网站挂马检测与清除
陈小兵
据不完全统计,
90%
的网站都被挂过马,挂马是指在获取网站或者网站服务器的部分或者全部权限后,在网页文件中插入一段恶意代码,这些恶意代码主要是一些包括
IE
等漏洞利用代码,用户访问被挂马的页面时,如果系统没有更新恶意代码中利用的漏洞补丁,则会执行恶意代码程序,进行盗号等危险超过。目前挂马主要是为了商业利益,有的挂马是为了赚取流量,有的是为了盗取游戏等账号,也有的是为了好玩,不管是处于那种目的,对于访问被挂马的网站来说都是一种潜在的威胁,影响运营网站公司形象。
当一个网站运营很长时间后,网站文件会非常多,手工查看网页文件代码非常困难,杀毒软件仅仅对恶意代码进行查杀,对网页***以及挂马程序不一定全部查杀,本文就如何利用一些安全检测工具软件来检测和清除网站***方面进行探讨,使用本文提及的工具可以很轻松的检测网站是否被挂马。
一、检测网页***程序
1.
安装
urlsnooper
软件
Urlsnooper
是一款
URL
嗅探工具,其官方主页地址为:
[url]http://www.donationcoder.com/urlsnooper[/url]
,安装非常简单,按照提示进行安装即可。第一次使用时需要程序会自动检查网卡,查看能否正常连接网络,设置正确无误后,应该出现如图
1
所示的画面。
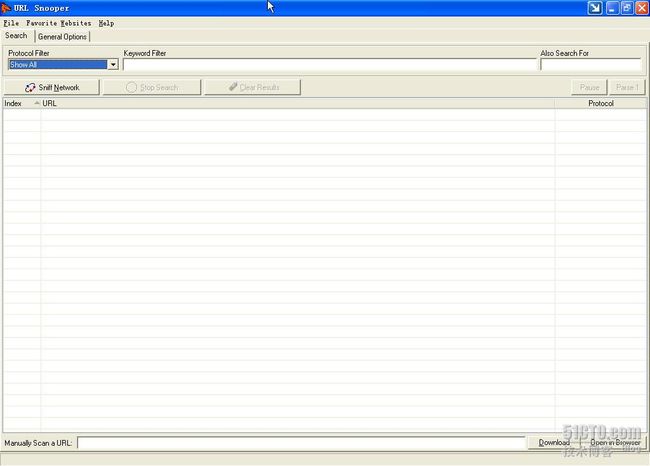
图
1
安装正确后的界面
注意:
如果未出现图
1
所示界面,说明程序设置存在问题,笔者在测试时使用发现该程序无法检测无线网卡,因此无法在无限网络中使用。
2.
对网站进行侦测
在
Urlsnooper
中的“
Protocol Filter
”中选择“
Show All
”,然后单击“
Sniff Network
”按钮开始监听网络。接着使用
IE
浏览器打开需要进行检测***的网站,
Urlsnooper
会自动抓取网站中的所有连接,在
Index
中按照五位数字序号进行排列,如图
2
所示。
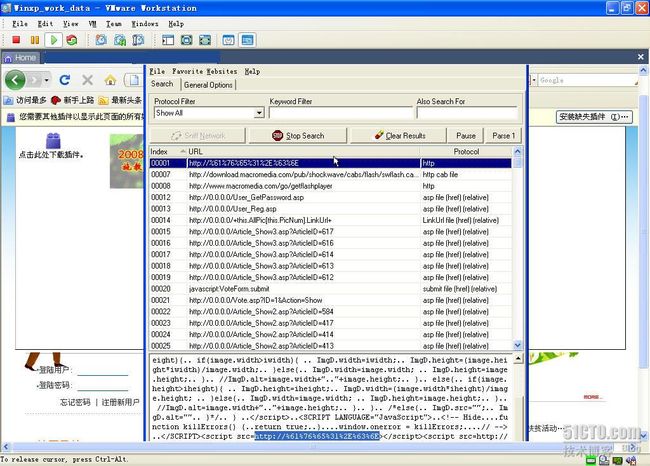
图
2
监听结果
说明:
在侦测结果中可能包含的连接地址非常多,这个时候就需要进行排查,可以选中每一个记录,
Urlsnooper
会在下方中显示详细的监听结果,如图
2
所示,就发现存在一段挂马代码:
在百度搜索中对其进行搜索,如图
3
所示,有
30
多项搜索结果,从查询结果可以辅佐证明该段代码为挂马代码。
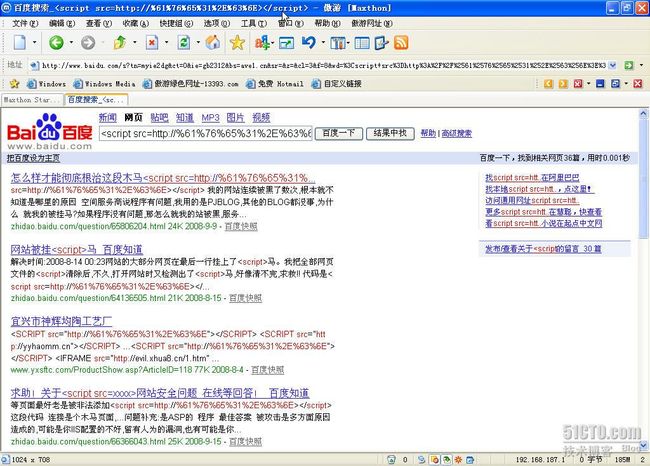
图
3
搜索结果
说明:要善于运用网络搜索引擎,通过搜索可以知道目前关于该问题的描述和解决方法等。
3.
