1. 词法分析器与语法分析器
1.1 javac词法、语法分析器概览及Intellij IDEA调试跟踪流程
-
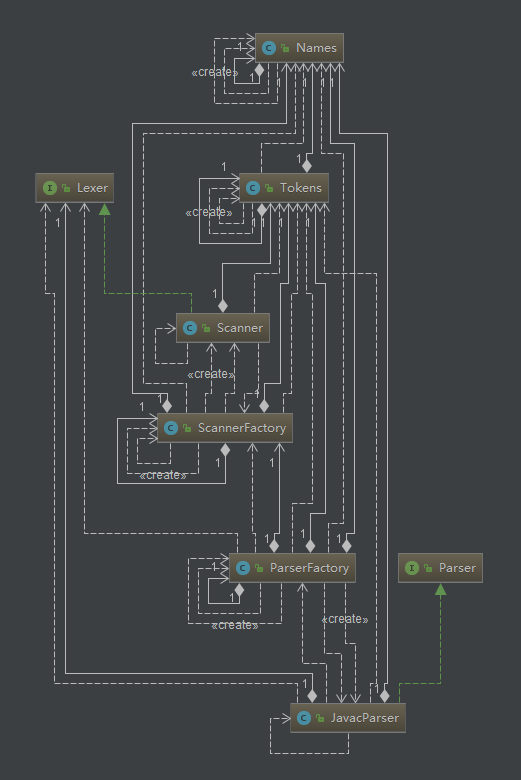
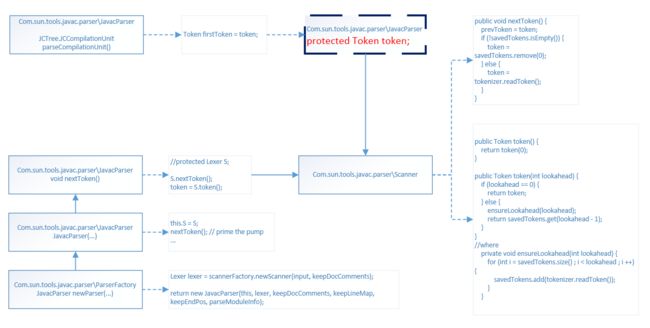
词法分析器实例的生成流程
1.2 词法分析器——核心流程是readToken()
- 词法分析器的接口类是com.sun.tools.javac.parser.Lexer;
实现类是com.sun.tools.javac.parser.Scanner。 -
字符流存放在JavaTokenizer类的成员protected UnicodeReader reader;里面,在该类的方法public Token readToken()里面将字符流组装成Token,在这里会将收集到的新名字加入到Names字符表里面。
 Scanner类token的获取
Scanner类token的获取 - readToken()返回Token类别
switch (tk.tag) {
case DEFAULT: return new Token(tk, pos, endPos, comments);
case NAMED: return new NamedToken(tk, pos, endPos, name, comments);
case STRING: return new StringToken(tk, pos, endPos, reader.chars(), comments);
case NUMERIC: return new NumericToken(tk, pos, endPos, reader.chars(), radix, comments);
