之前,在 github 上开源了 ambari-Kylin 项目,可离线部署,支持 hdp 2.6+ 及 hdp 3.0+ 。github 地址为:https://github.com/841809077/ambari-Kylin ,欢迎 star 。
这段时间,陆续有不少朋友通过公众号联系到我,问我相关的集成步骤。今天正好休息,索性将 ambari 自定义服务集成的原理给大家整理出来。
它其实不难,但是网络上并没有多少这方面的资料分享,官方也很少,所以学习门槛就稍微高了一些。但你如果能持续关注我,我相信您能快速上手。
一、简述 ambari
ambari 是一个可视化管理 Hadoop 生态系统的一个开源服务,像 hdfs、yarn、mapreduce、zookeeper、hive、hbase、spark、kafka 等都可以使用 ambari 界面来统一安装、部署、监控、告警等。
对于未受 ambari 界面管理的服务,比如 Elasticsearch、Kylin、甚至是一个 jar 包,都可以利用 自定义服务集成相关技术 将 服务 集成到 ambari 界面里。这样,就可以通过 ambari 实现对 自定义服务 的 安装、配置、启动、监听启动状态、停止、指标监控、告警、快速链接 等很多操作,极其方便。
二、宏观了解自定义服务集成原理
对于安装过 ambari 的朋友可能比较熟悉,我们在部署 hdp 集群的时候,在界面上,会让我们选择 hdp stack 的版本,比如有 2.0、... 、2.6、3.0、3.1 等,每一个 stack 版本在 ambari 节点上都有对应的目录,里面存放着 hdp 各服务,像 hdfs、yarn、mapreduce、spark、hbase 这些,stack 版本高一些的,服务相对多一些。stack 版本目录具体在 ambari-server 节点的 /var/lib/ambari-server/resources/stacks/HDP 下,我们用 python 开发的自定义服务脚本就会放到这个目录下。
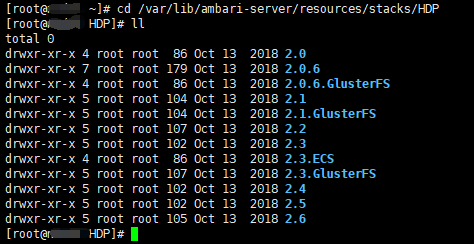
将自定义服务放到指定目录下,我们需要重启 ambari server 才能在 添加服务 界面加载出来我们的自定义服务,ambari 在安装自定义服务的过程中,也会将 python 开发的自定义服务脚本分发到 agent 节点上,由 agent 节点的 自定义服务脚本 来执行 安装、部署 步骤。
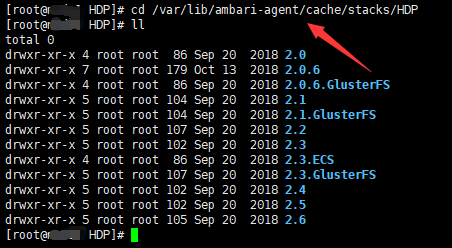
等通过 ambari 安装自定义服务之后,ambari 会在数据库(比如 mysql)相关表里将自定义服务相关信息进行保存,和记录其它 hdp 服务一样的逻辑。
三、微观了解自定义服务集成原理
一个自定义服务暂且将它定义为一个项目,项目名称须为大写,使用 python 编写。该项目框架有那么几个必不可少的文件或目录,分别是:
metainfo.xml 文件:描述了对整个项目的约束配置,是一个 核心 文件。
configuration 目录:里面放置一个或多个 xml 文件,用于将该服务的配置信息展示在前端页面,也可以在ambari 页面上对服务的一些配置做更改,如下图所示:

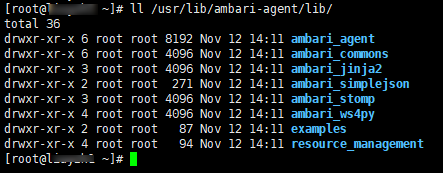
package 目录:里面包含 scripts 文件夹,该目录下存放着 python 文件,用于对服务的安装、配置、启动、停止等操作。自定义服务 python 脚本依赖的模块是 resource_management 。该模块分布在不同的目录下,但内容是一致的,如下图所示:

除了上述必不可少的目录或文件之外,还有一些文件可以丰富我们自定义服务的功能。比如:
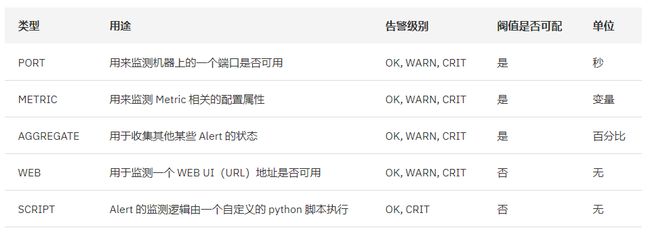
alerts.json 文件:描述 ambari 对服务的 告警 设置。告警类型有 WEB、Port、Metric、Aggregate 和 Script ,如下图所示:
quicklinks.json 文件:用于生成快速链接,实现 url 的跳转。可支持多个 url 展示。
role_command_order.json 文件:决定各个服务组件之间的启动顺序,详情可参考:https://841809077.github.io/2018/09/26/role_command_order.html
如下图所示,这是自定义服务 KYLIN 的项目框架:
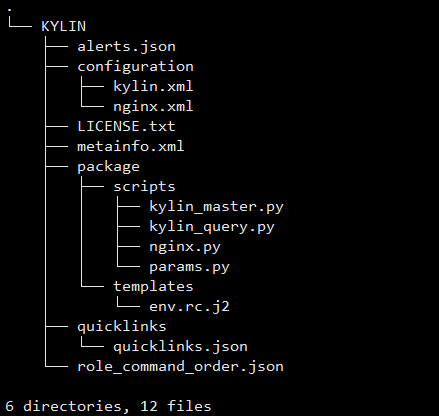
四、课程宣传
ambari 自定义服务集成的细节有很多,但是官方网站上并没有太多的篇幅去介绍这一块知识,只能自己慢慢摸索。幸亏有公司的支持和个人的努力,我已经将 自定义服务 的大部分知识点掌握,特绘制相关的知识脑图,具体如下:

后面我会利用业余时间将上述脑图中的 12 项录制成视频,节约大家学习成本。如果大家有这方面的需求,可以关注我的公众号,加我好友,一起讨论技术与人生。
