Feature Pyramid Networks(FPN)
研究背景与摘要
Feature pyramids(特征金字塔)是传统多尺度目标识别系统的基本组成部分。但是最近的深度学习目标检测系统(R-CNN、Fast R-CNN 等),都避免了这种特征表示方式,部分原因是特征金字塔需要大量的计算和存储。
作者利用CNN固有的多尺度和金字塔层级结构,来构建特征金字塔表示。提出了一种具有横向连接的、自顶向下的结构(称为 FPN),用于在各种尺度上构建高级语义 feature maps。

- (a) 早期手工设计特征和传统目标检测方法多使用。在多尺度进行特征表示,所有的层级上的特征都具有明确的语义。但内存占用多,不能端到端训练。
- (b) CNN 即具有这种结构,CNN 相比人工设计特征,能够自己学习到更高级的语义特征,同时 CNN 对尺度变化鲁棒,因此如图,从单个尺度的输入计算的特征也能用来识别,但是遇到明显的多尺度目标检测时,还是需要金字塔结构来进一步提升准确率。 也可以(a)、(b)结合使用。
- (c) 从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。SSD 即利用了这种结构。作者认为SSD算法中没有用到足够低层的特征(在 SSD 中,最低层的特征是VGG网络的 conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
- (d) 利用CNN固有的多尺度和金字塔层级结构,顶层 feature map 通过上采样与底层feature map结合,融合为新的 feature map,最终形成 feature pyramid(特征图金字塔)。每层独立预测。实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时无明显的额外代价。
注意,FPN 是 CNN 框架的一个可选部件或者说可选操作,即它很可能会改善基本框架的性能,但不需要对基本框架进行较大的改动。
FPN 的技术细节
包括一条自底向上的通路,一条自顶向下的通路,和横向连接。
通过自顶向下的路径和横向连接将低分辨率、语义强的 feature map 与高分辨率、语义弱、更本地化(下采样次数少)的 feature map 结合起来,其结果是一个在所有层级都具有丰富语义的 feature pyramid。

自底向上
自底向上通路是指 backbone ConvNet (如 ResNet)的前向计算过程,它计算得到一种由若干尺度上的 feature map 组成的特征层次(金字塔)结构,每向上一层尺度缩小为 1/2。将特征金字塔的每一层称为一个 stage。ConvNet 通常有许多层生成相同大小的输出映射,我们说这些层处于相同的阶段(stage),只取 stage 的最后一层输出的 feature map,作为 feature pyramid 的参考集合。
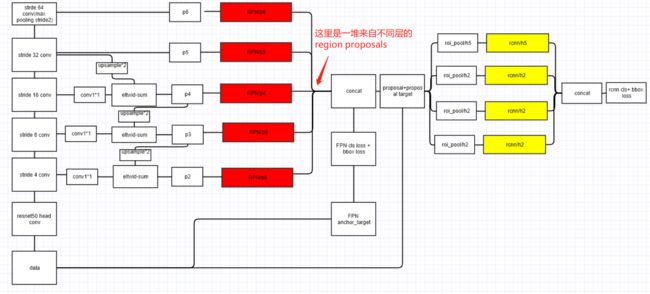
具体来说,对于 ResNets,我们使用每一个stage的最后一个 residual block 的激活后输出,作为 feature pyramid 的参考集合。我们conv2, conv3, conv4, and conv5 的输出分别表示为{C2, C3, C4, C5}。
note that they have strides of {4, 8, 16, 32} pixels with respect to the input image
自顶向下
自顶向下的路径是指,通过从更高的金字塔层次上,上采样空间上更粗糙但语义更强的 feature maps,从而产生更高分辨率的 feature maps。(为了简单起见,使用最近邻向上采样。)
横向连接
Pyramid 每一层的横向连接都将空间大小相同的(分别来自向上和向下通路的)feature maps 进行融合。
融合之后还会再采用 3×3 的卷积核,对每层的融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。
其中上行 feature map 会经过一个1x1卷积来减少 channel 维度(文中限制到 256d)。构造金字塔时没有引入额外的非线性。
融合后的 feature maps 称为 {P2, P3, P4, P5}
FPN + Faster R-CNN
本文将FPN简单地与 Faster R-CNN 结合,最小限度地修改了原网络,改善了原网络的性能。
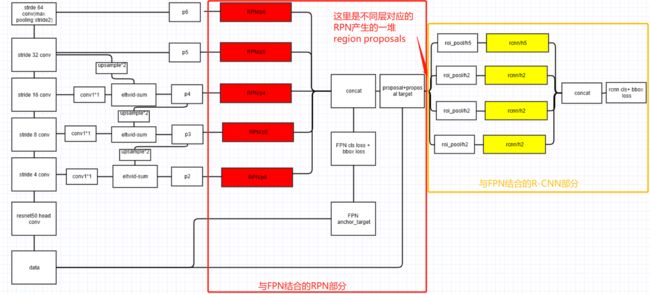
Faster R-CNN = RPN + Fast R-CNN,因此下文中介绍FPN应用于Faster R-CNN种时,RPN 和 Fast R-CNN 部分分别需要做的改动。
FPN for RPN
在每一个scale层,都定义了不同大小的anchor,对于 {P2,P3,P4,P5,P6},定义 anchor 的大小为 {},比例为,1:2,1:1,2:1。所以整个特征金字塔有15种 anchors。
注:
- 越高分辨率的 feature maps,采集的 region proposals 尺寸越小,这也对应了作者所称的,底层 feature map 对于小目标的检测更有用。大尺度的RoI要从低分辨率的 feature map 上切,有利于检测大目标,小尺度的RoI要从高分辨率的 feature map 上切,有利于检测小目标。;
- P6 仅仅是对 P5的max pooing下采样,是为了得到尺寸为 的 anchor,P6是只用在 RPN中用来得到region proposal的,并不会作为后续Fast RCNN的输入。这也是上图红色方块和黄色方块数目不一样的原因。
RPN 这部分的训练中,正负样本的界定和 Faster R-CNN 差不多:如果某个 region proposal 和一个给定的 ground truth 有最高的 IOU,或者和任一 ground truth 的IOU 都大于0.7,则是正样本。如果一个 anchor 和任意一个 ground truth的IOU都小于0.3,则为负样本。其他区间忽略。
FPN for Fast R-CNN
Fast R-CNN 通常是应用在单尺度feature map上。但为了与FPN结合,需要针对pyramid的不同层,设计 RoI Pooling Layer.
把feature pyramid看作是由一个图像金字塔产生的。不同尺度的RoI使用不同特征层作为ROI pooling层的输入,大尺度RoI就用相对高层的feature map,比如P5;小尺度RoI就用相对底层的feature map,比如P3。
因此,我们可以基于RoI对应的region proposal尺寸大小,判断使用哪一层对应的探测器。在形式上,我们将宽度为w,高度为h(在网络输入图像上)的RoI分配到feature pyramid的Pk级(k=2, 3, 4, 5)。
注意:
k0=4, 对应ImageNet标准的大小,对应C4/P4。
所有的pyramid levels共享预测头(类分类器和回归框,即上图黄色部分);feature pyramid所有的层级的RPN头(RPN中的3×3、1×1卷积)都共享参数。
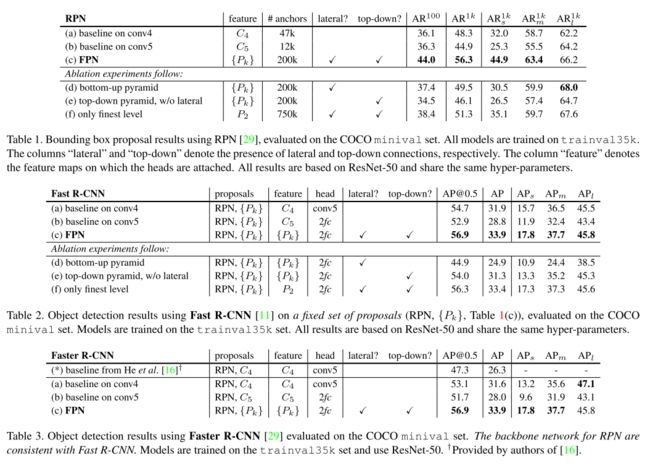
结果
参考资料
https://github.com/unsky/FPN
Feature Pyramid Networks for Object Detection 总结
FPN(feature pyramid networks)算法讲解
Mask R-CNN
研究背景与摘要
目标检测、语义分割与实例分割

Mask R-CNN 在 Faster R-CNN 目标检测任务的基础上,进一步实现了实例分割的功能。
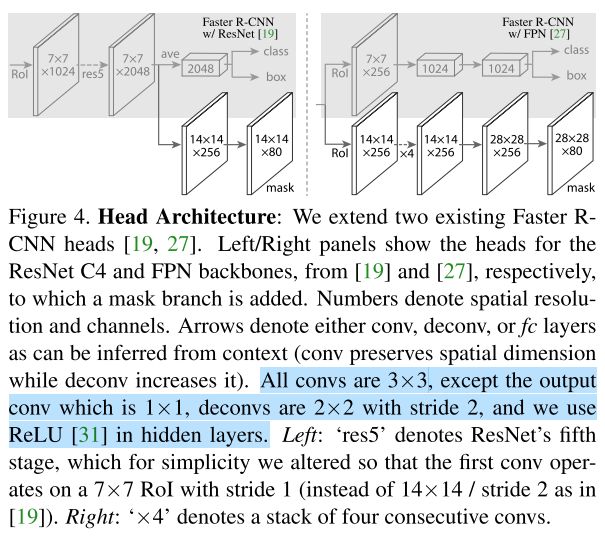
相比于原始 Faster R-CNN 论文中的结构(VGG),本文采用了 ResNet-C4、ResNet-FPN 结构提取 feature maps,并对比试验。(但这不属于Mask R-CNN 的特点)。
Mask R-CNN 的优点:
- 当时已有的实例分割方法中,多使用了不优雅的 trick ,本文只通过e2e的网络就完美完成任务;结合 Faster R-CNN 的 Mask RCNN 可以同时完成目标检测和实例分割,且实例分割效果优于当时已有方法;
- 易于实现和训练,基本与 Faster R-CNN 相同,只需针对 mask branch 作少许改动;
- 只比 Faster R-CNN 增加了一个很小的开销(检测速度 5 fps);
- 可以很方便地推广到其他任务中,如估计人体姿态、人体关键点估计。
技术细节
Architecture
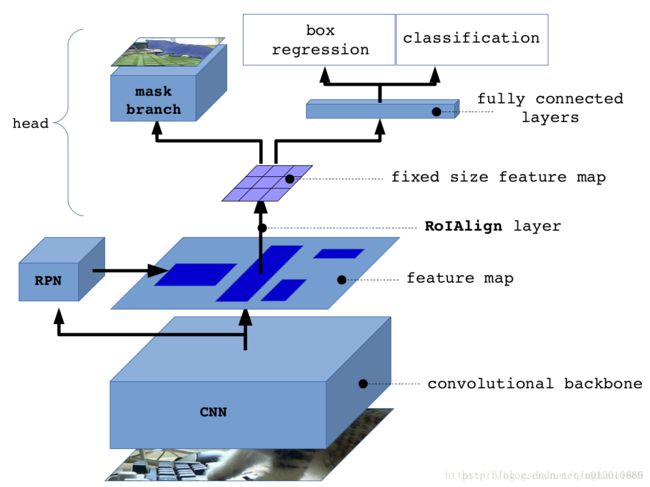
Mask R-CNN ≈ Mask branch + Fast R-CNN
Mask R-CNN 与 Faster R-CNN 结构上的区别,主要有两点:
- 将 RoIPool Layer 改为 RoIAlign Layer,用于实现输入与输出间,像素到像素的匹配;
- 在预测头处添加了一个Mask Branch,该分支与原有的 Bounding Box Recognition Branch 并行;
RoIAlign
尽管 Mask RCNN 是 Faster RCNN 的一种直觉上的拓展,似乎加上 Mask Branch 就万事大吉了。其实不然,要想得到好的结果,恰当地构造是至关重要的。
特别是分割任务中,需要做到输入与输出 pixel-to-pixel alignment;而在 Faster R-CNN 的设计中,没有考虑网络的输入和输出之间的像素与像素对应,尤其是 ROIPool 层。
ROIPool 层将空间粗略地划分,将原本连续的坐标离散化了。这导致了ROI和提取的特征在空间上不匹配。这可能对分类没有什么影响(分类对微小的变化鲁棒),但会严重影响 mask 的像素准确度。

