Reading Thieves’ Cant: Automatically Identifying andUnderstanding Dark Jargons from Cybercrime Marketplaces
本次介绍的论文被USENIX SecuritySymposium 2018收录,作者Kan Yuan, HaoranLu, Xiaojing Liao, and XiaoFeng Wang等人均来自Indiana University Bloomington。
1.主要内容
黑市(Underground forum)是非法交易生态系统中的重要组成部分,在黑市上,许多参与者可能会策划恶意活动(比如黑客攻击或者恐怖行为),或者进行违法交易。为了隐藏交易网站上面的非法行为,他们常常会在上面使用一些看起来非常无害的词汇来掩盖其犯罪行为。由此衍生出了一个新的方向——行业黑话(Dark jargon)检测。行业黑话的产生是持续性的,不同的人可能会使用不同的行业黑话,目前尚且只能利用人工进行检测,效率低下,准确度也非常低,因此找到一个自动检测行业黑话的方法是十分具有意义的。
在这篇论文中,作者对分析了四个非常出名的黑市网站,希望能够通过对于这些网站上交流行为的分析找到可能会与违法行为相关的黑话,并且确定其隐藏含义。虽然网络犯罪中存在的黑话因为其隐秘性非常难以确认,但是它与隐含的根源词汇在黑话文本的上下文语义环境上依旧会有很大程度重合,同时会同黑话本身所使用的词汇的正常文本的上下文环境发生明显的变化。例如,”popcorn”作为在正常的单词使用的时候,通常会与”eat”,”chocolate”等词汇一同使用,但是当它代表大麻”marijuana”的时候,则通常会和”nugz”,”buds”等词汇一同出现。
基于这一想法,作者设计了名为Cantreader的模型,通过利用自然语言处理技术将来自暗网,合法论坛与Wikipedia中的语料文本进行分析处理,对其中涉及到的词汇分别抽取语义模型,最终通过语义相似度对比确定可能会有隐藏含义的词汇。在确定黑话含义时,作者先从通用概念中选取了与犯罪行为相关的词汇,作为上位词集合,并将与黑话语义最为接近的上位词作为其潜在的含义。
2. 系统设计与实现
如图1所示,Cantreader模型主要包括两部分:
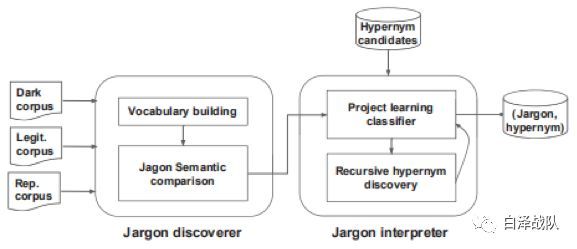
1)第一部分Jargon Discover是对于来自不同网站的语料库进行特征抽取,利用神经网络获取能够代表其语义含义的词向量。对于非法数据集Dark Corpus与合法集合LegitCorpus的相似度比较可以得到在两个环境下语义不同的词汇。作者为了减小因为网站类型的而导致的用语习惯不同(比如论坛网站中会经常出现一些特定的论坛词汇),选择了一个常用的新闻论坛Reditt作为对比语料Legit Corpus。然而Reditt本身并不是一个较为正式的网站,因此语料中一部分词汇的含义可能会与标准用法有所出入,为此,作者又引入了标准语料库Rep Corpus, Rep Corpus的数据来自于Wikipedia的相关页面。当一个词汇在DarkCorpus与Legit Corpus语料中相似度较低,而在Legit Corpus与Rep Corpus中的相似度较高的时候,被认为是黑话(Jargon)。