default: throw new AssertionError();
}
问题.Javac如何划分Token,如何知道哪些字符组合成一个Token?(词法器)
-
Java代码有package、import、类定义、field定义、method定义、变量定义、表达式定义等语法规则。
这些规则除了一些Java语法规定的关键词,就是用户自定义的变量名称。
自定义的名称包括包名、类名、变量名、方法名。
关键词和自定义名称之间用空格隔开,每个语法表达式用分号结束。
如何判断哪些字符组合是一个Token的规则是在Scanner的nextToken方法中定义的,每次都会构造一个Token。
-
PaserFactory构建Names Tokens等
枚举类的关键方法
1)静态values方法返回一个包含全部枚举值的数组
2)ordinal方法返回enum声明中枚举常量的位置,位置从0开始计数
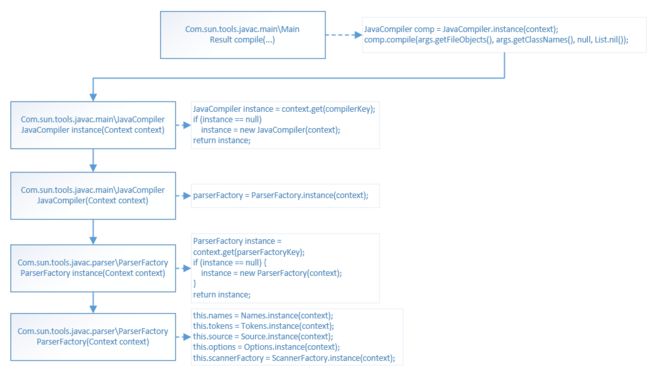
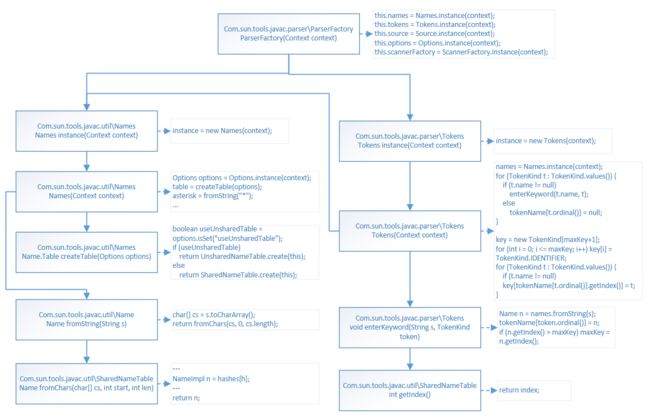 构建Names Tokens的流程
构建Names Tokens的流程 -
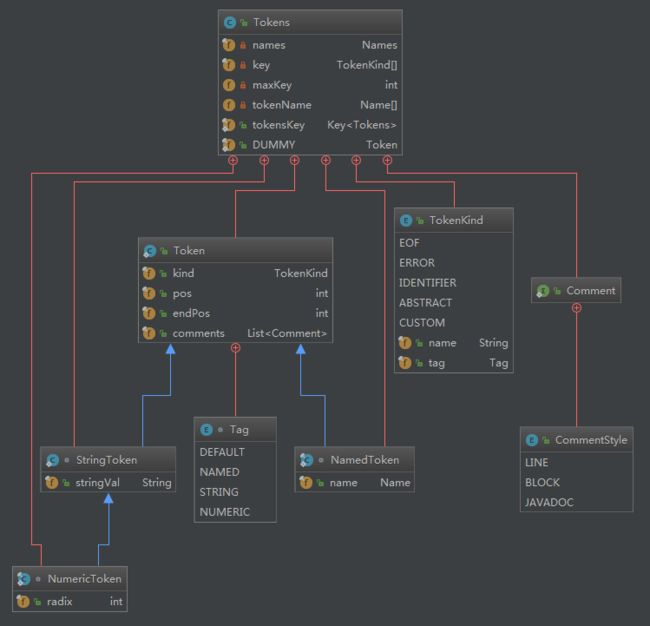
关于Tokens
为了显示方便,下图中对TokenKind枚举类的枚举值个数定义进行了删减
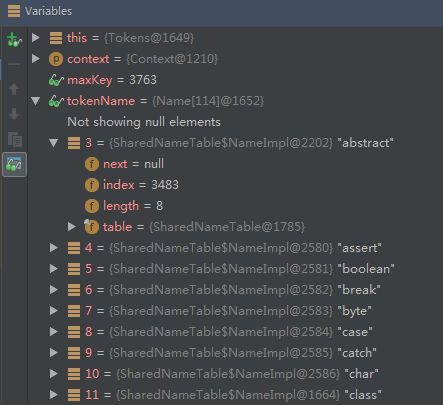
1)Tokens.tokenName存储的是“关键字在TokenKind里面的位置(token.ordinal())”与“关键字Name”的关系,该数组映射这两对关系。
2)Tokens.key存储的是“关键字Name在Names存储的位置index”与“关键字TokenKind本身”的关系,该数组映射这两对关系。
