原文连接:https://arxiv.org/pdf/1810.04826.pdf
结果连接: https://google.github.io/speaker-id/publications/VoiceFilter
摘要
在这篇文章中,我们提出了一个通过参考音频实现音频分离的系统。我们通过两个独立的网络来实现这个目的。(1)声纹识别网络用于生成离散的发音者特征。(2)谱掩码网络:通过输入说话者特征和噪声谱,生成一个谱掩码。我们的系统显著降低了语音识别在多人混杂 语音上的词错误率,在单人干净语音上的词错误率也不会升高。
关键字:语音分离、声纹识别、谱掩码、语音识别
1 简介
最近语音识别研究在一些具有挑战性的场景下,例如:远场识别、噪声环境识别上都有了很大进展。但是在人群环境下的语音识别,还是表现很差。
一种解决方法是引入语音分离系统。因此,拥有N个说话人的语料将被分离成N对应的输出。但是,这个方法有两个难点,一个是使用场景中人数的确定,另一个是只能针对训练集的特定说话人进行分离。针对这两个问题,已经有一些好的解决方法被提出了。例如基于深度学习的聚类模型,吸引子模型和不变量置换训练方法等。
这个研究的价值在于从一个交流对话及噪声中抽取出感兴趣的音频集合。这些场景有:一个说话者对设备的提问集合,或者一个家庭的共用录音设备。我们假设说话者可以通过之前的注册音频进行单独的表示。这有点类似传统的音频分离,但是这个是基于说话者的。这篇文章将会介绍一个基于说话者分离的音频过滤器。对于音频过滤器,一些已有的研究可能不是很适合,除了上面讲到的两个难点外,还有就是需要对输出的N人进行匹配运算,即寻找最接近感兴趣的人的声音,这可能会用到挑选最大发音者、说话者验证、关键词匹配等技术。
另一种更加端对端的技术是把这个问题当成二分类问题,即感兴趣的人为正类,其他音频为负类。这样也能解决上述的三个问题:说话者人数问题、置换问题、说话者挑选问题。在本研究中,我们的目的在于实现一个参考音频作为参考条件的系统。我们首先训练一个基于LSTM网络的说话者编码器。然后我们训练一个时间维度掩码的网络,它有两个输入,一个是编码器输出的说话者特征,一个是带噪声的多人对话音频。这个系统训练后是为了移除不相关人员的音频,只保留感兴趣人员的音频。只要轮换参考音频,这个系统就能够提取多个不同人的音频。
存在一些相似的语音过滤的研究。例如【4,5】,作者通过嘴唇动作进行语音分离。但是,这个就需要同时用到嘴唇视频信息和语音信息。一个参考音频可能会更加适用于实际情况。【6,7】使用了一种引入说话者特征表示(One hot向量)的方法,但是这个对于训练集外的人就无能为力了。相反的,我们的系统能够轻易的生成未知说话者的特征表示,并且 具有业内最低的错误率。我们也证明了我们的系统在干扰噪声下对于ASR系统的性能提升。
本篇文章结构如下:第二章介绍实现方案并且详细介绍训练细节。第三章介绍实验设置,包括数据及指标。第四章将讲诉实验结果。第五章进行总结及展望。
2 方案
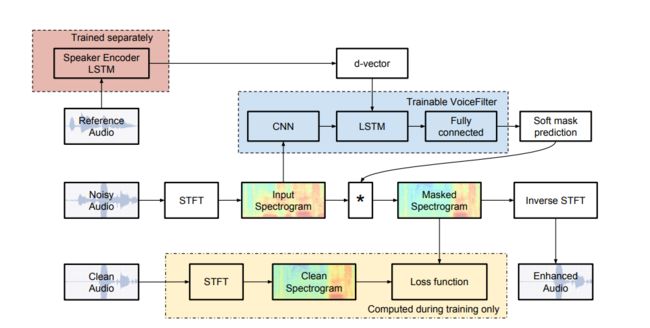
系统结构如图1所示,包括两个独立训练模块:(1)声纹识别模块(红色)。(2)声音过滤模块(蓝色),这个模块需要声纹识别模块的输出作为条件。下面进行具体介绍。
2.1 说话者编码模块
说话者编码模块的目的在于从一段目标说话者的音频中生成说话者身份表示特征。这个是基于【8】的研究,一个基于文本或文本独立的说话者身份验证研究。还有就是【9,10】关于说话者二值化的研究,和【11】多人语音合成的研究。
说话者编码用的网络是一个三层LSTM网络加GEE损失【8】。输入为1600ms的音频对数mel谱,输出为说话者表示向量,称为d-vector。表示向量宽度为256。我们从一句话中提取d-vector,滑动窗口大小为50%重叠,最后的结果是3个d-vector进行L2正则化结果的平均值。
