Demo 地址已更新
https://github.com/Danny1451/MetalLutFilter
Metal 性能优化点
终于写到第三期了,这一期主要内容在于如何优化 Metal 的渲染性能,这部分内容在研究的时候几乎没有任何可查阅的中文资料。
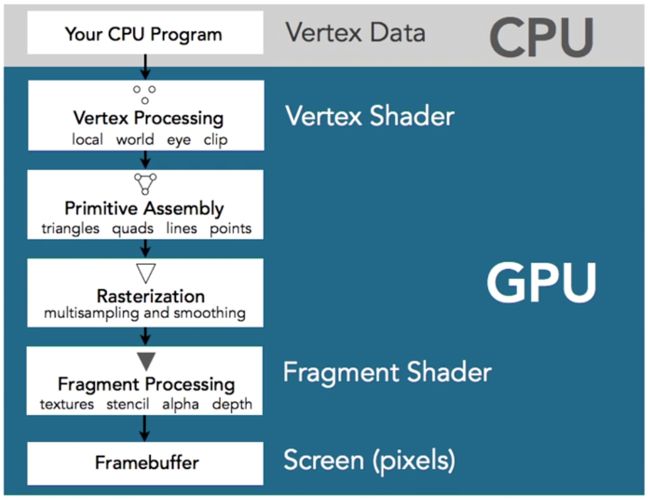
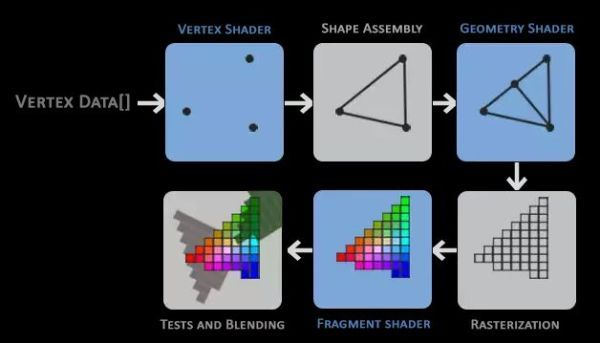
渲染的一般流程
在 GPU 中的工作流程就是把顶点数据传入顶点着色器,opengl / metal 会装配成图元,变成3D物体,就像第一张图那样中的场景,近截面和远截面中间这个部分就叫做视口,显示的图形就是这部分中的物体,超出的物体会被忽略掉,然后经过投影,归一化等操作(矩阵变换)将图形显示到屏幕上,经过投影变换,然后经过光栅化转变成像素图形,再经过片段着色器给像素染色,最后的测试会决定你同一个位置的物体到底哪一个可以显示在屏幕上以及颜色的混合。
简单就是如下:
执行顶点着色器 —— 组装图元 —— 光栅化图元 —— 执行片段着色器 —— 写入帧缓冲区 —— 显示到屏幕上。
CPU 配置顶点信息 -> GPU 绘制顶点 -> 组装成图元 三角 四边形 线 点 -> 光栅化到像素 -> 片段着色器 纹理 模板 透明度 深度 -> 绘制到屏幕
对象空间 - 世界空间 - 摄像头空间 - 裁剪空间 - 归一化坐标系空间 - 屏幕空间
场景快速搭建
这边以一个获取摄像头画面并实时添加滤镜的例子来介绍在使用 Metal 时,来介绍一些值得注意和可以优化的地方。
这篇文章着重在优化的内容,所以在关于获取图像和添加滤镜方面不会做过多的介绍,下面就简单的过一下。
-
通过 AVFoundation 得到摄像头的内容。
初始化 AVSession ,实现 AVCaptureVideoDataOutputSampleBufferDelegate 的代理,
在-(void)captureOutput:(AVCaptureOutput *)captureOutput didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection中可以获得 SampleBuffer ,通过下面转换能够转换到 MTLTexture 。注意 :这里的 SampleBuffer 一定要及时释放,不然会导致画面只有十几帧!
