项目简介:使用Python3抓取12306网站信息提供一个命令行的火车票查询工具。通过该项目的实现,可以熟悉Python3基础及网络变成,以及docopt,requests,prettytable等库的使用。
项目由小蜗牛发布在实验楼,完整教程及在线练习地址:Python3 实现火车票查询工具,可以直接在教程中下载代码使用demo。
一、实验简洁
当你想查询一下火车票信息的时候,你还在上 12306 官网吗?或是打开你手机里的 APP?
下面让我们来用 Python 写一个命令行版的火车票查看器, 只要在命令行敲一行命令就能获得你想要的火车票信息!如果你刚掌握了Python基础,这将是个不错的小练习。
1.1知识点
- Python3 基础知识的综合运用
- docopt、requests 及 prettytable 库的使用
1.2 效果截图
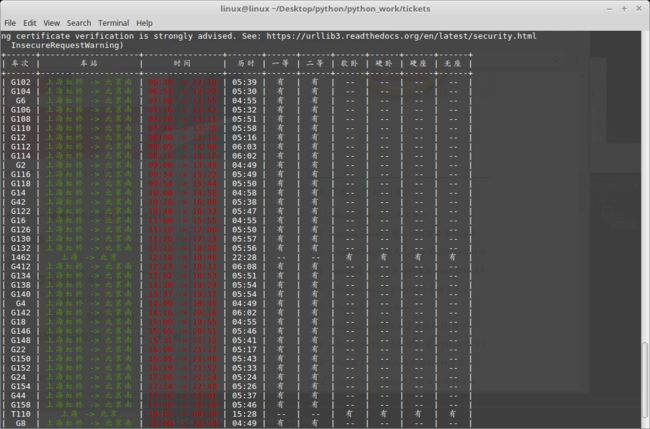
二、接口设计
一个应用写出来最终是要给人使用的,哪怕只是给你自己使用。
所以,首先应该想想你希望怎么使用它?让我们先给这个小应用起个名字吧,既然及查询票务信息,那就叫它 tickets好了。
我们希望用户只要输入出发站,到达站以及日期就让就能获得想要的信息,比如要查看8月25号上海-北京的火车余票, 我们只需输入:
$ tickets shanghai beijing 2016-08-25
注意: 由于实验楼环境中无法输入中文,所以我们的参数设计为拼音的形式,在这里思考下使用拼音是否有什么弊端?
对这一接口进行抽象得到:
$ tickets from to date
另外,火车有各种类型,高铁、动车、特快、快速和直达,我们希望可以提供选项只查询特定的一种或几种的火车,所以,我们应该有下面这些选项:
- -g 高铁
- -d 动车
- -t 特快
- -k 快速
- -z 直达
这几个选项应该能被组合使用,所以,最终我们的接口应该是这个样子的:
$ tickets [-gdtkz] from to date
接口已经确定好了,剩下的就是实现它了。
三、代码实现
首先安装一下实验需要用到的库:
$ sudo pip install requests prettytable docopt
- requests, 不用不多介绍了吧,使用 Python 访问 HTTP 资源的必备库。
- docopt, Python3 命令行参数解析工具。
- prettytable, 格式化信息打印工具,能让你像 MySQL 那样打印数据。
3.1 解析参数
Python有很多写命令行参数解析工具,如 argparse, docopt, click,这里我们选用的是 docopt 这个简单易用的工具。docopt 可以按我们在文档字符串中定义的格式来解析参数,比如我们在 tickets.py:
注意: 实验楼中无法输入中文,参数后的中文可以使用拼音代替。
# coding: utf-8
"""Train tickets query via command-line.
火车票通过命令行查询。
Usage:
tickets [-gdtkz]
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets beijing shanghai 2016-08-25
"""
from docopt import docopt
def cli():
"""command-line interface 命令行接口"""
arguments = docopt(__doc__)
print(arguments)
if __name__ == '__main__':
cli()
下面我们运行一下这个程序:
$ python3 tickets.py beijing shanghai 2017-03-01
我们得到下面的结果:
{'-d': False,
'-g': False,
'-k': False,
'-t': False,
'-z': False,
'': '2016-08-25',
'': 'beijing',
'': 'shanghai'}
3.2获取数据
擦书已经解析好了,下面就是如何获取数据了,这也是最主要的部分。首先我们打开12306,进入余票查询页面,如果你使用Chrome,那么按F12打开开发者工具,选中Network一栏,在查询框中我们输入上海到北京,日期2017-03-03,点击查询,我们在调试工具发现,查询系统实际上请求了下面这两个URL:
https://kyfw.12306.cn/otn/leftTicket/log?leftTicketDTO.train_date=2017-03-01&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=BJP&purpose_codes=ADULT
https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2017-03-01&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=BJP&purpose_codes=ADULT
并且返回的时JSON格式的数据!
接下来问题就简单了,我们只需要构建请求URL然后解析返回的Json数据就可以了。但是我们发现,URL里面 from_station 和 to_station 并不是汉字或者拼音,而是一个代号,而我们想要输入的是汉字或者拼音,我们要如何获取代号呢?我们打开网页源码看看有没有什么发现。
果然,我们在网页里面找到了这个链接:https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8955 这里面貌似是包含了所有车站的中文名,拼音,简写和代号等信息。但是这些信息挤在一起,而我们只想要车站的拼音和大写字母的代号信息,怎么办呢?
正则表达式就是答案,我们写个小脚本来匹配提取出想要的信息吧, 在parse_station.py中:
# coding: utf-8
import re
import requests
from pprint import pprint
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.8955'
response = requests.get(url, verify=False)
stations = re.findall(r'@[^|]+' #拼音缩写三位
r'\|([^|]+)'#站点名称
r'\|([^|]+)'#编码
r'\|[^|]+' #拼音
r'\|[^|]+' #拼音缩写
r'\|[^@]+' #序号
,response.text)
stations = dict(stations)
stations = dict(zip(stations.keys(), stations.values()))
pprint(stations, indent=4)
注意,上面的正则表达式匹配出的结果转为字典后,字典的键是大写字母大号,这显然不是我们想要的结果,于是,我们通过一个变换将键值反过来。 我们运行这个脚本,它将以字典的形式返回所有车站和它的大写字母代号, 我们将结果重定向到 stations.py 中,
$ python3 parse_station.py > stations.py
我们为这个字典加名字,stations, 最终,stations.py文件是这样的:
stations = { '一间堡': 'YJT',
'一面坡': 'YPB',
'一面山': 'YST',
'七台河': 'QTB',
'七甸': 'QDM',
'七营': 'QYJ',
'七里河': 'QLD',
'万乐': 'WEB',
'万发屯': 'WFB',
'万宁': 'WNQ',
...}
现在,用户输入车站的中文名,我们就可以直接从这个字典中获取它的字母代码了:
from docopt import docopt
from stations import stations
def cli():
"""command-line interface 命令行接口"""
arguments = docopt(__doc__)
from_station =stations.get(arguments[''])
to_station = stations.get(arguments[''])
date = arguments['']
# 构建URL
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(
date, from_station, to_station
)
万事俱备,下面我们来请求这个URL获取数据吧!这里我们使用 requests 这个库, 它提供了非常简单易用的接口,并且将该方法存放在get_data.py文件中
import requests
requests.packages.urllib3.disable_warnings()
class GetData(object):
def __init__(self, date, from_station, to_station):
self.date = date
self.from_station = from_station
self.to_station = to_station
def request_12306(self):
"""requests跟12306拿数据"""
# 构建URL
url = 'https://kyfw.12306.cn/otn/leftTicket/log?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(
self.date, self.from_station, self.to_station
)
# 添加verify=False参数不验证证书
r = requests.get(url, verify=False)
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(
self.date, self.from_station, self.to_station
)
r = requests.get(url, verify=False)
return r.json()
3.3解析数据
我们在formats.py文件中封装一个简单的类来解析数据:
"""返回规范个格式的 table"""
from prettytable import PrettyTable
from colorama import init, Fore
class Formats(object):
def __init__(self, datas, options):
self.datas = datas
self.options = options
def format_data(self):
"""返回规范的 table"""
ptable = PrettyTable()
header = '车次 车站 时间 历时 一等 二等 软卧 硬卧 硬座 无座'.split()
ptable._set_field_names(header)
for train in self.datas:
trains = train.get('queryLeftNewDTO')
if trains is not None and trains != '':
initial = trains['station_train_code'].lower()[0]
if not self.options or initial in self.options:
ptable.add_row([trains['station_train_code'], Fore.GREEN
+ "%s -> %s" % (trains['from_station_name'],
trains['to_station_name']) + Fore.RESET,
Fore.RED + "%s -> %s" % (trains['start_time'], trains['arrive_time'])
+ Fore.RESET, trains['lishi'], trains['zy_num'], trains['ze_num'],
trains['rw_num'], trains['yw_num'], trains['yz_num'], trains['wz_num']])
return ptable
3.4显示结果
最后,我们将上述过程进行汇总并将结果输出到屏幕上:
from docopt import docopt
from stations import stations
from get_data import GetData
import formats
def cli():
arguments = docopt(__doc__)
from_station =stations.get(arguments[''])
to_station = stations.get(arguments[''])
date = arguments['']
options = ''.join([
key for key, value in arguments.items() if value is True
])
data = GetData(date, from_station, to_station)
result = data.request_12306()
if result['httpstatus'] == 200 and result.get('data') is not None and result.get('data') != '':
format_result = formats.Formats(result.get('data'), options)
return format_result.format_data()
else:
return result['messages']
if __name__ == '__main__':
print(cli())
四、总结
本课程使用Python3抓取12306网站信息提供一个命令行的火车票查询工具。通过该项目的实现,可以学习实践Python3基础及网络编程,以及docopt,request,prettytable等使用。