2.2 音频过滤系统
语音过滤系统是基于 【12】的关于语音增强的研究。如图1所示,该网络有两个输入:d-vector和噪声音频的幅度谱。该网络生成一个软掩码,用于乘以噪声幅度谱从而生成一个增强的幅度谱。为了得到增强音频,我们直接将噪声音频的相位增加到增强幅度谱上,然后用ISTFT方法得到增强音频。
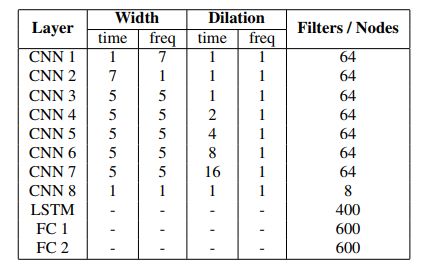
音频过滤网络由8个卷积层,1个LSTM层,两个全连接层组成,除了最后一层的激活函数是Sigmoid外,其余层的激活函数都是ReLU,具体参数由表1给出。d-vector在时间维度进行重复然后与卷积层的输出进行拼接。然后将拼接后的结果作为LSTM层的输入。把d-vector放在LSTM层前而不是卷积层前有两个原因。首先,d-vector已经具有很好的鲁棒性去表达一个说话人,没必要加卷积去改变它。其次,卷积层的假设为时间和频率上的对齐,因此不能把两个完全不同的信号量:即d-vector和幅度谱作为卷积层的输入。
在训练前,音频文件被剪切成3秒长的音频,并转化为16KHz单声道,然后再进行转频谱操作。
3 实验设置
这部分我们介绍实验设置,包括用于训练两个独立模块的数据介绍及系统评估方法。
3 .1 数据
3.1.1 数据集
Speaker Encoder网络: 虽然使用的网络结构和【8】形容的一致,但是我们用了更多的数据进行模型训练。我们用了两个数据集的数据,并且用到了【8】中提到的多说话者训练技巧。一份由匿名查询语句组成,包括手机音频和远场音频,包括138 000(十三万八千)人 的 34 000 000(三千四百万)句 话。第二份数据由LibriSpeech【13】,VoxCeleb【14】,VoxCeleb2 【15】组成。这个模型的错误率在我们内部手机测试的错误率为3.06%。文章【8】中提到的错误率为3.55%。
VoiceFilter网络:我们用两个数据集去训练和评估我们的模型,分别是VCTK数据集和LibriSpeech数据集。VCTK数据集我们随机抽取99个人作为训练集,另外10个作为测试集。LibriSpeech则用它定义的训练集总共2338人作为训练集,开发集73人作为测试集,这两个数据集包含说话音频,但是每句话都是一个说话人,我们后面会介绍如何构造数据去训练模型。
3.1.2 数据构造
从前文我们知道,我们的系统共有三个输入,(1)干净的原始音频。(2)混合噪声音频。(3)参考音频,用于计算d-vector。
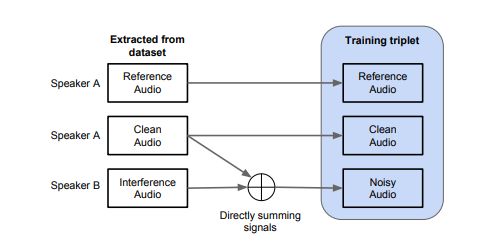
根据图2的方法,我们可以从一个干净数据集中构造三元数据集。参考音频为目标说话人的一句干净音频外的随机音频,噪声音频是干净音频和另一个人的音频进行混合的结果。确切的说就是将干净音频与另外一个音频进行叠加,然后切成和干净音频一个长度。
我们也尝试过给音频乘以[0,1]和[0,2]之间的随机因子,但是结果显示,这对于我们的系统并没有什么影响。
3.2 评估
对于不同的音频过滤模型,我们用两种方法进行评估。(1)词错误率(WER)。(2)Source to distortion ratio(SDR)。
正如第一章所描述的那样,我们这个系统的研究目标就是提供语音识别的正确率。特别的,我们希望能够降低多人说话录音场景下的语音识别率,同时也能保证单人说话时的语音识别率。我们所用的语音识别模型是【17】所述的一个传统音素模型,它的训练语料来自Youtube。
对于各个音频过滤模型,我们关心四个WER数据:
(1)干净音频的WER,没有加音频过滤器时,干净音频的WER。
(2)噪声音频的WER,没有加音频过滤器时,噪声音频的WER。
(3)加音频过滤器后,干净音频的WER。
(4)加音频过滤器后,噪声音频的WER。
第四个指标比第二个低,说明多人录音场景下,音频过滤器有作用。第三个结果接近第一个,说明音频过滤器对单人说话录音干扰小。
4 结果
4.1 词错误率(WER)
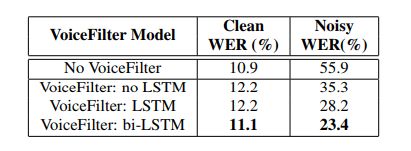
表2展示了模型在LibriSpeech数据集上的词错误率结果。结果展示了对于不同LSTM结构,模型的效果。(1)没有LSTM层,(2)单向LSTM。(3)双向LSTM层。从表中可以看出,WER在噪声数据集上明显降低,同时,在干净数据集上,WER提升不大。(1)和(2)的结果有明显的差异,说明LSTM在我们系统中的重要性,另外,结果也显示,双向LSTM的效果好于单向LSTM网络,我们在实验时,双向LSTM网络取得了最好的效果。在这个实验中,噪声数据的WER比原来的降低了大概58.1%。干净音频的WER则由10.9%变成了11.1%。
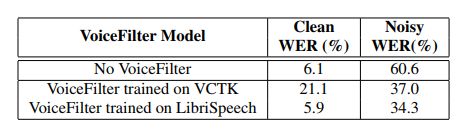
表3展示了模型在VCTK数据集上的测试结果。从结果可以看出,噪声数据的WER明显降低了,降低了差不多相对38.9%。然而,干净音频的WER却明显上升了。这可能是由于VCTK数据集太小了,训练集只有99人。如果我们用LibriSpeech数据集训练的模型进行测试,可以看到,噪声数据的WER更小了,甚至干净音频的WER也减小了。这可以说明:(1)音频过滤模型可以跨数据使用;(2)我们提升了干净音频的质量,即使我们没有明确的去训练它。
根据表3,知道了LibriSpeech数据集和VCTK数据集最大的不同在于数据量的不同(差不多20倍),我们可以通过增加训练集说话人数的方法来提升我们的模型。
4.2 Source to distortion ratio
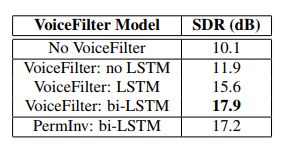
表4展示了模型的失真度,这个结果与表2结果由相似的趋势。双向LSTM获得了最高的SDR得分。
在表4中,我们还提供了使用置换不变损失的盲源分离模型的SDR【3】。当使用双向LSTM时,两个结果相近。
4.3 讨论
在表2中,我们使用了不同结构的网络用于训练LibriSpeech数据集,并且在双向LSTM模型上取得了最佳结果。好像可以得到这样的结果,我们可以通过增加网络的层数,或者增加双向LSTM层的节点数码来提高精度。为来的工作包括采用更多的变量和调整超参数以得到更好效果,同时,减小计算量。但这些都不是这篇文章研究的内容。
5 总结和展望
在这篇文章里,我们证明了以声纹识别模型为前提进行音频分离的有效性。这个系统在现实中应该更具有意义,因为它不需要知道说话人数,及其顺序。我们已经验证了在LibriSpeech上训练的模型,在二人混杂音频情况下的WER由55.9%下降到了23.%。同时,在干净音频下的WER基本保持不变。
这个模型可以通过以下方法进行改进:(1)在更加具有挑战性的数据集上进行训练,例如VoxCeleb 1
and 2 【15】.(2)增加训练人数。(3)使用多人参考音频生成d-vector而不是一个。另外一个有趣的方向是使用系统同时实现语音分离和语音增强。为此,我们可以在混合音频时加入各种噪声。这可能是未来研究的方向。另外,这个系统可以协同语音识别进行训练,以降低WER。
6 致谢
略
7 参考文档
[1] John R Hershey, Zhuo Chen, Jonathan Le Roux, and Shinji
Watanabe, “Deep clustering: Discriminative embeddings for
segmentation and separation,” in International Conference
on Acoustics, Speech and Signal Processing (ICASSP). IEEE,
2016, pp. 31–35.
[2] Zhuo Chen, Yi Luo, and Nima Mesgarani, “Deep attractor network
for single-microphone speaker separation,” in International
Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, 2017.
[3] Dong Yu, Morten Kolbæk, Zheng-Hua Tan, and Jesper Jensen,
“Permutation invariant training of deep models for speakerindependent
multi-talker speech separation,” in International
Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, 2017, pp. 241–245.
[4] Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson,
Avinatan Hassidim, William T Freeman, and Michael Rubinstein,
“Looking to listen at the cocktail party: A speakerindependent
audio-visual model for speech separation,” arXiv
preprint arXiv:1804.03619, 2018.
[5] Triantafyllos Afouras, Joon Son Chung, and Andrew Zisserman,
“The conversation: Deep audio-visual speech enhancement,”
arXiv preprint arXiv:1804.04121, 2018.
[6] Katerina Zmolikova, Marc Delcroix, Keisuke Kinoshita,
Takuya Higuchi, Atsunori Ogawa, and Tomohiro Nakatani,
“Speaker-aware neural network based beamformer for speaker
extraction in speech mixtures,” in Interspeech, 2017.
[7] Jun Wang, Jie Chen, Dan Su, Lianwu Chen, Meng Yu, Yanmin
Qian, and Dong Yu, “Deep extractor network for target speaker
recovery from single channel speech mixtures,” arXiv preprint
arXiv:1807.08974, 2018.
[8] Li Wan, Quan Wang, Alan Papir, and Ignacio Lopez Moreno,
“Generalized end-to-end loss for speaker verification,” in International
Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, 2018, pp. 4879–4883.
[9] Quan Wang, Carlton Downey, Li Wan, Philip Andrew Mansfield,
and Ignacio Lopz Moreno, “Speaker diarization with
lstm,” in International Conference on Acoustics, Speech and
Signal Processing (ICASSP). IEEE, 2018, pp. 5239–5243.
[10] Aonan Zhang, Quan Wang, Zhenyao Zhu, John Paisley, and
Chong Wang, “Fully supervised speaker diarization,” arXiv
preprint arXiv:1810.04719, 2018.
[11] Ye Jia, Yu Zhang, Ron J Weiss, Quan Wang, Jonathan Shen,
Fei Ren, Zhifeng Chen, Patrick Nguyen, Ruoming Pang, Ignacio
Lopez Moreno, et al., “Transfer learning from speaker verification
to multispeaker text-to-speech synthesis,” in Conference
on Neural Information Processing Systems (NIPS), 2018.
[12] Kevin Wilson, Michael Chinen, Jeremy Thorpe, Brian Patton,
John Hershey, Rif A. Saurous, Jan Skoglund, and Richard F.
Lyon, “Exploring tradeoffs in models for low-latency speech
enhancement,” in International Workshop on Acoustic Signal
Enhancement (iWAENC), 2018.
[13] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev
Khudanpur, “Librispeech: an asr corpus based on public domain
audio books,” in International Conference on Acoustics,
Speech and Signal Processing (ICASSP). IEEE, 2015, pp.
5206–5210.
[14] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman,
“Voxceleb: a large-scale speaker identification dataset,” arXiv
preprint arXiv:1706.08612, 2017.
[15] Joon Son Chung, Arsha Nagrani, and Andrew Zisserman,
“Voxceleb2: Deep speaker recognition,” arXiv preprint
arXiv:1806.05622, 2018.
[16] Christophe Veaux, Junichi Yamagishi, Kirsten MacDonald,
et al., “Superseded-cstr vctk corpus: English multi-speaker
corpus for cstr voice cloning toolkit,” 2016.
[17] Hagen Soltau, Hank Liao, and Hasim Sak, “Neural speech
recognizer: Acoustic-to-word lstm model for large vocabulary
speech recognition,” arXiv preprint arXiv:1610.09975, 2016.
[18] Emmanuel Vincent, Remi Gribonval, and C ´ edric F ´ evotte, ´
“Performance measurement in blind audio source separation,”
IEEE transactions on audio, speech, and language processing,
vol. 14, no. 4, pp. 1462–1469, 2006.