2)第二部分Jargon Interpreter则用于从通用领域知识图谱中抽取的可能在黑市交易中出现的词汇,认为这些词汇集合H有可能蕴含了黑话词汇Jargon的含义,或者与Jargon具有包含关系(”is-a”关系)。H被称为上位词集合,其中与Jargon语义最为接近的词汇被称为Jargon的上位词。得到H后,作者对于获取的潜在黑话通过分类的方式获取它的上位词,认为Jargon的上位词即代表了它的潜在含义。
2.1 JargonDiscover
在语义抽取这一步,论文的作者选择Skip-Gram模型来提取词向量。传统自然语言处理方法中,词汇的语义表示有多种类型的方法,目前主流的方法集中于基于神经网络的词向量抽取方式,如Skip-Gram,5CBOW模型等。Skip-Gram模型使用一个词汇的上下文信息来描述该词汇的语义。根据这一原理,具有相同上下文环境的词汇可以认为在语义上面是相同的。这与论文索要解决的问题是极为契合的。
在实验中,作者考察了现有的SkipGram模型(gensim所提供的Wor2Vec模型),发现虽然具有以上的优势,但是Word2Vec在不同语料库下所训练得到的模型是没有可比性的,机械地合并所有语料库又会使得单个语料库中词汇语义信息无法甄别。因此,他们再次基础上进行了改进,提出Semantics Comparison Model来判断词汇的语义变化。他们将原有的one-hot向量长度翻倍,并且在原有向量的一侧加入同等长度的零向量义词作为区分。
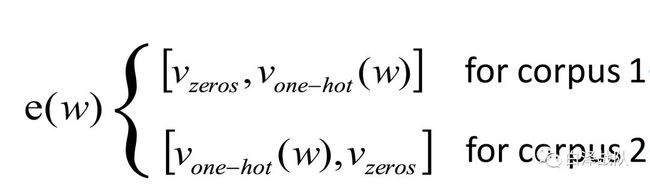
显然这种改进的方式是非常巧妙的,它规避了Word2Vec模型在训练初始化时所产生的随机问题,并且也规避了输入层与输出层之间非显式关系所导致的不可比性。进行Skip-Gram训练时,其输入层被定义为一个神经元,输入向量即是所需预测的词汇的bag-of-word向量表示,通过与权重矩阵相乘之后,乘积作为隐藏层的输入,因此,对隐藏层来说,其输入仅仅是权重矩阵的某一行,最后隐藏层输出的结果与其他权重矩阵之积作为输出层的输入。在这一过程中所涉及到的全部权重矩阵即为所需学习的参数。
除此之外,在抽取词向量之前,必须对文本进行预处理,减少其中含有的大量无关词汇以及因为出现次数极少而导致语义不完整,或者并非在所有的语料库中均出现,因此导致语义不完整的词汇。论文所选择的语料库主要抽取自论坛,论坛用户在发言时经常会表现出拷贝别人的发言这一行为,因此有一部分词汇虽然出现按次数较多,但是其语义环境罕有变化,异常单薄,因此,作者在词频检测的基础之上,进一步提出了window_context概念,表示在某一个窗口长度中锁包含的上下文,对于一个词汇,作者不仅限制它的词频(),并且限制其上下文种类的数量。向量提取之后,作者对比了。当前者较大,而后者较小的时候,则认为该词汇在非法语料中具有二义性。考虑到一些词汇本身存在一词多以的现象,作者对多义词的阀值做了额外的规定。
2.2 JargonInterpreter
