觉得可以的话,点个赞呀!
分析目的:本次分析将针对母婴类产品,根据市场销售数据分析需求,确定产品,指导上新。
本文使用python进行分析。并提出了自己的一些想法。
数据来源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=45
数据解释:
user_id:用户ID
birthday:出生日期
gender:性别:0男,1女,2未知
auction_id:交易id
cat_id:产品id
property:商品属性
buy_mount:购买数量
cat1:根商品类目
day:成交日期
分析步骤包括:
(1)定类目
各类目母婴产品销量比较
各类目母婴产品ID数量比较
(2)定产品
- 选定类目产品销售量比较
(3)上新筹备
上新时间:分析母婴产品年度销售趋势
产品卖点:分析母婴产品成交记录中高频关键词
消费者画像:消费者年龄、消费者性别比(儿童基本信息)
首先相关模块和数据导入:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
data_history = pd.read_csv('mum_baby_trade_history.csv')
data_info = pd.read_csv('mum_baby.csv')
前期处理
#两个表格的时间处理
data_info['birthday'] = pd.to_datetime(data_info['birthday'],format='%Y%m%d',errors='ignore')
data_history['day'] = pd.to_datetime(data_history['day'], format='%Y%m%d', errors='ignore')
#两个表格关联(只保留有儿童信息的部分)
data_all = pd.merge(data_history,data_info,on='user_id',how='right')
#时间处理
data_all['year'] = pd.DatetimeIndex(data_all['day']).year
data_all['quarter'] = pd.DatetimeIndex(data_all['day']).quarter
#儿童年龄计算
data_all['age'] = ((data_all['day'] - data_all['birthday']).dt.days)/356
1 定类目
(1)各类目购买总量
异常值分析
plt.scatter(range(len(data_all)),data_all['buy_mount'],alpha=0.5)

有一个产品在某日的购买量特别大,由于购买量几乎都分布在40以下,考虑这个点为异常点。去除
(2)每年的销售量和购买人数分析
data_all = data_all[data_all['buy_mount']<50]
year = [2012,2013,2014,2015]
buymount_sum = pd.DataFrame(columns=[2012,2013,2014,2015])
cat1_customer_sum= pd.DataFrame(columns=[2012,2013,2014,2015])
for i in year:
buymount_sum.loc[:,i] = data_all[data_all['year']==i].groupby('cat1')['buy_mount'].sum()
#各类目购买人数
cat1_customer_sum.loc[:,i] = data_all[data_all['year']==i].groupby('cat1')['cat_id'].count()
buymount_sum.plot(kind='bar',alpha=0.5,title='每年各类目销量')
cat1_customer_sum.plot(kind='bar',alpha=0.5,title='每年各类目购买人数')
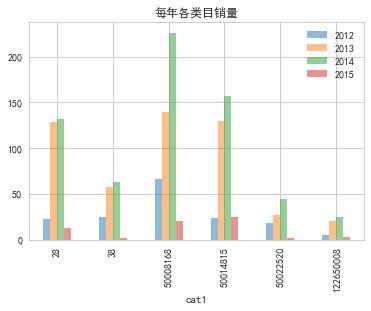

在各类目销量中,50008168一直保持着最佳销量位置,而且近一年来增长速度最快
同时该类目购买人数也是近几年增长最快的
(3)总销售量、总购买人数、竞品数量和平均购买量
各类目竞品数量
list1 = [50008168,50014815,28,50022520,122650008,38]
cat1_pro_sum = pd.DataFrame(index = list1,columns=['竞品数量'])
for i in list1:
cat1_pro_sum.loc[i,'竞品数量'] = (len(data_all[data_all['cat1']==i].groupby('cat_id').size()))
data2 = pd.concat([buymount_sum,cat1_customer_sum,cat1_pro_sum],axis=1)
data2.rename(columns={'buy_mount':'各类目购买总量','cat_id':'各类目购买人数'},inplace=True)
各类目每个人平均购买量
data2['平均购买量'] = data2['各类目购买总量']/data2['各类目购买人数']
data2.sort_values(by='各类目购买总量',ascending=False,inplace=True)
fig = plt.figure()
ax1 = fig.add_subplot(1,1,1)
ax2 = ax1.twinx()
data2[['各类目购买总量','各类目购买人数','竞品数量']].plot(kind='bar',alpha=0.5,title='各类目购买总量和平均购买量',ax=ax1,rot=0)
ax2.plot(range(len(data2)),data2['平均购买量'],color='r',alpha=0.5)
ax2.grid(False)