3)Tokens.maxKey在初始化更新完所有关键字后就固定下来,所以非关键字的index都大于maxKey
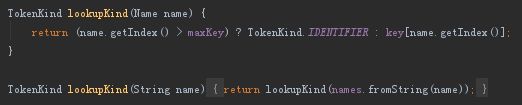
-
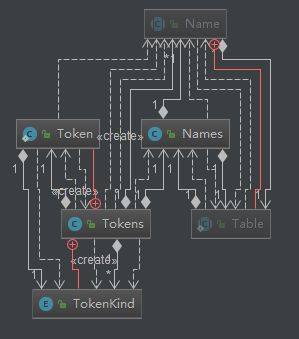
关于Name Table Names
分析后可知:Names是每个区域的名字表。
1)该表是利用哈希表+链表方式存储名字
2)该表先存储固定的名字(java.lang等),然后存储定义的关键字
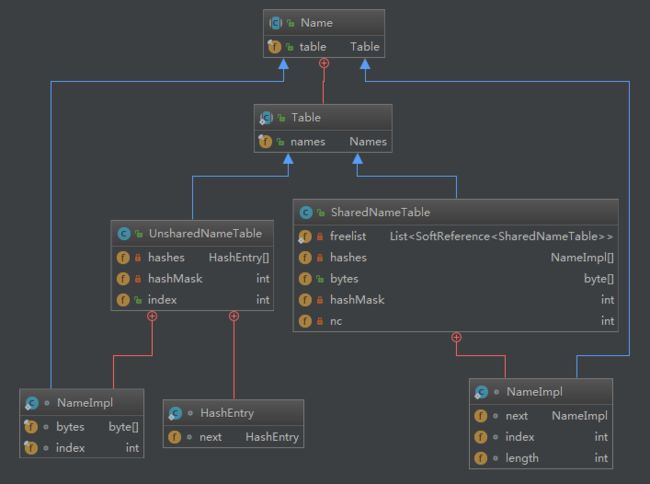
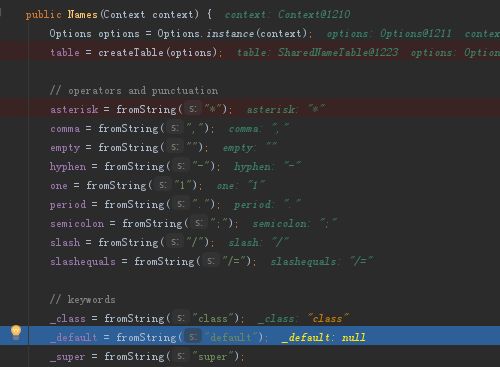
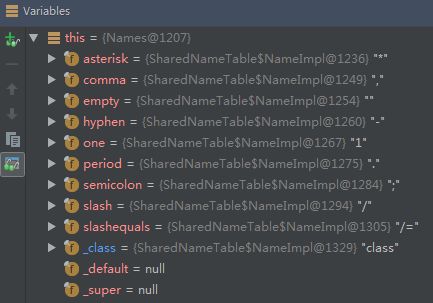
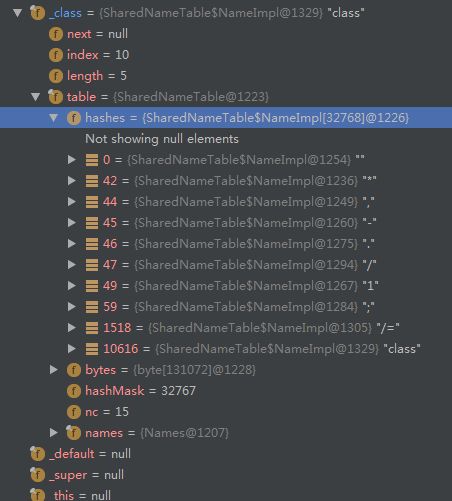
Names详细构造如下图所示,将cs代表的string类型经过hash后,放入到哈希表NameImpl[] hashes中,相同的hash值使用链表的方式存放,并且cs本身放在bytes里面。
1.2.1 词法单元的分类
-
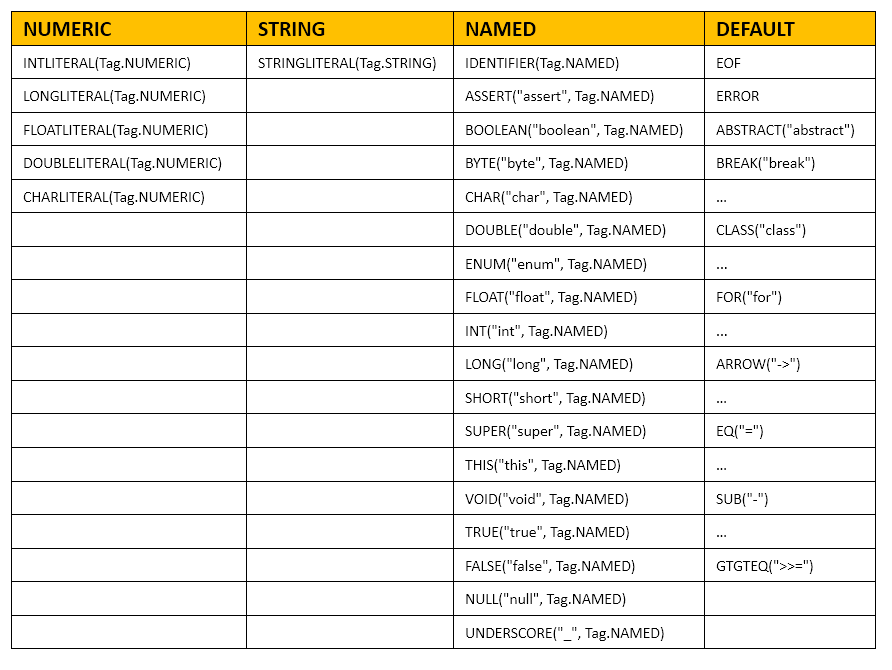
枚举体TokenKind(String name, Tag tag)词法单元分为四类。
1)NUMERIC是数字字面值
2)STRING是字符串字面值
3)NAMED主要是基本类型,包括标识符IDENTIFIER
4)DEFAULT最多,包括各种属性修饰符、运算符号、关键字等等
enum Tag {
DEFAULT,
NAMED,
STRING,
NUMERIC
}
