请简述分类实现原理
KVO的实现原理是怎样的
能否为分类添加成员变量
目录
分类 & 关联对象 & 扩展 & 代理
通知
KVO
KVC
属性关键字
分类
你用分类都做了哪些事 ?
声明私有方法
分解体积庞大的类文件
把 Framework 的私有方法公开
特点
讲特点是为了能更好的和扩展区分开来
运行时决议 --- 比如一个数组类,在编好分类文件之后,并没有把分类当中对应添加的内容附加到相应的数组类,而是在运行时通过 runtime 真实的添加到数组类中
可以为系统类添加分类
分类中都可以添加哪些内容
实例方法
类方法
协议
属性(不是添加实例变量,实例变量需要通过关联对象添加) 看一下分类的成员结构
struct category_t {
const char *name;
classref_t cls;
struct method_list_t *instanceMethods;
struct method_list_t *classMethods;
struct protocol_list_t *protocols;
struct property_list_t *instanceProperties;
method_list_t *methodsForMeta(bool isMeta) {
if (isMeta) return classMethods;
else return instanceMethods;
}
property_list_t *propertiesForMeta(bool isMeta) {
if (isMeta) return nil; // classProperties;
else return instanceProperties;
}
};
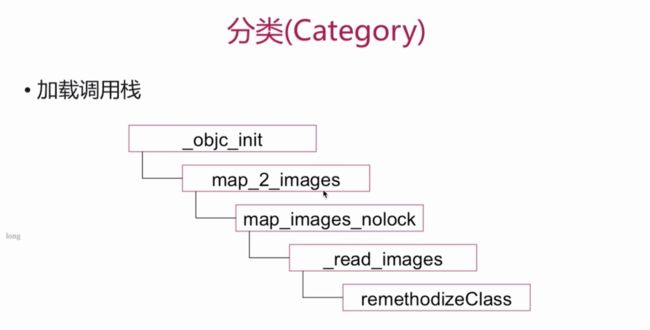
添加分类runtime源码解读
static void
attachCategories(Class cls, category_list *cats, bool flush_caches)
{
if (!cats) return;
if (PrintReplacedMethods) printReplacements(cls, cats);
bool isMeta = cls->isMetaClass();
// fixme rearrange to remove these intermediate allocations
method_list_t **mlists = (method_list_t **)
malloc(cats->count * sizeof(*mlists));
property_list_t **proplists = (property_list_t **)
malloc(cats->count * sizeof(*proplists));
protocol_list_t **protolists = (protocol_list_t **)
malloc(cats->count * sizeof(*protolists));
// Count backwards through cats to get newest categories first
int mcount = 0;
int propcount = 0;
int protocount = 0;
int i = cats->count; //宿主类分类的总数
bool fromBundle = NO;
while (i--) { //这里是倒序遍历,最先访问最后编译的分类 ,所以 最后编译的最终生效
auto& entry = cats->list[I];
//获取分类的方法列表
method_list_t *mlist = entry.cat->methodsForMeta(isMeta);
if (mlist) {
//最后编译的分类最先添加到分类数组中
mlists[mcount++] = mlist;
fromBundle |= entry.hi->isBundle();
}
//属性列表添加规则, 同方法列表添加规则
property_list_t *proplist = entry.cat->propertiesForMeta(isMeta);
if (proplist) {
proplists[propcount++] = proplist;
}
//协议列表添加规则 ,
protocol_list_t *protolist = entry.cat->protocols;
if (protolist) {
protolists[protocount++] = protolist;
}
}
//获取宿主类当中的rw数据,其中包含宿主类的方法列表信息
auto rw = cls->data();
// 主要是针对 分类中有关于内存管理相关方法情况下的一些特殊处理
prepareMethodLists(cls, mlists, mcount, NO, fromBundle);