利用Wikidata获取上位词集合之前,作者首先人工从暗网论坛中选取了种子词集合,并且利用图遍历算法在Wikidata中寻找与之具有is-a关系的所有直接或者间接的子类。
获取上位词集合而之后,作者将上位关系查询视为了一个语义分类问题,他们将所需要检测词汇的词向量与备选上位词的词向量进行对比,计算他们之前的相似性。在这个基础上,作者使用了随机森林算法。
给定备选黑话后,首先比较它与森林中根节点词汇的相似度,从中寻找出最为相似的,如果没有找到足够相似的节点,则将其标为UnKnow,否则遍历与之最为相似的孩子节点,从中寻找最为相似的节点,倘若所有孩子节点的相似度低于上一层中所找到的相似节点,则输出上一层的节点,否则重复之前的操作,继续遍历当前树的下一层,直到寻找到合适的节点。
3. 实验与结果
3.1 实验数据
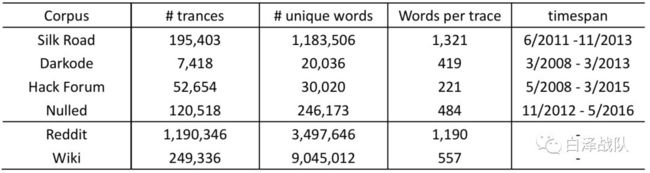
在实验中作者主要选取了四种语料库——DarkCorpus,Benign Corpora,Hypernymy dataset与Groundtruthdataset。Dark Corpus来自四个黑市网站。Benign corpora包含合法语料库Reddit与标准语料库Wikipedia。 Hypernymydataset则用于训练关系抽取模型,该数据集将来自于wordNet,DBPedia, Wikidata 和Yago的实体用“is-a”关系链接了起来。Groundtruthdataset包含有774个已知的行话集合以及它们的上位词。这个数据集来自于两个来源:DEA所提供的 drug code wordlist(其中包含1734个关于毒品的词汇)与 Cybercrime marketplaceproduct list(其中包含1292个来自the Nulled, Hacking Forum以及Darkode的非法产品,被一些学术研究者们收录)。在此基础上,作者针对这两个数据集进行了详细的分析从中选取出774个词汇以及上位词生成了Groundtruth集合。
3.2 SCM测试实验
为了测试Semantics ComparisonModel模型的可靠性,作者一共设计了三个实验。
实验一中,作者使用Text8作为训练语料,对于语料库中的每一个单词,通过SCM模型生成了一对向量,分别代表了它在相对应的语料中的语义信息。当两个词汇的语义信息相同时,它们的余弦相似度应该近似为1,而实验结果也显示SCM获取的向量组的平均相似度为0.98.
作者同时在一个语料库上进行了两次独立的Word2Vec训练,结果显示,同一个词汇在来自不同的模型时,它的词向量的相似度仅有0.49.
这一组实验证明了来自两个模型的Word2Vec词向量的不可比性以及SCM模型在面对来自不同语料的词汇时其表示依旧是有意义的。

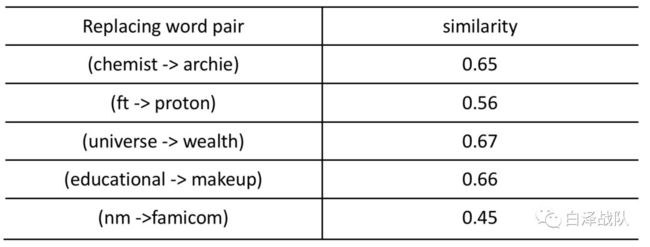
实验二衡量了SCM对于同义异型词汇的相似度识别准确度。作者在实验二中将Text8中的某一些词汇进行了替换,形成新的语料库,并对两个语料库利用SCM建模,最后的结果显示,替换后的词汇虽然从词形上面发生了很大的变化,但是其平均相似度高达0.98。
实验三检测了SCM生成的词向量的质量。实验三中,作者选取了Text8与一个从黑市中收集到的语料库Nulled的一部分文本作为训练语料。在训练获取相关的词向量之后,作者使用了Tomas等人对于上下位词汇衡量的代码,计算其中包含的行业黑话与其上位词的相似度。对比试验选取了Word2Vec模型。最终实验结果中SCM向量的准确度为46%,Word2Vec的准确度为50%,由此可以得到,在SCM在保证其跨模型语义描述准确性的同时并未牺牲上下位词汇关系识别的准确性。
3.3 其他实验结果
Drak Corpus与Benign Corpus一共包含1,147,736条踪迹,含有117M的词汇。进行测试机与训练计划分时,依旧遵守2/8原则,最终Cantreader模型识别出3462个黑话以及它们的上位词。在Groundtruth的774个黑化中,598个结果分类正确,召回率为77.2%。一部分被分类为黑话但是并未被Cantreader中被标识的词汇实际上在预料中并没有充分的语义环境。而且来自DEA(Drug Enforcement Administration)的一部分数据被宣称包含错误[6]。
在排除这些问题之后,作者随即抽取了200个被标识为黑话的词汇,检测出其中182个分类正确,从而得出Cantreader精确度为91%。
4. 结果分析
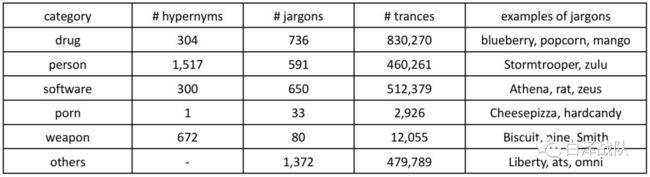
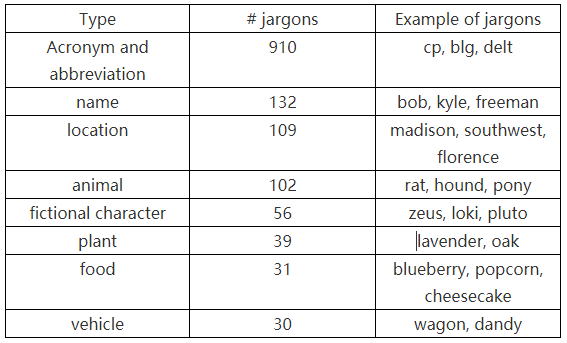
从实验结果中,作者发现了一些有趣的规律。行话最多的领域是毒品,有736个行话。在这当中有692个没有被DEA标为行话,但是却在暗网中却非常常见,例如mango在540个非法交流记录中意为大麻。而且不同网站的黑话用法是很大区别的,其中SilkRoad中含有最多的行话。参与者的类型也会导致使用黑话的类型发生差异,毒贩经常会使用一些描述药品口味的词汇来替代毒品(如blueberry ),黑客喜欢使用神话中的人物名称(如:Loki)。下表展示了黑市论坛中常见黑话的几种类型以及占比。
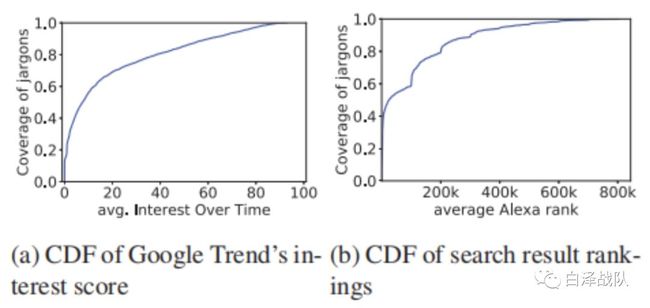
另一方面,作者尝试从与现有的搜索引擎的搜索结果进行对比。由于行话通常具有一个非常普遍的正常语义,因此几乎所有在利用行话搜索的结果中,前十都是一些信誉良好的网页。而在含有黑话的网页中,60%都具有低于1000k的评级,即被认为是信誉非常高。这是因为与之前的研究相比,本文寻找出来的黑话有一个“更具有欺骗性的外表”,很少会被人与攻击性相关起来。
5. 总结
本文介绍的论文利用自然语言处理技术对于暗网论坛上面的文本进行分析,对于其中的词汇与其他合法网站之间语义的差别,从而自动化地寻找出可能含有隐喻的词汇,并且在之后将这些词汇同普遍公认的犯罪相关词汇进行比较,从中寻找出最为相似的作为该词汇的隐藏含义。最终其检测效果较好,但是这篇论文所提出的Cantreader模型只能解决单个词汇的识别问题,而无法处理词组。并且如果黑市论坛的使用者们在使用行话的时候尽可能多地尝试还原行话原来的语义环境,则检测的难度会增加很多。后续可以考虑从对于词组的识别入手扩展模型的可用性,或者提升目前上位词检测的准确度来提高整个模型的准确度。
文 | 迟见