- readToken()生成Token,并根据Java语法规则对Token完成分类
switch (tk.tag) {
case DEFAULT: return new Token(tk, pos, endPos, comments);
case NAMED: return new NamedToken(tk, pos, endPos, name, comments);
case STRING: return new StringToken(tk, pos, endPos, reader.chars(), comments);
case NUMERIC: return new NumericToken(tk, pos, endPos, reader.chars(), radix, comments);
default: throw new AssertionError();
}
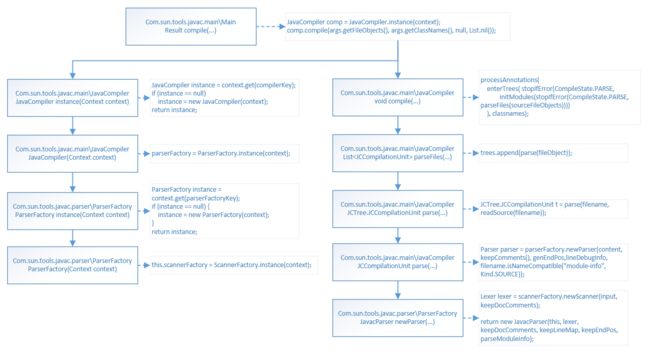
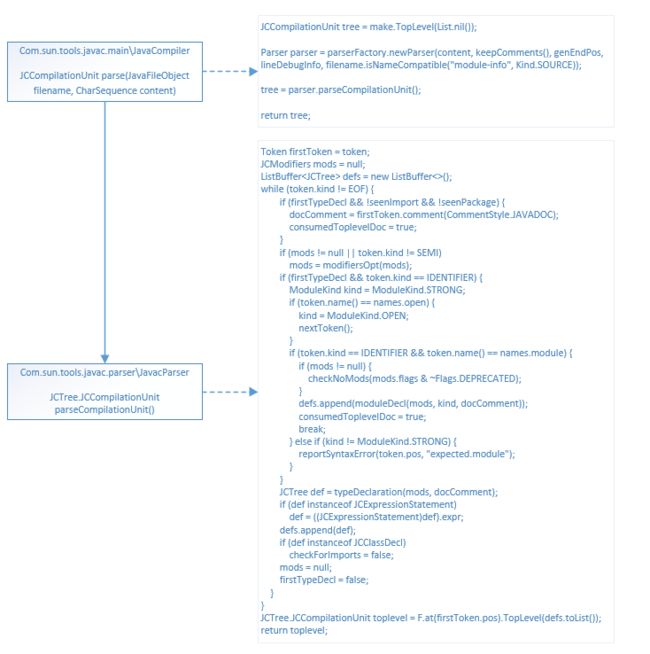
1.3 语法分析器——核心流程是parseCompilationUnit
- 核心类是JavacParser
Parser parser = parserFactory.newParser(content, keepComments(), genEndPos,
lineDebugInfo, filename.isNameCompatible("module-info", Kind.SOURCE));
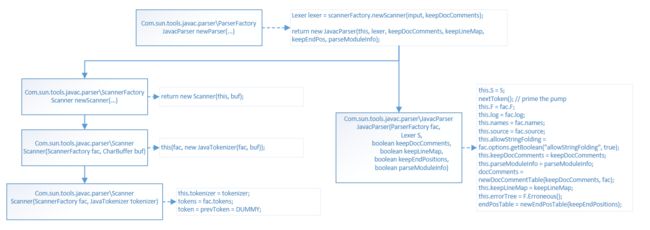
