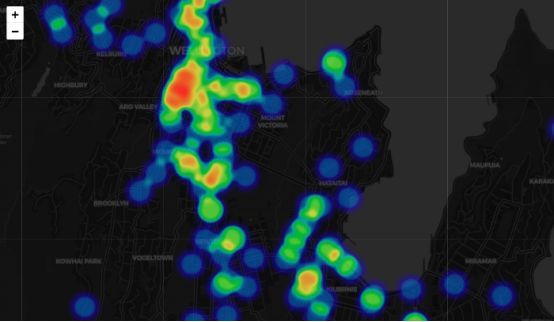
惠灵顿交通事故热感图
交通事故是世界各个社会都存在的重大问题。2010年,据世界卫生组织(WHO)估计,道路交通事故造成的死亡人数高达125万人。2016年,仅美国便有37461人死于机动车事故,平均每天死亡102人。同样在欧洲,根据2017年的数据显示,平均每分钟就有50人死于交通事故。那么机器学习能否帮助我们去了解影响交通事故严重性的原因和因素呢?
学习Python中有不明白推荐加入交流群
号:960410445
群里有志同道合的小伙伴,互帮互助,
群里有不错的视频学习教程和PDF!
本文将完整地展现一次机器学习的流水线:从APIs收集数据开始,到进行探索性数据分析,然后将一个现实生活中存在的问题构建到机器学习模型中。整个流程都是在Google Colab中完成的,使用它免费的GPU/TPU环境进行,你可以直接从Github打开Notebook在Google Colab中进行实验。

****收集数据****
你可以在不同的APIs中找到各种格式的交通事故分析系统(CAS)数据,很容易就可以通过API接口收集数据,而不用将它们下载到本地电脑中。这样有一个好处是,我们每次运行Jupyter Notebook时都能获取最新的数据。在这个流程中,我发现有一个特殊的问题,因为交通事故和地点(地理)紧密相关,所以在数据收集时,我们应该获取Geojson文件而不是一般的CSV文件,如此一来,在进行地理数据分析时就不用从经纬来创建几何图形,并且能够处理坐标基准系和投影。
随后可以使用Geopandas库来读取数据。如果你熟悉Pandas库,那么Geopnadas的使用应该也不在话下,因为它是建立在Pandas的基础上的工具。它是一个高级数据收集工具,可以使Python中的地理数据工作变得更加简单,它不仅具备Pandas的功能,还拥有能够在地理几何图形上进行空间运算在数据类型。得益于Pandas、Matplotlib以及几何图形的运算库,Geopandas能够完美地融入Python的生态系统。
Get the data from url and request it as json fileurl =
'https://opendata.arcgis.com/datasets/a163c5addf2c4b7f9079f08751bd2e1a_0.geojson'
geojson = requests.get(url).json()
Read the data as GeodataFrame in Geopandas
crs = {'init': 'epsg:3851'} # Coordinate reference system (CRS) for Newzealand
gdf = gpd.GeoDataFrame.from_features(geojson['features'], crs=crs)

****探索性数据分析****
在新西兰,从2000年至2018年,交通事故的死亡总人数为6922人。而事故中受重伤和轻伤的人数分别达到了45,044人和205,895人。然而这记录的只是在事故发生后上报了新西兰警方的数据,我们还要考虑那些未被记录在案的轻微交通事故。大多数的交通事故都是轻微、不致命的,而造成死亡的事故只占极少数。在死亡人数的统计上,大多数事故中的死亡率为0。
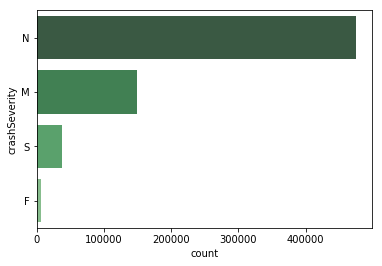
交通事故的严重等级
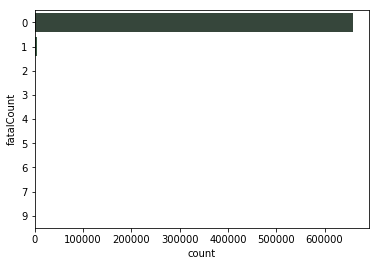
交通事故中的死亡人数
过去的几年中,整体数据表明事故的严重性和死亡人数在下降,但如下列折线图所示,从2016年开始事故死亡人数似乎有所上升。另外,在2017年事故重伤和轻伤人数达到了峰值。