-(void)captureOutput:(AVCaptureOutput *)captureOutput didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection{ @autoreleasepool { CFRetain(sampleBuffer); connection.videoOrientation = [self avOrientationForDeviceOrientation:[UIDevice currentDevice].orientation]; CVMetalTextureCacheRef cameraRef = _cache; CVImageBufferRef ref = CMSampleBufferGetImageBuffer(sampleBuffer); CFRetain(ref); CVMetalTextureRef textureRef; NSInteger textureWidth = CVPixelBufferGetWidthOfPlane(ref, 0); NSInteger textureHeigth = CVPixelBufferGetHeightOfPlane(ref, 0); // cost to much time CVMetalTextureCacheCreateTextureFromImage(kCFAllocatorDefault, cameraRef, ref, NULL, MTLPixelFormatBGRA8Unorm, textureWidth, textureHeigth, 0, &textureRef); idmetalTexture = CVMetalTextureGetTexture(textureRef); [self.delegate didVideoProvide:self withLoadTexture:metalTexture]; //释放对应对象 CFRelease(ref); CFRelease(sampleBuffer); CFRelease(textureRef); } } 将得到的 Texture 在通过代理,或者 block 通知给我们的界面。
-
将上一章的滤镜相关代码封装成一个 MPSUnaryImageKernel 对象。
MPSUnaryImageKernel 是由 MetalPerformanceShaders 提供的基础滤镜接口。代表着输入源只有一个图像,对图像进行处理。同样的还有 MPSBinaryImageKernel 代表着两个输入源。 MPS 默认提供了很多图像滤镜,如 MPSImageGaussianBlur,MPSImageHistogram 等等。
MPSUnaryImageKernel 提供如下两个接口,分别代表替代原先 texture 和输出到新 texture 的方法:
- encodeToCommandBuffer:inPlaceTexture:fallbackCopyAllocator:
- encodeToCommandBuffer:sourceTexture:destinationTexture:
这边新建一个 MPSImageLut 类继承 MPSUnaryImageKernel,同时实现上面的两个接口:
具体的实现参照上一篇文章中的 lut 实现- (void)encodeToCommandBuffer:(id)commandBuffer sourceTexture:(id )sourceTexture destinationTexture:(id )destinationTexture{ ImageSaturationParameters params; params.clipOriginX = floor(self.filiterRect.origin.x); params.clipOriginY = floor(self.filiterRect.origin.y); params.clipSizeX = floor(self.filiterRect.size.width); params.clipSizeY = floor(self.filiterRect.size.height); params.saturation = self.saturation; params.changeColor = self.needColorTrans; params.changeCoord = self.needCoordTrans; id encoder = [commandBuffer computeCommandEncoder]; [encoder pushDebugGroup:@"filter"]; [encoder setLabel:@"filiter encoder"]; [encoder setComputePipelineState:self.computeState]; [encoder setTexture:sourceTexture atIndex:0]; [encoder setTexture:destinationTexture atIndex:1]; if (self.lutTexture == nil) { NSLog(@"lut == nil"); [encoder setTexture:sourceTexture atIndex:2]; }else{ [encoder setTexture:self.lutTexture atIndex:2]; } [encoder setSamplerState:self.samplerState atIndex:0]; [encoder setBytes:¶ms length:sizeof(params) atIndex:0]; NSUInteger wid = self.computeState.threadExecutionWidth; NSUInteger hei = self.computeState.maxTotalThreadsPerThreadgroup / wid; MTLSize threadsPerGrid = {(sourceTexture.width + wid - 1) / wid,(sourceTexture.height + hei - 1) / hei,1}; MTLSize threadsPerGroup = {wid, hei, 1}; [encoder dispatchThreadgroups:threadsPerGrid threadsPerThreadgroup:threadsPerGroup]; [encoder popDebugGroup]; [encoder endEncoding]; } // 替换原先 texture - (BOOL)encodeToCommandBuffer:(id )commandBuffer inPlaceTexture:(__strong id _Nonnull *)texture fallbackCopyAllocator:(MPSCopyAllocator)copyAllocator{ if (copyAllocator == nil) { return false; } id source = *texture; id targetTexture = copyAllocator(self,commandBuffer,source); [self encodeToCommandBuffer:commandBuffer sourceTexture:source destinationTexture:targetTexture]; *texture = targetTexture; return YES; } 根据手指触摸屏幕的位置,给 Texture 添加合适位置的滤镜,得到新的 Texture 。
将新的 Texture 交个渲染流程,渲染到最后的界面上。
优化点
初始化时机
下面是能在渲染之前进行的初始化内容
