
2. 是一个相似度函数(similarity function)
A.1
B.2
C.1 and 2
D.以上均不正确
答案:C
Overall Distribution
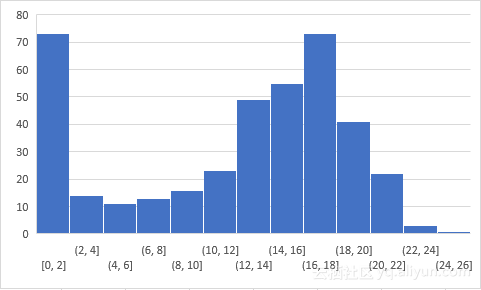
至今超过350人参与了这项测试,得分分布情况如下:
作者博客还有其他如降维、机器学习、SQL的自测题,感兴趣的可以去作者博客看看。
作者信息

Ankit Gupta,Ankit是一名自由数据科学家,解决了很多领域的复杂数据挖掘问题,热衷于学习更多数据科学和机器学习的知识。
GitHub:https://github.com/anki1909
LinkedIn:https://www.linkedin.com/in/ankit-gupta-84b737ba?trk=nav_responsive_tab_profile
本文由阿里云云栖社区组织翻译。
文章原标题《25 Questions to test a Data Scientist on Support Vector Machines》,作者: Robert Chang,译者:李烽,审阅: