第三课进阶作业分析
目的
基于 smoking_cancer.text 数据,用描述统计量和统计图表对其进行分析,并投稿到“解密大数据”专栏。
思路:
• 人均吸烟数的集中趋势
• 人均吸烟数的离散程度
• 吸烟数与某种疾病的关系
正式开始
导入相关包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBankend.figure_format = 'retina'
读取数据,查看头五行,了解下数据概况
从下面可以看出,数据并没有缺失
df = pd.read_table('smoking_cancer.txt')
df.head()
根据info()函数,可以查看到数据没有缺失
df.info()
RangeIndex: 44 entries, 0 to 43
Data columns (total 6 columns):
STATE 44 non-null object
CIG 44 non-null float64
BLAD 44 non-null float64
LUNG 44 non-null float64
KID 44 non-null float64
LEUK 44 non-null float64
dtypes: float64(5), object(1)
memory usage: 2.1+ KB
查看人均吸烟数的集中趋势
思路:
- 查看均值、中位数,并判断偏度
- 查看直方图
df.CIG.mean()
24.914090909090906
df.CIG.median()
23.765
import sys #用来正常显示中文标签
reload(sys)
sys.setdefaultencoding('utf-8')
plt.rcParams['font.sans-serif']=['SimHei']
plt.hist(df.CIG, rwidth=0.9)
plt.title('人均吸烟数的直方图')
plt.show()
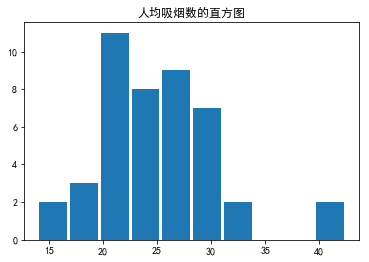
output_12_0.png
结论:
- 均值>中位数,从直方图中也可以看出,右偏的数据偏多,因此可以认为人均吸烟数呈现右偏的情况
- 均值和中位数比较接近,可见右偏程度较小
x = df.index.values
plt.figure(figsize=(10,4))
plt.bar(x, df.CIG, width = 0.9)
plt.title('各州的人均吸烟数')
plt.ylabel('百分比')
plt.xticks(x, df.STATE, rotation = 70)
for a,b in zip(x, df.CIG):
plt.text(a, b+0.5, '%.1f' %b, ha='center')
plt.show()
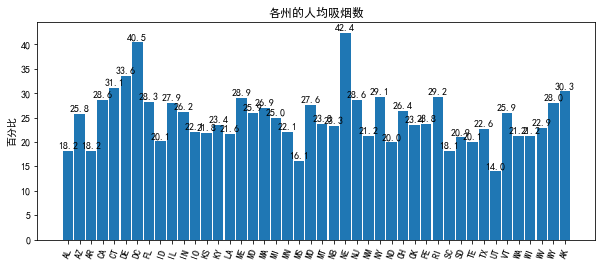
output_13_0.png
from __future__ import division
(sum(df.CIG >= 30) + sum(df.CIG < 20)) / len(df.CIG)
0.25
sum(df.CIG.between(20, 30)) / len(df.CIG)
0.75
结论
- 大部分的州的人均吸烟数在(20,30)之间,这部分达到75%
查看人均吸烟数的离散程度趋势
思路:
- 查看全距、IQR、箱图
- 比较IQR、均值、标准差之间数值大小
df.CIG.max() - df.CIG.min()
28.399999999999999
df.CIG.quantile(0.75) - df.CIG.quantile(0.25)
6.8675
plt.boxplot(df.CIG)
plt.show()
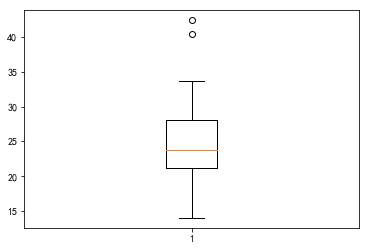
output_21_0.png
df.CIG.var()
31.06151775898521
df.CIG.std()
5.573286082643274
df.CIG.mean() / df.CIG.std()
4.470269521365528
结论:
- 从IQR的数值远小于全局range,并且IQR与标准差接近,可以观察出各州的吸烟数还是比较集中的,主要集中在中位数附近一个标准差左右的范围之内
- 均值是标准差的4.5倍左右,可见相对来说标准差较小
吸烟数与疾病的关系
思路
绘制散点图,求相关系数
吸烟数与膀胱癌
从散点图中可以很明显地看出患膀胱癌的比例与吸烟数呈现较好的正相关关系,从二者的相关系数可以证明这点
plt.scatter(df.CIG, df.BLAD)
plt.title('吸烟数与膀胱癌的关系')
plt.xlabel('吸烟数')
plt.ylabel('膀胱癌')
plt.show()
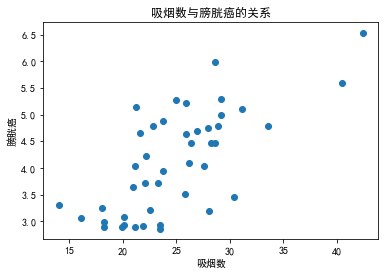
output_29_0.png
np.corrcoef(df.CIG, df.BLAD)[0,1]
0.70362185946144185
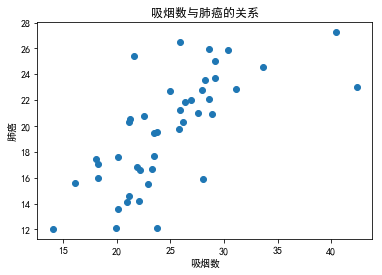
吸烟数与肺癌
从散点图中可以很明显地看出患肺癌的比例与吸烟数呈现较好的正相关关系,从二者的相关系数可以证明这点
plt.scatter(df.CIG, df.LUNG)
plt.title('吸烟数与肺癌的关系')
plt.xlabel('吸烟数')
plt.ylabel('肺癌')
plt.show()
output_32_0.png
np.corrcoef(df.CIG, df.LUNG)[0,1]
0.6974025049275292
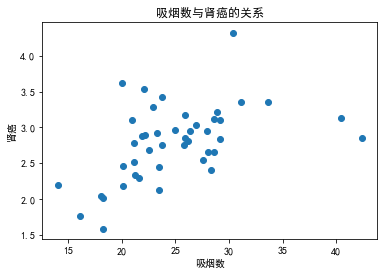
吸烟数与肾癌
从散点图中可以很明显地看出患肾癌的比例与吸烟数呈现一定的正相关关系,二者的相关系数接近于0.5,
plt.scatter(df.CIG, df.KID)
plt.title('吸烟数与肾癌的关系')
plt.xlabel('吸烟数')
plt.ylabel('肾癌')
plt.show()
output_35_0.png
np.corrcoef(df.CIG, df.KID)[0,1]
0.48738961703356476
吸烟数与白血病
从散点图中可以很明显地看出患白血病的比例与吸烟数几乎没什么关系,二者的相关系数接近于0可以说明这点
plt.scatter(df.CIG, df.LEUK)
plt.title('吸烟数与白血病的关系')
plt.xlabel('吸烟数')
plt.ylabel('白血病')
plt.show()

output_38_0.png
np.corrcoef(df.CIG, df.LEUK)[0,1]
-0.068481229476638969