为了修正这种像素不匹配,我们提出了一个简单的、无粗略量化的层,称为RoIAlign,它忠实地保留了精确的空间位置。在 mask 的精确性上,带来了10%-50%的收益。
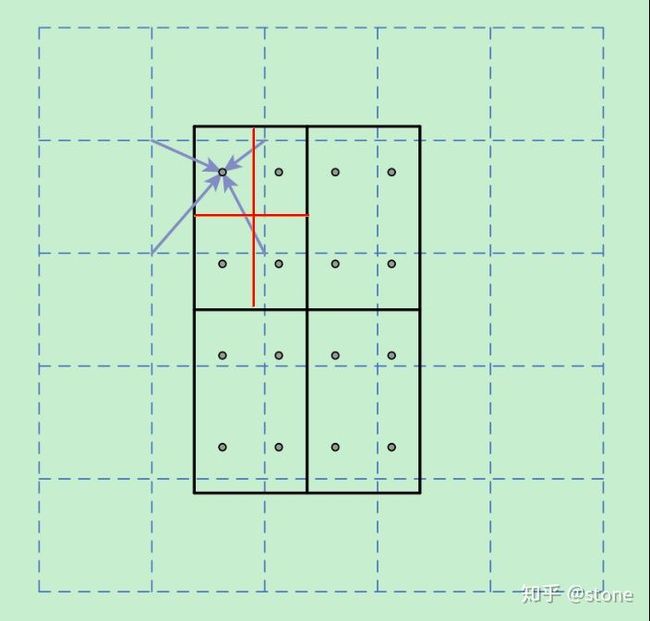
上图中,虚线部分表示f eature map,实线表示ROI,这里将ROI切分成2x2的单元格。如果采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要根据feature map的网格点,对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行 maxpooling 或 avgpooling,就可以得到最终的 ROIAlign 的结果。
在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
Mask Branch
Mask Branch 是一个小型 FCN,对于每个RoI,以 pixel-to-pixel 的方式预测输出出一个m×m×k的分割结果(但只取类别概率最高的一层作为最终输出mask)。
Loss & Decouple Mask and Class Prediction
具体来说,我们对每个ROI预测一个mxm的mask。
除了上文中提到的像素匹配问题,本文中实验发现,对 mask 和 class 的预测解耦是必要的:本文中,mask branch 根据 classification branch 输出的分类结果,针对每个class,独立地预测一个二元的mask,即类与类之间没有竞争。而普遍的应用 FCN 的分割网络,则是对每个像素利用 softmax 和多类别交叉熵损失。这样多各类别会互相竞争。
因此 Loss 定义为:
其中前两项与 Faster R-CNN 中相同。
:对于每个ROI,mask branch的输出维度是,即对于 K 个类别,分别预测一个 分辨率的 mask 输出。因此,我们逐个像素应用 sigmoid,定义为二类的交叉熵损失的平均值(average binary cross-entropy loss)。对于真实类别为 的RoI, 仅仅在第k类对应的 mask 上计算(其他的 mask 输出对 loss 没有贡献)。
如此定义 ,允许网络独立地对每个类别产生 mask(类别之间没有竞争)。本外另外使用专门的classification branch 来预测 class label,然后依据class label 选择输出的mask(即上文中的解耦)。实验证明,解耦是实例分割效果良好的关键。
Train
超参数与 FasterRCNN 相同。
每个图像调整短边至800像素。每个GPU的每个batch有2张图,每张图有N个RoI(N_C4=64, N_FPN=512),正负ROI比为1:3.
ROI 正负样本的定义与 Faster rcnn 相同,如果与Ground Truth 的IoU超过0.5认为是正样本,否则负样本。 和 只在正样本上计算。
可以采用阶段性训练,
Test
在测试过程中,proposal 数目为300 for C4, 1000 for FPN。
对这些 proposal 做 box prediction,然后进行非极大值抑制(有重叠部分的ROI,取class得分最大的作为输出),得到最终框的结果。
随后,mask branch 只对得分最高的100个检测框进行mask预测(而训练集上是所有的proposal并行计算损失的),这样可以提高效率,只增加较小的开销(约20%)。
mask branch针对每个RoI可以预测K个masks,对应K个类别。但我们只选用了第k个mask(即classification branch的预测结果)。

mask branch的输出将被resize(通过插值方式将输出的 mask 放大)成 proposal 的大小,然后以0.5为阈值二值化。
应用到人体关键点检测
将人体关键点的位置建模为一个单点的 mask,采用 Mask R-CNN预测 K 个 mask,每一个 mask 对应一个人体关键点(如左肩、右肘等)
相对于基本的mask rcnn,有微小的改动:
- 对于每一个 instance 的 K 个关键点,训练目标是一个 one-hot 的 m×m 的 mask,即每张 mask 只有一个 pixel 标记为前景;
- 在训练过程中,对于每一个 Ground Truth关键点,最小化 路的 softmax 输出的交叉熵损失,这样更有利于检测单点。
- key point 任务的预测头是常规 Mask R-CNN 预测头的变体,包括8个3×3、512d的卷积层,然后逐渐2倍上采样,产生56x56的输出(实验发现一个相对高分辨率的输出,对关键点检测的准确性更有用)。
结果
实例分割

人体关键点检测

参考资料
令人拍案称奇的Mask RCNN
实例分割--Mask RCNN详解(ROI Align / Loss Fun)
先理解Mask R-CNN的工作原理,然后构建颜色填充器应用