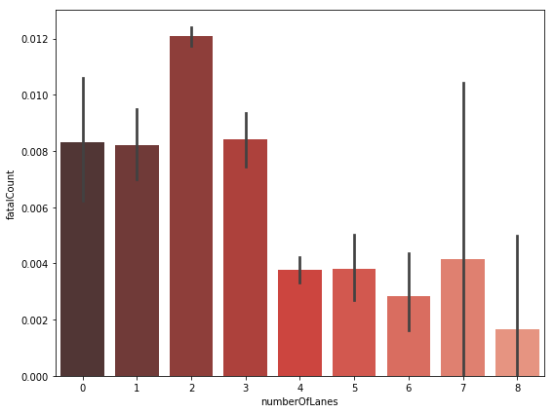
车道数量与事故死亡人数统计
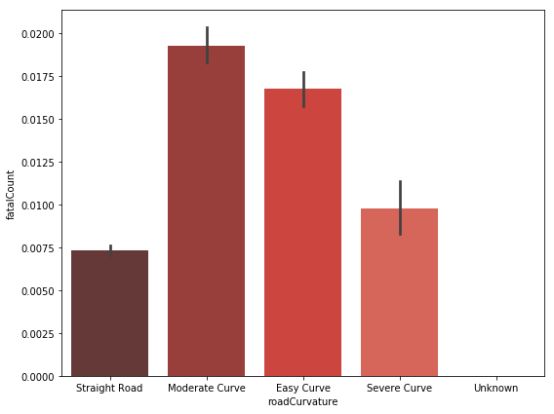
道路弯曲程度与死亡人数统计
道路以及其他相关因素同样可以展现事故的严重程度和死亡人数等级。让我们进一步挖掘他们之间的关系。在死亡人数和车道数量的关系中,比起其他的多车道,双车道所占的百分比最高。直路的交通事故死亡人数最少,大部分伤亡都出现在各种类型的弯路(小弯、中弯和大型弯道。)
让我们来看看交通法规和事故严重程度以及死亡人数的关系。其中,限速是一个很好的着手点。限速90km/h所占据的死亡人数最高,100km/h其次。
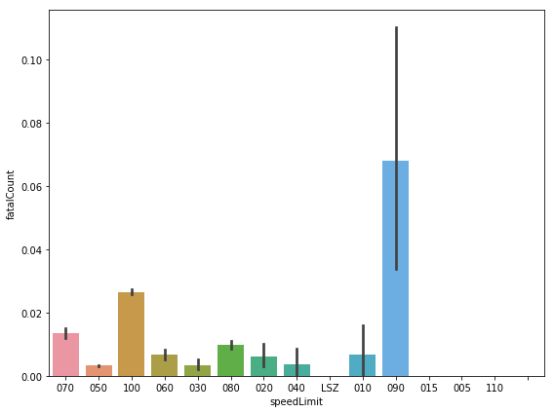
限速和死亡人数统计
分析天气因素后,同样发现雾天和强风天事故死亡人数的占比最高。雨天、雪天和霜冻天气同样也有较高的占比。
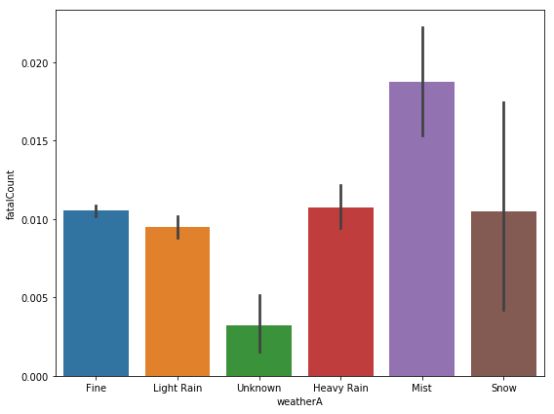
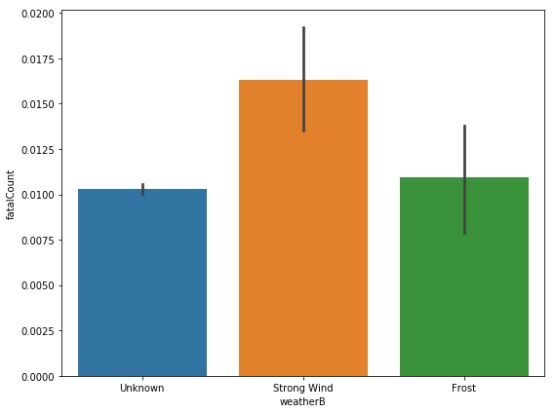
天气对交通事故死伤人数的影响

