本文主要用于梳理概率图模型~用于自我温习回顾基础~
基本目录如下:
基础知识
1.1 概率图模型的分类
1.2 生成模型与判别模型的区别
1.3 朴素贝叶斯与逻辑回归的关系概率图模型
2.1 贝叶斯网络
2.2 马尔可夫模型
2.3 马尔可夫网络
------------------第一菇 - 基础知识------------------
优雅的概率图模型是我最喜欢的机器学习模型之一~故特开一篇完整的记录一下与概率图模型有关的知识点嘿嘿~
在真实的业务场景中,我们希望能够挖掘隐含在数据中的知识,而概率图模型就构建了这样一幅图,用观测结点表示观测到的数据,用隐含结点表示潜在的知识,用边来描述知识与数据的相互关系,最后基于这样的关系图获得一个概率分布,从而解决问题~
1.1 概率图模型的分类
概率图中的节点分为隐含节点和观测节点,边分为有向边和无向边。从概率论的角度,节点对应于随机变量,边对应于随机变量的依赖或相关关系,其中有向边表示单向的依赖,无向边表示相互依赖关系。
因此,根据图模型的边是否有向,概率图模型通常被划分成有向概率图模型和无向概率图模型~其中,大家耳熟能详的贝叶斯网络就可以用一个有向图结构表示,马尔可夫网络可以表示成一个无向图网络结构~
而从纵横俩个纬度可以更加清晰地诠释,在自然语言处理中概率图模型的演变过程(如下图)
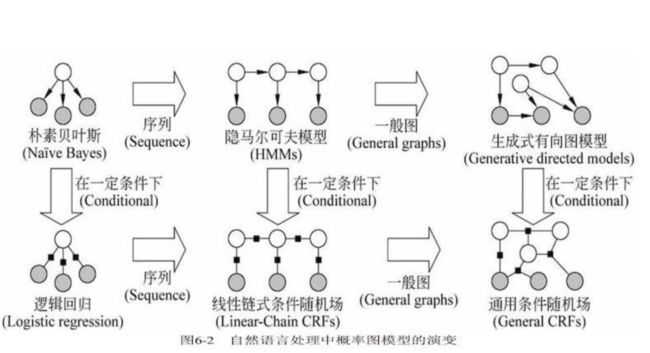
其中横向:由点到线(序列结构),到面(图结构)。以朴素贝叶斯为基础的HMM(隐马尔可夫模型)用于处理线性序列问题。以逻辑回归模型为基础的线性链式条件随机场用于解决“线式”序列问题。
而从纵向看,在一定条件下生成式模型转变为判别式模型,朴素贝叶斯模型演变为逻辑回归模型,HMM演变为Linear-Chain CRFs~
咋一看上去,若是对这些模型的原理没有深入的理解肯定是无法想明白的,因此在接下来的基础篇章,我将重点讲述一下2个点,即生成模型与判别模型区别的理解和朴素贝叶斯是如何演变为逻辑回归的~
1.2 生成模型与判别模型的区别
生成式模型与判别式模型的区别应该是机器学习基础中的基础~但是又有很少人能解释完整的解释清楚这个问题,本段就重点讲一下我自己和书上(《统计自然语言处理》)的理解~
简单来说,从字面意思上来看,生成模型重在 “生成” 二字,即该模型是能够生成数据的,而判别模型重在 “判别” 二字,即该模型只能够是用来判别区分数据的~这里举一个简单的例子,加深大家的理解。假如我们有一个业务场景是要去区分男女,那生成模型他要干的事情就是去分别记住男女各自的特征,比如男的有胡子啊,身高高之类的,女的皮肤好,身材苗条一些!之所以要记住男女各自的特征,是因为这是生成模型,他得把这些全记住,才能够根据男性绘出其特征(生成);而判别模型就比较直接,他要记住的只是男女之前的特征差异,比如是否有胡子,有的就是男的,没有就是女的!因此,其只有判别的功能而没有生成的功能!因此,从字面意义上,两者最大的区别就在于能否生成数据。
当然,上面讲的例子可能不恰当,还是要回归书本,看看专家的对俩者的定义。
生成模型与判别模型的本质区别在于模型中观测序列和状态序列之间的决定关系,前者假设决定,后者假设决定。
1.2.1 生成模型
生成模型以“状态(输出)序列按照一定的规律生成观测(输入)序列”为假设,针对联合分布进行建模,并且通过估计使生成概率最大的生成序列来获取。
生成式模型是所有变量的全概率模型,因此可以模拟“生成”所有变量的值。在这类模型中一般都有严格的独立性假设,特征是事先给定的,并且特征之间的关系直接体现在公式中。典型的代表有:HMM,朴素贝叶斯分类器。
1.2.2 判别模型
判别式模型则符合传统的模型分类思想,认为由决定,直接对后验概率进行建模,它从中提取特征,学习模型参数,使得条件概率符合一定形式的最优。
在这类模型中特征可以任意给定,一般特征是通过函数表示的,其优点就是处理多分类问题是比较灵活,容易建立和学习。但是其弱点就在于模型的描述能力有限,变量之间的关系就不清楚了哈哈~典型的代表有:SVM,CRF
1.3 朴素贝叶斯与逻辑回归的关系
这篇知乎的高亮答案应该说,把这个问题诠释的很清楚了~
https://www.zhihu.com/question/265995680
这篇博文,把俩者的区别比较也说的比较明白了~
https://www.cnblogs.com/wangkundentisy/p/9193217.html
------------------第二菇 - 贝叶斯网络------------------
2.1 贝叶斯网络
贝叶斯网络是一种基于概率推理的数学模型,其理论基础是贝叶斯公式,其目的是通过概率推理处理不确定性和不完整性问题。形式上来讲,一个贝叶斯网络就是一个有向无环图,结点表示随机变量,结点之间的有向边表示条件依存关系,箭头指向的结点依存于箭头发出的结点。若俩个结点没有连接,则表示俩个随机变量能够在某些特定情况下条件独立,而俩个结点有连接关系表示俩个随机变量在任何特定条件下都不存在条件独立。条件独立就是贝叶斯网络所依赖的一个核心概念!
以上都是《统计自然语言处理》第6章的原文。
接下来,实战演示一下,如何表示一个贝叶斯网络的联合概率分布。

如上图所示,在给定A的条件下,B和C是条件独立的,基于概率的定义可得,
同理可得,在给定B和C的条件下A和D是条件独立的,可得,
因此,其联合概率可以表示为,
2.2 马尔可夫模型
马尔可夫模型描述了一类重要的随机过程。我们常常需要考察一个随机变量序列,这些随机变量并不是相互独立的,每个随机变量的值依赖于这个序列前面的状态。如果一个系统有个有限状态,那么随着时间的推移,该系统将从某一状态转移到另一状态。为一个随机变量序列,随机变量的取值为状态值中的某个状态,假定在时间的状态记为,对该系统的描述通常需要给出当前时刻的状态和其前面所有状态的关系:系统在时间处于状态的概率取决于其在时间的状态,如果在特定条件下,系统在时间的状态只与其在时间的状态相关,即,
则该系统构成一个离散的一阶马尔可夫链。进一步,如果只考虑上式独立于时间的随机过程:
该随机过程为马尔可夫模型。其中,状态转移概率必须满足以下条件,
显然,有N个状态的一阶马尔可夫过程就有次状态转移,而其个状态转移概率可以表示成一个状态转移矩阵。
因此,根据上述的定义,结合之前的n元语法模型,想必不难看出,当的时候,其本质就是一个马尔可夫模型,不过当的时候,就不是一个马尔可夫模型了,因为其不符合马尔可夫模型的基本约束。
在马尔可夫模型中,每个状态代表了一个可观察到的事件,所以,马尔可夫模型有时又被称为可视马尔可夫模型,这在某种程度上限制了模型的适应性。因此,才有了隐马尔可夫模型(HMM),我们不知道模型所经过的状态序列,只知道状态的概率函数,也就是说,观察到的事件是状态的随机函数,因此,该模型是一个双重的随机过程,其中,模型的状态转换过程是不可观察的,即隐蔽的,可观察事件的随机过程是隐蔽的状态转换过程的随机函数。具体有关HMM的理解可以移步到另一篇详解HMM的,本文不作展开~
2.3 马尔可夫网络
马尔可夫网络与贝叶斯网络有类似之处,也可用于表示变量之间的依赖关系。但是,它又与贝叶斯网络有所不同,一方面,它可以表示贝叶斯网络无法表示的一些依赖关系,如循环依赖,另一方面,它不能表示贝叶斯网络能够表示的某些关系,如推导关系。
马尔可夫随机场(MRF)就是典型的马尔可夫网络,就是著名的无向图模型。图中每个结点表示一个或一组变量,结点之间的边表示两个变量之间的依赖关系。马尔可夫随机场有一组势函数,也称为“因子(factor)”,这是定义在变量子集上的非负实函数,主要用于定于概率分布函数。
以上都是《统计自然语言处理》第6章和《机器学习》第14章的原文。
接下来,实战演示一下,如何表示一个马尔可夫网络的联合概率分布。
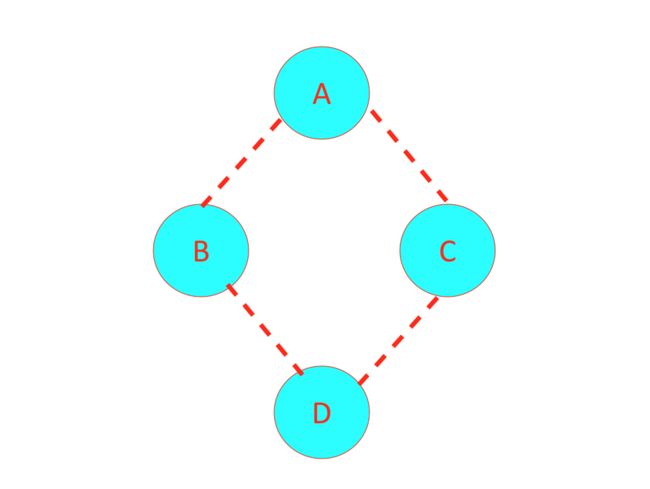
对于上图中结点的一个子集,若其中任意两结点间都有边连接,则称该结点子集为一个“团”,若在一个团中加入任何一个结点都不再形成团,则称该团为“极大团”,换言之,极大团就是不能被其他团所包含的团。根据上述定义,上图中就有4个团,且都是极大团,分别为:{A,B}, {A,C}, {B,D}, {C,D}
在马尔可夫随机场中,多个变量之间的联合概率分布能基于团分解为多个因子的乘积,每个因子仅与一个团有关。具体来说,对于个变量,所有团构成的集合为,与团对应的变量集合记为,则联合概率定义为,
其中,为与团对应的势函数,用于对团中的变量关系进行建模。
另外,为规范化因子,以确保是被正确定义的概率。在实际应用中,精确计算通常很困难,但许多任务往往并不需要获得的精确值。
值得注意的是,若变量个数较多,则团的数目将会很多,因此,一般我们定义的联合概率都是基于极大团的。因此,根据上述定义,我们可以得出,上图的联合概率可以定义为,
马尔可夫随机场中的势函数,其作用是定量刻画变量集中变量之间的相关关系,它应该是非负函数,且在所偏好的变量取值上有较大函数值。一般的,指数函数常被用于定义势函数,即,
其中,
其中的是参数,上式中的第二项仅考虑单结点,第一项则考虑每一对结点的关系。
马尔可夫随机场(MRF)就是典型的马尔可夫网络。然后在一定的条件前提下,也可以演变为条件随机场,另开文详解,本文不展开。
至此,涉及概率图模型中的一些核心概念已经全部回顾完成了~希望大家读完本文后对概率图的一些概念会有一个全新的认识。有说的不对的地方也请大家指出,多多交流,大家一起进步~
另如果看完本文对几个概念还是朦朦胧胧的,可以参考这篇博文,里面还有各自福利彩蛋哦~