public JavacParser newParser(CharSequence input, boolean keepDocComments, boolean keepEndPos, boolean keepLineMap, boolean parseModuleInfo) {
Lexer lexer = scannerFactory.newScanner(input, keepDocComments);
return new JavacParser(this, lexer, keepDocComments, keepLineMap, keepEndPos, parseModuleInfo);
}
-
parseCompilationUnit流程
1)按照Java语法规范依次找出package、import、类定义、属性和方法定义等,最后构建一个抽象语法树
2)这里核心流程不是按照token为单位,而是按照Java语法单元为单位进行了方法封装,一个函数处理一个语法单元。如JCTree def = typeDeclaration(mods, docComment);就会处理整个类的tokens。
 词法分析核心流程parseCompilationUnit
词法分析核心流程parseCompilationUnit
问题.Javac如何分辨Token的类别?(语法器)
- Javac进行词法分析时,JavacParser对象会根据Java语言规范来控制什么顺序、什么地方应该出现什么Token。就是前面说的,parseCompilationUnit()里面是按照Java语言单元进行解析,例如typeDeclaration()里面会对类型定义的所有token都读取出来,并最终构成一棵子语法树。
- 总之,Token流的顺序要符合Java语言规范,JavacParser里面已经根据规范编写了各个处理Token的方法。
语法树的结构?