对地址进行解码
该地址采用了一种编码,我对常用的这种编码值进行了整理,如下表所示,从中可以找出该代码中的真实地址为
[url]http://ave1.cn[/url]
。
表
1
编码对应表
|
原值
|
解码前的值
|
原值
|
解码前的值
|
原值
|
解码前的值
|
|
backspace
|
%08
|
I
|
%49
|
u
|
%75
|
|
tab
|
%09
|
J
|
% 4A
|
v
|
%76
|
|
linefeed
|
% 0A
|
K
|
%4B
|
w
|
%77
|
|
creturn
|
%0D
|
L
|
% 4C
|
x
|
%78
|
|
space
|
%20
|
M
|
%4D
|
y
|
%79
|
|
!
|
%21
|
N
|
%4E
|
z
|
% 7A
|
|
"
|
%22
|
O
|
% 4F
|
{
|
%7B
|
|
#
|
%23
|
P
|
%50
|
|
|
% 7C
|
|
$
|
%24
|
Q
|
%51
|
}
|
%7D
|
|
%
|
%25
|
R
|
%52
|
|
|
|
&
|
%26
|
S
|
%53
|
|
|
|
'
|
%27
|
T
|
%54
|
|
|
|
(
|
%28
|
U
|
%55
|
|
|
|
)
|
%29
|
V
|
%56
|
|
|
|
*
|
% 2A
|
W
|
%57
|
|
|
|
+
|
%2B
|
X
|
%58
|
|
|
|
,
|
% 2C
|
Y
|
%59
|
|
|
|
-
|
%2D
|
Z
|
% 5A
|
|
|
|
.
|
%2E
|
[
|
%5B
|
|
|
|
/
|
% 2F
|
\
|
% 5C
|
|
|
|
0
|
%30
|
]
|
%5D
|
|
|
|
1
|
%31
|
^
|
%5E
|
|
|
|
2
|
%32
|
_
|
% 5F
|
|
|
|
3
|
%33
|
`
|
%60
|
|
|
|
4
|
%34
|
a
|
%61
|
|
|
|
5
|
%35
|
b
|
%62
|
|
|
|
6
|
%36
|
c
|
%63
|
|
|
|
7
|
%37
|
d
|
%64
|
|
|
|
8
|
%38
|
e
|
%65
|
|
|
|
9
|
%39
|
f
|
%66
|
|
|
|
:
|
% 3A
|
g
|
%67
|
|
|
|
;
|
%3B
|
h
|
%68
|
|
|
|
<
|
% 3C
|
i
|
%69
|
|
|
|
=
|
%3D
|
j
|
% 6A
|
|
|
|
>
|
%3E
|
k
|
%6B
|
|
|
|
?
|
% 3F
|
l
|
% 6C
|
|
|
|
@
|
%40
|
m
|
%6D
|
|
|
|
A
|
%41
|
n
|
%6E
|
|
|
|
B
|
%42
|
o
|
% 6F
|
|
|
|
C
|
%43
|
p
|
%70
|
|
|
|
D
|
%44
|
q
|
%71
|
|
|
|
E
|
%45
|
r
|
%72
|
|
|
|
F
|
%46
|
s
|
%73
|
|
|
|
G
|
%47
|
t
|
%74
|
|
|
|
H
|
%48
|
u
|
%75
|
|
|
4.
获取该网站相关内容
可以使用
Flashget
的资源管理器去获取该网站的内容,如图
4
所示,打开
Flashget
下载工具,单击“工具”
-
“站点资源探索器”,打开站点资源探索器,在地址中输入“
[url]http://ave1.cn[/url]
”,然后回车即可获取该网站的一些资源,在站点资源探索器中可以直接下载看见的文件,下载到本地进行查看。
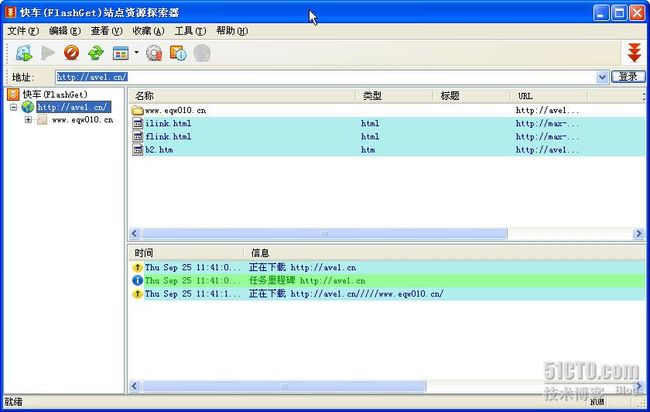
图
4
使用“站点资源探索器”获取站点资源
说明:
使用“
Flashget
站点资源探索器”可以很方便的获取挂马者代码地址中的一些资源,这些资源可能是挂马的真实代码,透过这些代码可以知道挂马者是采用哪个漏洞,有时候还可以获取
0day
。
在本例中由于时间较长,挂马者已经撤销了原来的挂马程序文件,在该网站中获取的
html
文件没有用处,且有些文件已经不存在了,无法对原代码文件进行分析。
二、清除网站中的恶意代码(挂马代码)
1.