- MTLDevice
- MTLCommandQueue
- MTLLibrary
- PipelineState 用于配置对应的 shader 着色器
- Sampler 取样器
- Shader
这边需要仔细讲一下的是 Shader 相关的,包括 Shader 和 MTLLibrary,前面的文章有提到过,在 Metal 中 shader 可以在 app 编译的时候编译的,也可以在运行时编译,而在 OpenGL ES 中,Shader 都是运行时编译的,Metal 可以把这一部分的时间减少掉,**所以没有特殊的需求务必把 shader 的编译放在 app 编译时。
在 Metal System Trace 中可以通过 Shader Compilation 来查看这一部分的损耗:

并且 PipelineState 的构建是耗时操作,一旦构建之后也不会有太多的改动,建议把这 PipelineState 的初始化也放到和 MTLDevice / MTLCommandQueue 相同时机。
同样的 Sampler 的构建也是可以放在初始化的时候进行。
剩下的都是在每一次渲染进行初始化的
- CommandBuffer
- CommandEncoder

资源重用
最终提交的到 GPU 的资源 MTLResource,都是以如下两种种格式
- MTLBuffer
- MTLTexture
顾名思义 Buffer 可以用来传递一些未格式化的简单,如顶点信息等,Texture 用来传递图像信息。
在 Metal 中,MTLResource 是 CPU 和 GPU 是共享的数据,意味着可以避免数据在 CPU 和 GPU 之间来回拷贝的损耗,这个是由 storageMode 来确定的,默认情况下 MTLStorageModeShared ,CPG 和 GPU 之间共享,一般情况下不要修改。
从 CPU 处理的对象,如 UIImage / NSData 转换到 MTLTexture 都是有损耗的,所以尽量避免创建新的资源对象,对象能复用就复用。
在渲染视频界面的过程中,我们用到的 Buffer 只有代表正方形的四个顶点,这个是不会改变的,所以我们把顶点 buffer 的初始化,移动到应用初始化中。剩下的就只有两个 Texture,来自摄像头的 Texture ,这是肯定每次渲染都是新的,没办法处理。另一个是 LUT 滤镜的 Texture,因为其特殊性,固定大小每次切换滤镜时候其实只是每个像素的改变,所以没必要每次切换滤镜的时候进行 Texture 的重新创建。可以通过 Texture 的
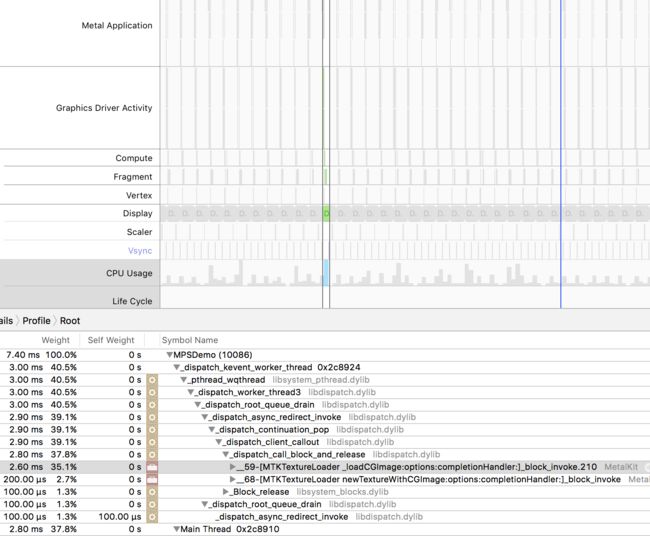
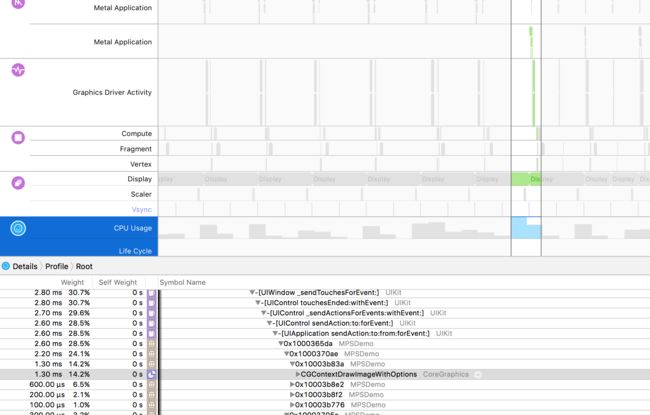
*- (void)replaceRegion:(MTLRegion)region mipmapLevel:(NSUInteger)level withBytes:(const void )pixelBytes bytesPerRow:(NSUInteger)bytesPerRow; 来通过 CGContext 重新替换滤镜,可以节省 CPU 的占用率,下图分别是重新创建和替换的 CPU 占用率,重新创建高达 70%,而替换只有 40 %左右。
在默写情况下,我们可能会重复操作同一个 Buffer 或者 Texture,然后根据其更新再来刷新界面,这时候就会存在一个问题,就是在我们刷新界面的时候,CPU 是无法去修改资源,必须等界面刷新完之后才能进行资源的更新,在渲染负责界面的时候,很容易发生 CPU 在等 GPU 的情况,这种时候便会造成掉帧的情况。苹果官方推荐的是一个叫做 Trible - Buffering 的方式来避免 CPU 的空等,其实就是使用 3 个资源和 GCD 信号量来控制并发,实现的效果如图:
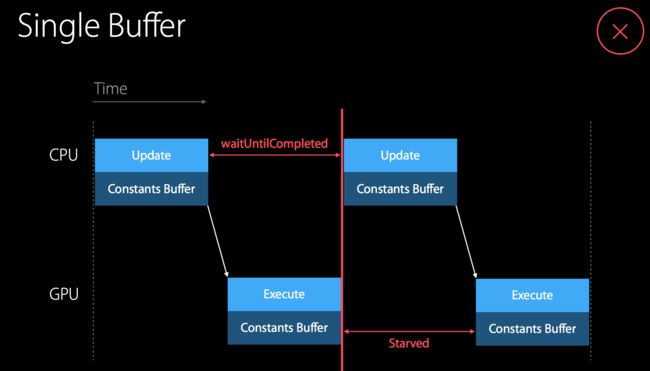
优化之前
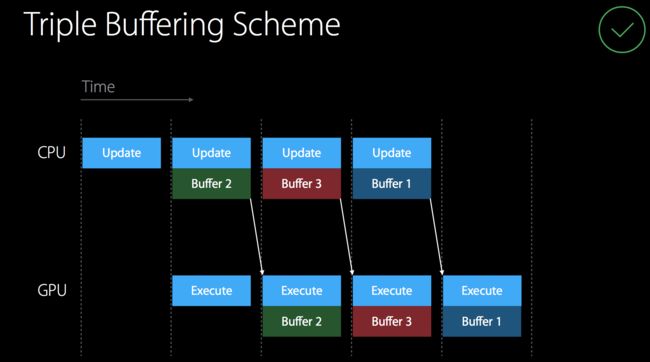
优化之后
就是有 Buffer1,Buffer2,Buffer3 三个 Buffer构成一个循环,不新建额外的 Buffer,当 3 个用完之后,开始修改第一个进行第一个的复用,通过在 CommandBuffer 的 Complete Handler 修改 GCD 的信号量来通知是否完成 Buffer 的渲染。
相关代码参考链接:
https://developer.apple.com/library/ios/samplecode/MetalUniformStreaming
其实在做滤镜处理的时候,也可以进行优化,在处理图像的时候,可以用 in-place 的方法来做滤镜添加,而不用再重新构造新的 Texture。
[self.filiter encodeToCommandBuffer:buffer
inPlaceTexture:&sourceTexture
fallbackCopyAllocator:nil];
渲染界面
在渲染流程的最后,我们会指定展示的界面:
- (void)presentDrawable:(id
通常情况下我们会使用 MTKView 作为展示的界面,其实最终用的也是 MTKView 中的 CAMetalLayer。
id drawable = [metaLayer nextDrawable];
[buffer presentDrawable:drawable];
一般是通过 layer 的 nextDrawable 方法来获取,但是要注意的是,这个方法是个阻塞方法,当目标没有空余的 Drawable 的时候,你的线程就会阻塞在这里。
当你的 Metal Performance Trace 上有 CPU 无故空闲了一大段的时候,应该检查一下是不是这个原因导致的,平时写的时候注意越晚获取 Drawable 越好。
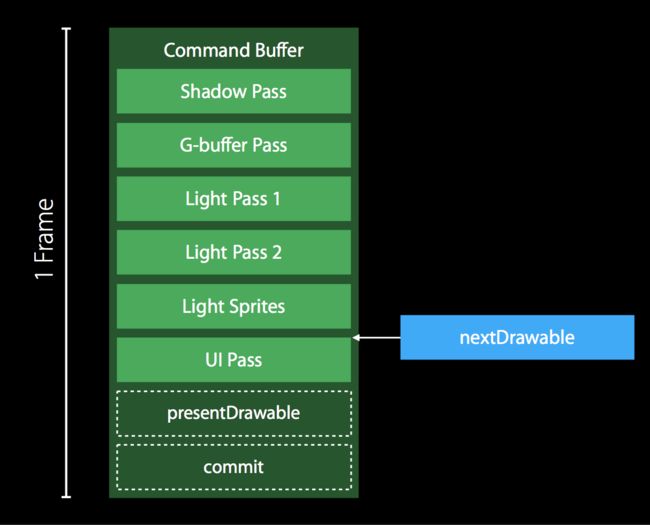
在我们这个例子中,其实实时滤镜视频对人眼来说 30 帧就够了,而 MTKView 默认是 60 帧,这里可以把 MTKView 的刷新率调整到 30 。
[self.metalView setPreferredFramesPerSecond:30];
但是这样子其实还是在 MetalView 的 - (void)drawInMTKView:(nonnull MTKView *)view; 方法中进行渲染,我之前的做法会在获取摄像头 Texture 的代理中,不断的获取新的 Texture,然后更新本地的 Texture 触发刷新,大概如下:
if (self.videoTexture != nil) {
//渲染
....
}
}
#pragma video delegate
- (void)didVideoProvide:(VideoProvider *)provide withLoadTexture:(id)texture{
//更新 texture
self.videoTexture = texture;
}
上面的这样的流程其实会存在问题,当 videoTexture 刷新快了,或者渲染处理慢了之后就会导致帧混乱和掉帧,而且 videoTexture 刷新慢了,也会导致无用的渲染流程。
后来我关闭了 MTKView 的自动刷新,通过 videoTexture 的更新来触发 MTKView 的刷新。
关闭自动刷新
[self.metalView setPaused:YES];
手动触发
if (self.videoTexture != nil) {
//渲染
}
}
#pragma video delegate
- (void)didVideoProvide:(VideoProvider *)provide withLoadTexture:(id)texture{
//触发
[self.metalView draw];
}
过多的 Encoder
在 Metal 的渲染过程中,通常我们会在一个 CommandBuff 上进行多次 Encoder 操作,但是每次 Encoder 对 Texture 的读写都会有损耗,所以要尽可能地把重复工作的 Encoder 进行合并。
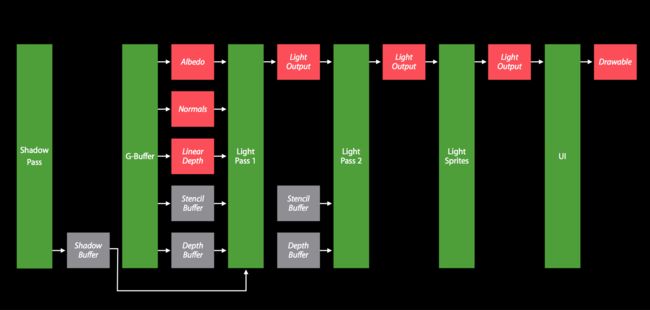
合并之后
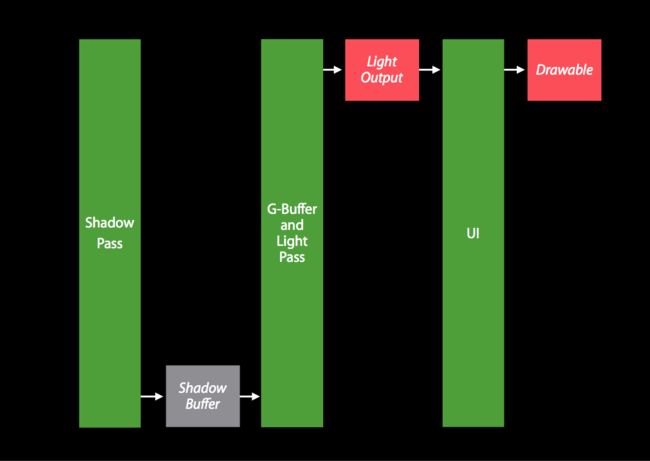
目前,我们现在一共只有两个 Encoder ,一个负责图像滤镜 ComputeEncoder,一个负责渲染 RenderEncoder。为了追求优化的极限,这里我尝试着对两个进行了合并制作了新的 shader ,讲道理着两个不应该合并的,因为负责的功能是不同的。
把原先的 fragment 的 shader 进行了修改,增加了一个 lut 的输入源和配置参数。
fragment half4 mps_filter_fragment(
ColoredVertex vert [[stage_in]],
constant RenderImageSaturationParams *params [[buffer(0)]],
texture2d sourceTexture [[texture(0)]],
texture2d lutTexture [[texture(1)]]
)
{
float width = sourceTexture.get_width();
float height = sourceTexture.get_height();
uint2 gridPos = uint2(vert.texCoords.x * width ,vert.texCoords.y * height);
half4 color = sourceTexture.read(gridPos);
float blueColor = color.b * 63.0;
int2 quad1;
quad1.y = floor(floor(blueColor) / 8.0);
quad1.x = floor(blueColor) - (quad1.y * 8.0);
int2 quad2;
quad2.y = floor(ceil(blueColor) / 8.0);
quad2.x = ceil(blueColor) - (quad2.y * 8.0);
half2 texPos1;
texPos1.x = (quad1.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * color.r);
texPos1.y = (quad1.y * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * color.g);
half2 texPos2;
texPos2.x = (quad2.x * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * color.r);
texPos2.y = (quad2.y * 0.125) + 0.5/512.0 + ((0.125 - 1.0/512.0) * color.g);
half4 newColor1 = lutTexture.read(uint2(texPos1.x * 512,texPos1.y * 512));
half4 newColor2 = lutTexture.read(uint2(texPos2.x * 512,texPos2.y * 512));
half4 newColor = mix(newColor1, newColor2, half(fract(blueColor)));
half4 finalColor = mix(color, half4(newColor.rgb, color.w), half(params->saturation));
uint2 destCoords = gridPos + params->clipOrigin;
uint2 transformCoords = uint2(destCoords.x, destCoords.y);
//transform coords for y
if (params->changeCoord){
transformCoords = uint2(destCoords.x , height - destCoords.y);
}
//transform color for r&b
half4 realColor = finalColor;
if (params->changeColor){
realColor = half4(finalColor.bgra);
}
if(checkPointInRectRender(transformCoords,params->clipOrigin,params->clipSize))
{
return realColor;
}else{
return color;
}
};
通过下面的方法传入
[encoder setVertexBuffer:vertexBuffer offset:0 atIndex:0];
[encoder setFragmentTexture:sourceTexture atIndex:0];
[encoder setFragmentTexture:self.filiter.lutTexture atIndex:1];
[encoder setFragmentSamplerState:self.samplerState atIndex:0];
[encoder setFragmentBytes:¶ms length:sizeof(params) atIndex:0];
Encoder 的并行
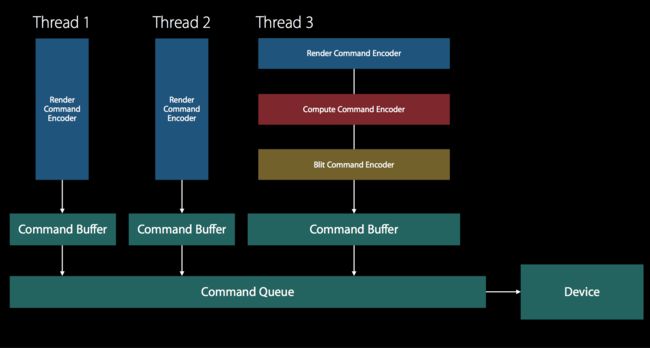
Metal 设计的本身就是线程安全的,所以完全可以在不同线程上 Encoder 同一个 CommandBuffer。将不同的 Encoder 分布在不同的线程上进行,可以大大提高 Metal 的性能。
在我的例子中因为相对比较简单,所以并不涉及到该优化,这里引用 wwdc 中的例子做个介绍,其中介绍了两种方式。
每个 Thread 都用不同的 Encoder 和配置
id commandBuffer1 = [commandQueue commandBuffer];
id commandBuffer2 = [commandQueue commandBuffer];
// 初始化操作
// 顺序的提交到 CommandQueue 中
[commandBuffer1 enqueue];
[commandBuffer2 enqueue];
// 创建每个线程的 Encoder
id pass1RCE =
[commandBuffer1 renderCommandEncoderWithDescriptor:renderPass1Desc];
id pass2RCE =
[commandBuffer2 renderCommandEncoderWithDescriptor:renderPass2Desc];
// 每个线程各自 encode ,并提交
[pass1RCE draw...]; [pass2RCE draw...];
[pass1RCE endEncoding]; [pass2RCE endEncoding];
[commandBuffer1 commit]; [commandBuffer2 commit];
效果如下
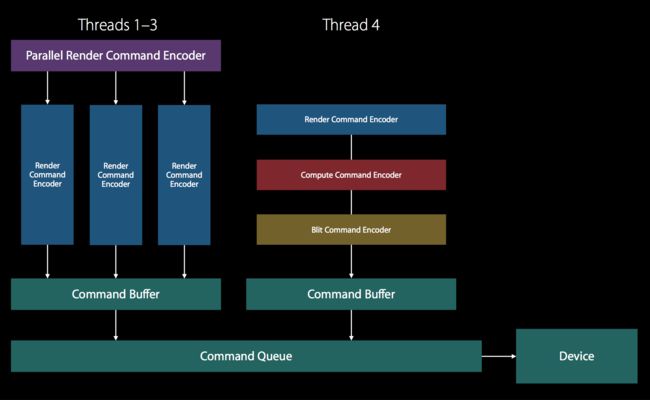
每个 Thread 共用一个 Encoder,在不同线程 encode
id commandBuffer = [commandQueue commandBuffer];
// 初始化
// 创建 Parallel Encoder
id parallelRCE =
[commandBuffer parallelRenderCommandEncoderWithDescriptor:renderPassDesc];
// 按 GPU 提交顺序创建子 Encoder e
id rCE1 = [parallelRCE renderCommandEncoder];
id rCE2 = [parallelRCE renderCommandEncoder];
id rCE3 = [parallelRCE renderCommandEncoder];
// 再各自的线程 encode
[rCE1 draw...]; [rCE2 draw...]; [rCE3 draw...];
[rCE1 endEncoding]; [rCE2 endEncoding]; [rCE3 endEncoding];
// 所有的子 Encoder 必须要 Parallel Encoder 停止之前停止
[parallelRCE endEncoding];
[commandBuffer commit];
效果如下
Some more things
在针对这个例子做优化时,还有几个点可以进行优化,但并不是通用的,这里我列出来可以作为参考。
- 滤镜的输出对象调整
之前优化过的滤镜是通过 in-place 的方式来修改,最后渲染到 MTKView 中。后来发现其实 MTKView 本身就提供一个 Texture 供渲染,直接写入这个 Texture 就可以了。
- (void)systemDrawableRender:(id) texture{
@autoreleasepool {
id buffer = [_queue commandBuffer];
CAMetalLayer *metaLayer = (CAMetalLayer*)self.metalView.layer;
id drawable = [metaLayer nextDrawable];
id resultTexture = drawable.texture;
[self.filiter encodeToCommandBuffer:buffer
sourceTexture:texture
destinationTexture:resultTexture];
[buffer presentDrawable:drawable];
[buffer commit];
}
}
- shader 的计算优化。在 Metal Performance Trace 中能够看到不同 shader 的计算时间,在这个例子中可以优化的就是滤镜的那个 compute 的 shader,把其中的计算简化,尽量做整数运算并减少运算的次数,把计算的次数减少,方法是配置 threadgroup 时候,需要高度和宽度进行计算,可以使用输出和输入中那个较小那个尺寸进行计算,同样在 shader 中编码的时候,也要注意当前输入的是哪一个尺寸,避免读写到超出尺寸的像素。
结果
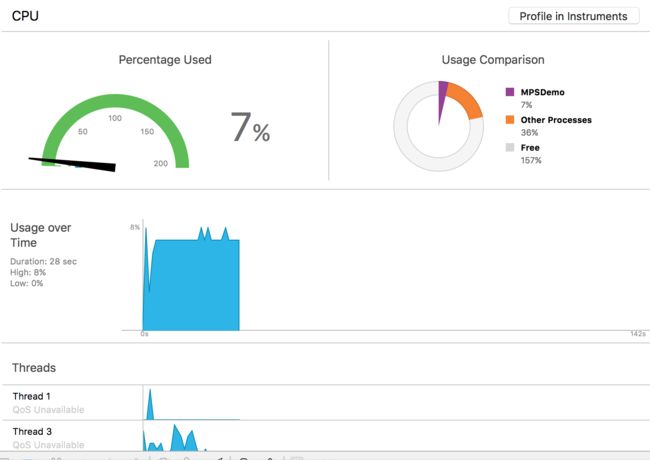
下面是优化前后的对比图
优化之前:
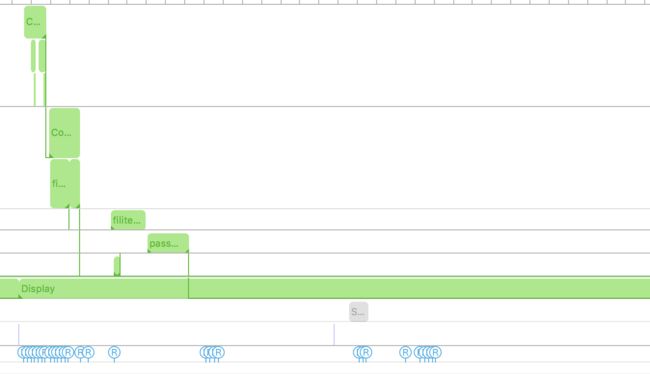
GPU 平均耗时在 1.3 filter + 2.6 render + 0.2 = 4ms
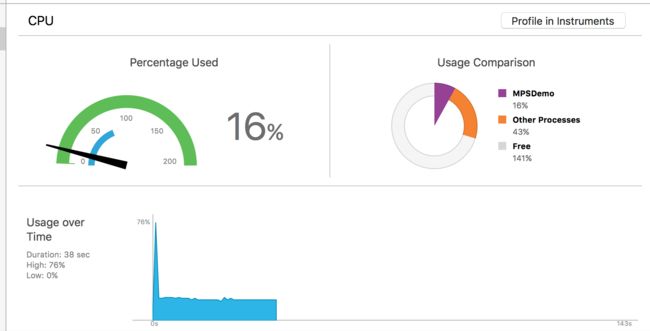
CPU 平均使用率在 18 左右 峰值 在 30 %
优化之后:
CPU 的使用率为 10% 峰值为 20 %
GPU 的平均耗时为 1.36ms
总结
最后我们总结一下整体优化的流程
- 能提前初始化的内容,不要放到渲染时在做
- 能减少对象内存的创建和拷贝就减少
- 能复用的对象,不要重复创建
- 能越晚获取 Drawable 就晚点获取
- 能合并的 encoder 尽量合并
- 多线程 encode 来减轻 CPU 压力
参考
GPU-Accelerated Image Processing
WWDC 2015 Metal Performance Optimization Techniques
Metal Best Practices Guide