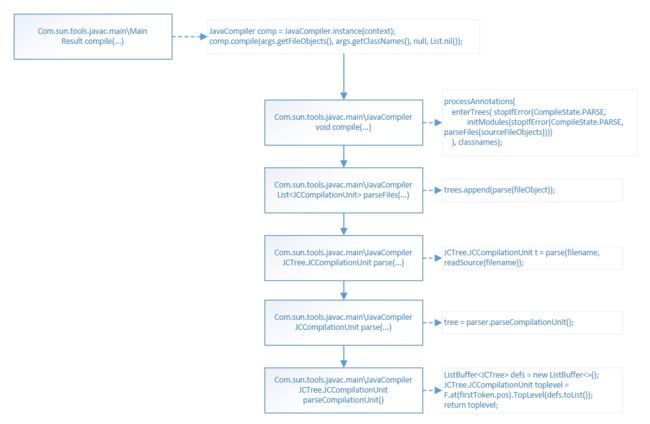
-
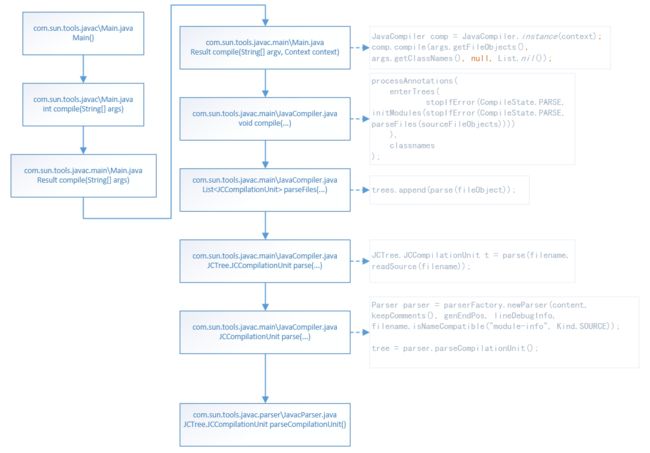
1)parseFiles()对javac需要编译的所有文件进行编译,每个文件生成一个JCTree.JCCompilationUnit,所有文件形成List
2)parseFiles()最终调用parseCompilationUnit()处理每个文件,每个文件生成一个JCTree.JCCompilationUnit。在文件中,对每个定义构造一个语法树JCTree,然后所有定义加入到ListBufferdefs,然后转换成List 加入到JCTree.JCCompilationUnit toplevel中。这些定义包括package/import/class定义等等。
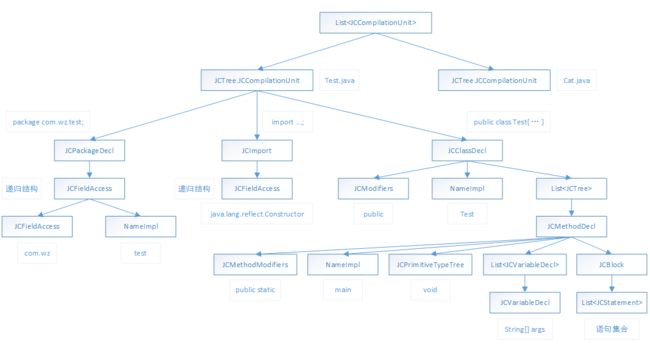
1.3.1 语法树生成示例
- Test.java
package com.wz.test;
import java.lang.reflect.Constructor;
public class Test {
public static void main(String[] args) {
String ClassName = "com.wz.test.Cat";
Class cl = null;
try {
cl = Class.forName(ClassName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
}
Constructor[] constructors= cl.getDeclaredConstructors();
for (Constructor constructor : constructors) {
String name = constructor.getName();
System.out.println("Constructor: " + name);
}
Cat cat = new Cat("Tiger");
System.out.println(cat.name);
}
}
- Cat.java
package com.wz.test;
public class Cat {
String name;
public Cat(String name) {
this.name = name;
}
}
-
生成的语法树结构
1.3.2 语法树生成过程涉及到的步骤示例——Test.java为例
1)JCPackageDecl生成(解析package com.wz.test;)
- parseCompilationUnit中的第一个token是package,nextToken()之后就变为了com
- 进入qualident,ident()之后,token变为"."
Ident(ident())以com返回的name建立一个语法树结点:JCIdent tree = new JCIdent(name, null);
while循环里面循环处理".xxx"模式,第一个处理的是".wz"。并建立语法树结点JCFieldAccess,其中JCExpression this.selected = 上面刚建立的结点,Name this.name = wz返回的name。 - qualident之后是accept(SEMI),期望下个token是";",如果是的话,则获取下一个token,否则报错。
- 后面将JCExpression pid加入到新建立的JCPackageDecl pd结点中
- 最后加入到ListBuffer
defs = new ListBuffer<>();也即根链表中
if (token.kind == PACKAGE) {
int packagePos = token.pos;
List annotations = List.nil();
seenPackage = true;
if (mods != null) {
checkNoMods(mods.flags);
annotations = mods.annotations;
mods = null;
}
nextToken();
JCExpression pid = qualident(false);
accept(SEMI);
JCPackageDecl pd = toP(F.at(packagePos).PackageDecl(annotations, pid));
attach(pd, firstToken.comment(CommentStyle.JAVADOC));
consumedToplevelDoc = true;
defs.append(pd);
}
public JCExpression qualident(boolean allowAnnos) {
JCExpression t = toP(F.at(token.pos).Ident(ident()));
while (token.kind == DOT) {
int pos = token.pos;
nextToken();
List tyannos = null;
if (allowAnnos) {
tyannos = typeAnnotationsOpt();
}
t = toP(F.at(pos).Select(t, ident()));
if (tyannos != null && tyannos.nonEmpty()) {
t = toP(F.at(tyannos.head.pos).AnnotatedType(tyannos, t));
}
}
return t;
}
2)JCImport生成(处理import java.lang.reflect.Constructor;)
- 处理import的代码在循环while (token.kind != EOF) 里面
- "import java.lang.reflect.Constructor;"处理跟"package com.wz.test;"是一样的,有两处不同:
第一,import中可能会有static修饰符,所以JCImport语法树结点有一个staticImport属性来记录;
第二,import中可能会有"*"。
if (checkForImports && mods == null && token.kind == IMPORT) {
seenImport = true;
defs.append(importDeclaration());
}
protected JCTree importDeclaration() {
int pos = token.pos;
nextToken();
boolean importStatic = false;
if (token.kind == STATIC) {
importStatic = true;
nextToken();
}
JCExpression pid = toP(F.at(token.pos).Ident(ident()));
do {
int pos1 = token.pos;
accept(DOT);
if (token.kind == STAR) {
pid = to(F.at(pos1).Select(pid, names.asterisk));
nextToken();
break;
} else {
pid = toP(F.at(pos1).Select(pid, ident()));
}
} while (token.kind == DOT);
accept(SEMI);
return toP(F.at(pos).Import(pid, importStatic));
}
3)JCClassDecl生成
public class Test {
public static void main(String[] args) {
String ClassName = "com.wz.test.Cat";
Class cl = null;
try {
cl = Class.forName(ClassName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
}
Constructor[] constructors= cl.getDeclaredConstructors();
for (Constructor constructor : constructors) {
String name = constructor.getName();
System.out.println("Constructor: " + name);
}
Cat cat = new Cat("Tiger");
System.out.println(cat.name);
}
}
- 首先处理修饰符,返回的是JCModifiers mods
if (mods != null || token.kind != SEMI)
mods = modifiersOpt(mods);
- 处理类型声明
JCTree def = typeDeclaration(mods, docComment);
继续调用return classOrInterfaceOrEnumDeclaration(modifiersOpt(mods), docComment);
继续调用
if (token.kind == CLASS) {
return classDeclaration(mods, dc);
}
protected JCClassDecl classDeclaration(JCModifiers mods, Comment dc) {
int pos = token.pos;
accept(CLASS);
Name name = typeName();
List typarams = typeParametersOpt();
JCExpression extending = null;
if (token.kind == EXTENDS) {
nextToken();
extending = parseType();
}
List implementing = List.nil();
if (token.kind == IMPLEMENTS) {
nextToken();
implementing = typeList();
}
List defs = classOrInterfaceBody(name, false);
JCClassDecl result = toP(F.at(pos).ClassDef(
mods, name, typarams, extending, implementing, defs));
attach(result, dc);
return result;
}
1.3.3 语法器与词法器的配合——public class Test
- Test是类类型,属于NamedToken,NamedToken继承Token并且含有域Name name。
每个Name都有指向符号表Names的指针,并有自身字符串的位置index。相当于每个Name代表一个名字字符串。
因此,NamedToken将TokenKind和Name联系起来了。
Name typeName() {
int pos = token.pos;
Name name = ident();
if (name == names.var) {
if (Feature.LOCAL_VARIABLE_TYPE_INFERENCE.allowedInSource(source)) {
reportSyntaxError(pos, "var.not.allowed", name);
} else {
warning(pos, "var.not.allowed");
}
}
return name;
}
public Name ident() {
return ident(false);
}
protected Name ident(boolean advanceOnErrors) {
if (token.kind == IDENTIFIER) {
Name name = token.name();
nextToken();
return name;
}
...