类目选择总结
(1)在各类目销量中,50008168一直保持着最佳销量位置,而且近一年来增长速度最快,同时该类目购买人数也是近几年增长最快的
(2)从整体来看类别50008168销量最高,而且购买人数最多,但是每个人的需求比较少;而类别50014815、28在销量上,人均需求上都差不多,这两类的优点是人均需求高
公司发展从稳的角度来看,选择50008168比较好
首先是50008168的竞品数目少,如果加入新的产品,竞争压力相对较小;
其次50008168人数需求和销量都很高,更像是生活必需品;
最后,从历年销量和客户人数来看,50008168近几年增速最快,发展前景好;
如果从想追求高利润的角度来看,类别50014815、28是不错的选择
因为这两类单客户购买量大,如果能够注意产品运营,增加产品新意和质量,
吸引客户,这两类产品将能够带来最大的效益
同时也可以考虑小规模上新类目38,该类目竞品最少,但是人均销量很高,如果能够对该类商品进行进一步的运营,有很大的发展空间
2 定产品
选定类目产品销售量比较(考虑类目50008168)
先看整体
pro_data = data_all[data_all['cat1']==50008168][['year','cat_id','buy_mount']]
pro_sum = pd.DataFrame(pro_data.groupby(['cat_id'])['buy_mount'].sum())
pro_sum.rename(columns={'buy_mount':'类50008168产品销量'},inplace=True)
分析整体产品销量大于20的产品
fig = plt.figure(figsize=(6,10))
ax1 = fig.add_subplot(2,1,1)
pro_sum[pro_sum['类50008168产品销量']>=30].sort_values(by='类50008168产品销量',ascending=False).plot(kind='bar',alpha=0.5,title='类50008168产品销量',ax=ax1,rot=1)
再看局部产品每年销量:50010558,50013636,50006602,50013207
pro_data2 = pro_data[(pro_data['cat_id'] == 50010558 ) |
(pro_data['cat_id'] == 50013636)|
(pro_data['cat_id'] == 50006602)|
(pro_data['cat_id']==50013207)]
pro_year = pro_data2.groupby(['cat_id','year'])['buy_mount'].sum()
ax2 = fig.add_subplot(2,1,2)
pro_year = pro_year.loc[:,[2012,2013,2014]]
pro_year[50010558].plot(kind='line',marker='o',color='r',alpha=0.8,label='50010558销量',ax=ax2)
pro_year[50013636].plot(kind='line',marker='o',color='b',alpha=0.8,label='50013636销量',ax=ax2)
pro_year[50006602].plot(kind='line',marker='o',color='g',alpha=0.8,label='50006602销量',ax=ax2)
pro_year[50013207].plot(kind='line',marker='o',color='y',alpha=0.8,label='50013207销量',ax=ax2)
plt.legend()

产品选择总结
从产品销售总量来看,产品50013636销售总额最多,其次是50006602
从每年产品销售量变化来看,各产品销售量都成逐年增长趋势,但是产品50013636增长有放缓趋势,而50006602销量增长趋势明显
由此可见是产品50013636有可能已经处于饱和状态
因此在产品选择时,建议选择产品50006602
3 上新筹备
上新时间:分析母婴产品每一年每季度销售趋势,确定合适的上新季度
产品卖点:分析母婴产品成交记录中高频关键词
消费者画像:消费者年龄、消费者性别比(儿童基本信息)
分析50006602产品
(1)分析母婴产品每季度销售趋势,确定合适的上新季度
fig = plt.figure(figsize=(6,15))
ax1 = fig.add_subplot(3,1,1)
pro_data3 = data_all[(data_all['cat_id'] == 50006602)&(data_all['year'] != 2015)]
pro_quarter = pd.DataFrame(pro_data3.groupby('quarter')['buy_mount'].sum())
pro_quarter.plot(kind='line', marker='o',alpha=0.5,title='每季度母婴产品销量',ax=ax1)
下图中可知在第三季度后开始上新比较好
(2)产品卖点分析:分析母婴产品成交记录中高频关键词
import re
property = pd.DataFrame()
pattern = re.compile(r'(\d+:\d+);?')
for i in range(len(pro_data3)):
property = property.append(pd.DataFrame(pattern.findall(pro_data3.iloc[i,4])))
property.rename(columns={0:'关键词'},inplace=True)
best_property = property['关键词'].value_counts()
选择最佳关键词大类是1628665,细分关键词可以设置为3233942、3233941等
(3)消费者画像分析
消费者年龄分段
ax2 = fig.add_subplot(3,1,2)
sns.distplot(pro_data3['age'],bins=10,kde=True,ax=ax2)
性别分布分析
male = len(pro_data3[pro_data3['gender']==0])/len(pro_data3)
female = len(pro_data3[pro_data3['gender']==1])/len(pro_data3)
unknow = len(pro_data3[pro_data3['gender']==2])/len(pro_data3)
labels = ['男','女','未知']
size = [male, female, unknow]
ax3 = fig.add_subplot(3,1,3)
ax3.pie(size,labels = labels, autopct='%.2f%%')
消费者人群中,年龄段主要分布在-1到2岁之间,性别中男孩占了多数

总结和建议:
(1)经分析类别50008168总销量最高,总购买人数最多,竞品压力小,近几年增速最快,发展前景好。
(2)产品50006602近几年销量增长趋势明显,销售前景良好;
(3)产品最佳上新时间为3月份。最佳关键词大类为1628665。受众年龄为-1-2岁,性别中男孩占多数。