****地理数据探索****
下图所示的地理数据可视图清楚地显示事故发生的地点。如大家所料,大多数事故都发生在道路附近,尤其是城市里。
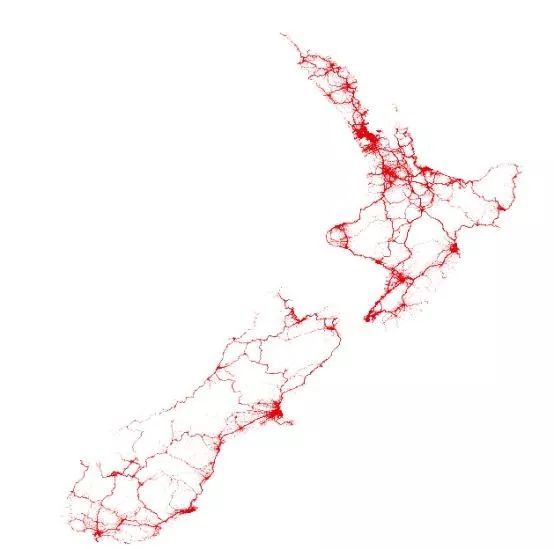
所有交通事故发生点
让我们来看看发生在奥克兰的交通事故总和的聚类图。
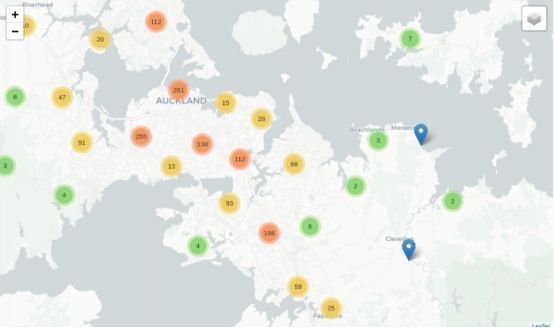
新西兰的奥克兰交通事故频发点

****机器学习****
我们可以通过不同方法对这个问题进行建模。把它看成回归问题,并基于交通事故成因的数据集推测死亡人数。也可以把它看作分类问题,并通过事故的数据集预测事故的严重程度。下面,我将以回归问题为例进行机器学习建模(你也可以尝试使用分类问题的方法,两个方法基本相同)。在这个例子中,我不会进行任何特征工程,我认为这个问题中的成因已经足够建立一个起点,随后可以再进一遍这个流程,并且通过特征工程来提高模型的精确度。
首先,需要将无序特征转化为数值可以使用Sklearn库来进行:
Label encoder
from sklearn.preprocessing import LabelEncoder
lblE = LabelEncoder()
for i in df:
if df[i].dtype == 'object':
lblE.fit(df[i])
df[i] = lblE.transform(df[i])
随后,将数据与训练和验证集分离为独立和非独立的变量,以便随后评估模型的结果。
Let us split our data into training and validation sets
X_train, X_test, y_train, y_test =
train_test_split(df.drop('fatalCount', axis=1), df.fatalCount,
test_size=0.33, random_state=42)
现在准备将机器学习模型运用到数据中。我通常从随机森林(Random Forest)开始,这是一个种利用多种分类树进行的算法,在应对有多个数据集的情况时非常有效。
m = RandomForestRegressor(n_estimators=50)
m.fit(X_train, y_train)
print_score(m)
Output:
RMSE Train:0.017368616661096157,
RMSE Valid:0.042981327685985046,
Accuracy Train: 0.977901052706869,
Accuracy Valid: 0.8636075084646185
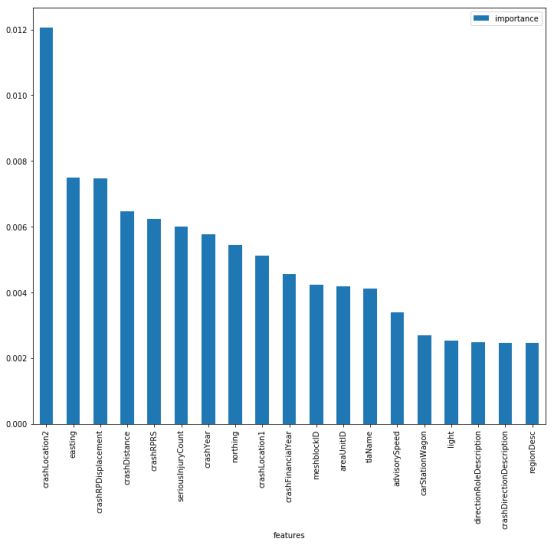
如你所见,随机森林模型在验证集上有高达86%的准确性,再进过一些初始的调整和特征选择后,此模型的精确度可以提高到87%。如果在模型上进行一些改善,创建新的特征或使用一些其他的算法来提高模型的执行力,还能到达更高的准确率。但现在,已经达到本文的目的了。下面是随机森林模型中最重要的特征。