确定挂马文件
清除网站恶意代码首先需要知道哪些文件被挂马了,判断方法有三个,方法一就是通过直接查看代码,从中找出挂马代码;方法二是通过查看网站目录修改时间,通过时间进行判断;方法三使用本文提到的软件进行直接定位,通过监听找出恶意代码。在本案例中,网站首页是被确认挂马了,通过查看时间知道被挂马时间是
8
月
25
日
左右,因此可以通过使用资源管理器中的搜索功能,初步定位时间为
8
月
24
日
至
26
日,搜索这个时间范围修改或者产生的文件,如图
5
,图
6
所示,搜索出来几十个这个时间段的文件。
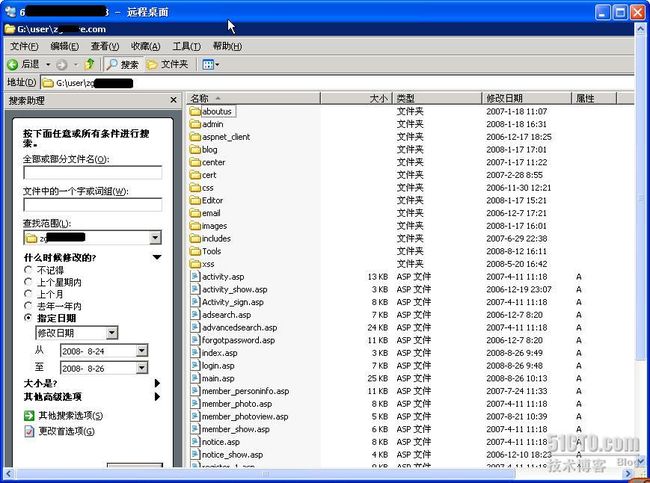
图
5
搜索被修改文件
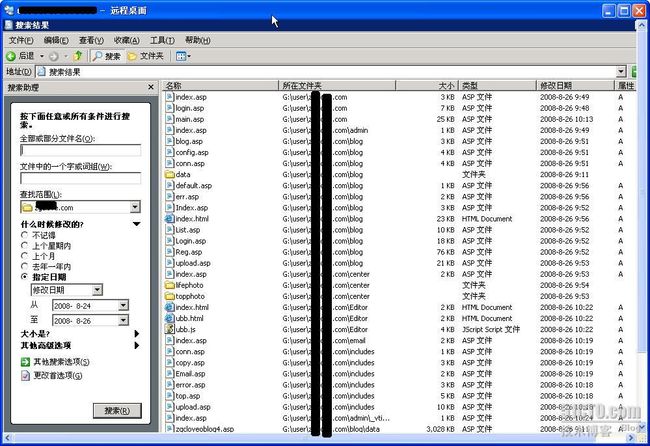
图
6
搜索结果
2.
清除恶意代码
可以使用记事本打开代码文件从中清除恶意代码,在清除代码时一定要注意不要使用
FrontPage
的预览或者设计,否则会直接访问挂马网站,感染***程序。建议使用记事本等文本编辑器。在清除恶意代码过程中,发现挂马者竟然对
js
文件也不放过,如图
7
所示。
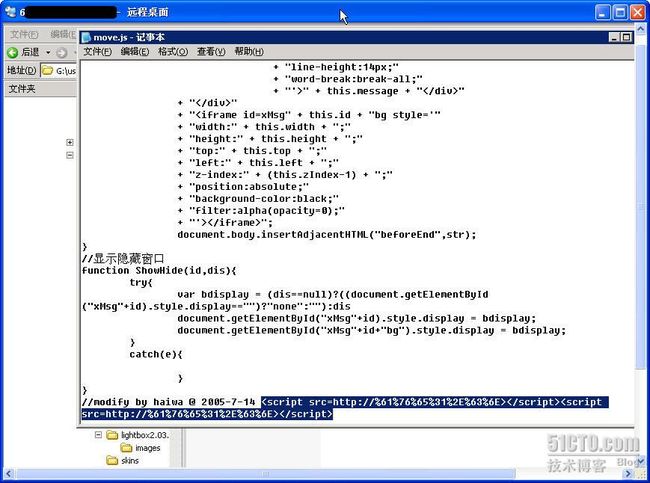
图
7
对
js
文件进行挂马
技巧:
可以使用
Frontpage
中的替换功能替换当前站点中的所有指定代码。
总结
本文操作简单,写起来比较复杂,关键在于使用
urlsnooper
软件定位挂马网页文件,然后就是对挂马代码(恶意代码)进行分析,最后是手工活,清除网站中的恶意代码。