}
1.3.4 TreeMaker类
-
所有语法结点的生成都是在TreeMaker类中完成的,TreeMaker实现了在JCTree.Factory接口中定义的所有结点的构成方法。
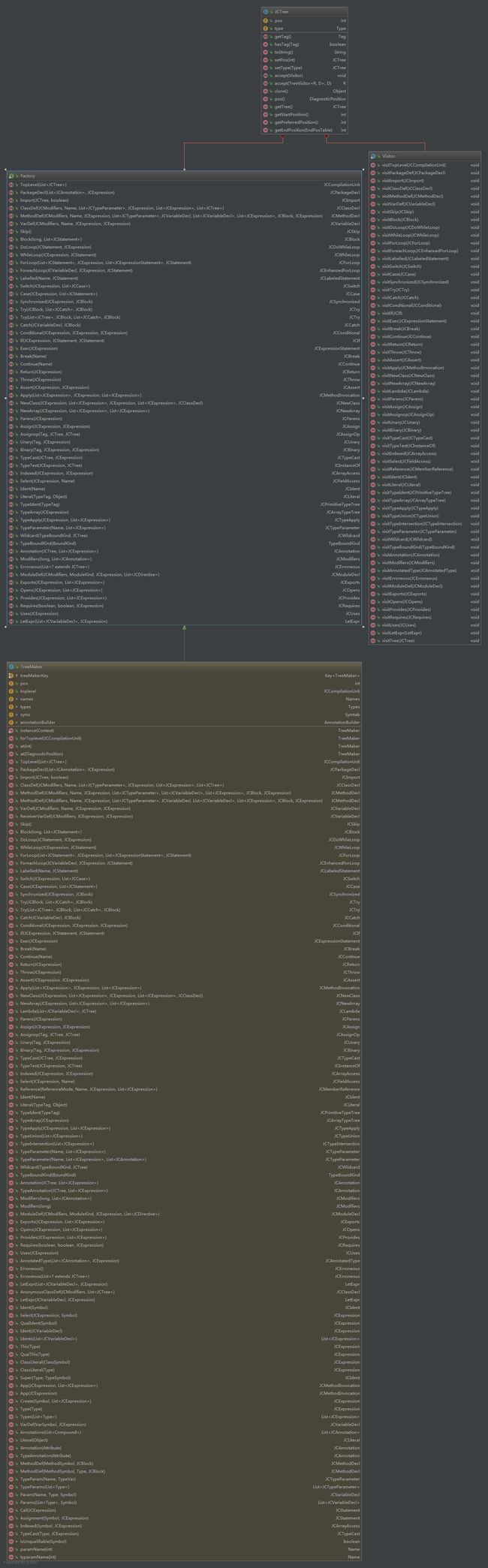
分析代码"JCPackageDecl pd = toP(F.at(packagePos).PackageDecl(annotations, pid));"
- step1.F.at(packagePos)
F是JavacParser的域变量。
/** The factory to be used for abstract syntax tree construction.
*/
protected TreeMaker F;
public TreeMaker at(int pos) {
this.pos = pos;
return this;
}
- step2.TreeMaker.java——PackageDecl(annotations, pid)
public JCPackageDecl PackageDecl(List annotations,
JCExpression pid) {
Assert.checkNonNull(annotations);
Assert.checkNonNull(pid);
JCPackageDecl tree = new JCPackageDecl(annotations, pid);
tree.pos = pos;
return tree;
}
- step3.toP()
endPosTable是JavacParser的域变量。
/** End position mappings container */
protected final AbstractEndPosTable endPosTable;
protected T toP(T t) {
return endPosTable.toP(t);
}
//EmptyEndPosTable是JavacParser的内部类
protected static class EmptyEndPosTable extends AbstractEndPosTable {
protected T toP(T t) {
return t;
}
}