rw->methods.attachLists(mlists, mcount);
free(mlists);
if (flush_caches && mcount > 0) flushCaches(cls);
/*
rw 代表类
methhod 代表类的方法列表
attachLists 方法的含义是 将含有mcount个元素的mlists拼接到rw的methods上
*/
rw->properties.attachLists(proplists, propcount);
free(proplists);
rw->protocols.attachLists(protolists, protocount);
free(protolists);
}
为原类添加分类列表runtime源码解读
//addedLists 传递过来的二维数组
[[method_t,method_t,...][method_t,][method_t,......]] 假设这个是 addedLists 的数组, addedCount = 3;
void attachLists(List* const * addedLists, uint32_t addedCount) {
if (addedCount == 0) return;
if (hasArray()) {
//列表中原有元素总数 oldCount = 2
// many lists -> many lists
uint32_t oldCount = array()->count;
//拼接之后的元素总和
uint32_t newCount = oldCount + addedCount;
//根据新总数重新分配内存
setArray((array_t *)realloc(array(), array_t::byteSize(newCount)));
//重新设置元素总和
array()->count = newCount;
memmove(array()->lists + addedCount, array()->lists,
oldCount * sizeof(array()->lists[0]));
/*
内存拷贝
[
A --> [addedList中的第一个元素]
B --> [addedList中的第二个元素]
C --> [addedList中的第三个元素]
[原有的第一个元素]
[原有的第二个元素]
]
这就是分类方法 会覆盖 宿主类的方法的原因
*/
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
else if (!list && addedCount == 1) {
// 0 lists -> 1 list
list = addedLists[0];
}
else {
// 1 list -> many lists
List* oldList = list;
uint32_t oldCount = oldList ? 1 : 0;
uint32_t newCount = oldCount + addedCount;
setArray((array_t *)malloc(array_t::byteSize(newCount)));
array()->count = newCount;
if (oldList) array()->lists[addedCount] = oldList;
memcpy(array()->lists, addedLists,
addedCount * sizeof(array()->lists[0]));
}
}
分类的实现机制
同一个类有多个分类,每个分类有一个同名方法,哪一个方法会生效? 最后编译的分类当中的方法会最终生效
具体可以理解下objc-runtime-new.mm,做了些注释拆解.
分类添加的方法可以覆盖原类方法
同名分类方法谁能生效取决于编译顺序
名字相同的分类会引起编译报错
关联对象
先看一下常用的俩个方法
id objc_getAssociatedObject(id object , const void *key)
void objc_setAssociatedObject(id object,const void *key,id value, objc_AssociationPolicy policy)
void objc_removeAssociatedObject(id object)
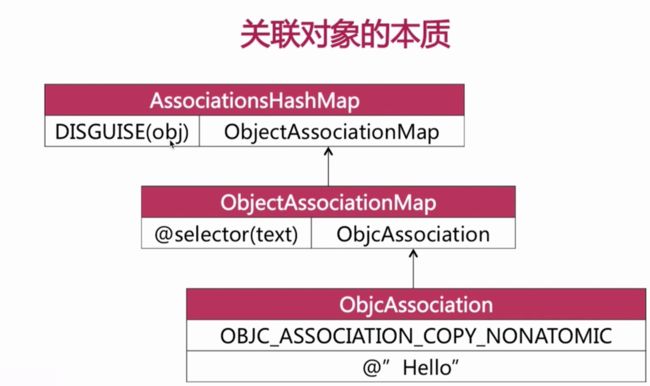
关联对象所添加的成员变量被添加到了哪里?
关联对象由 AssociationsManager 管理并在 AssociationsHashMap存储。
所有的对象的关联内容都在同一个全局容器中
关联对象的本质

扩展相关问题
一般用扩展做什么
声明私有属性
声明私有方法
声明私有成员变量
扩展的特点 (和分类的区别)
编译时决议
只以声明的形式存在,多数情况下寄生于宿主类的.m中
不能为系统类添加扩展
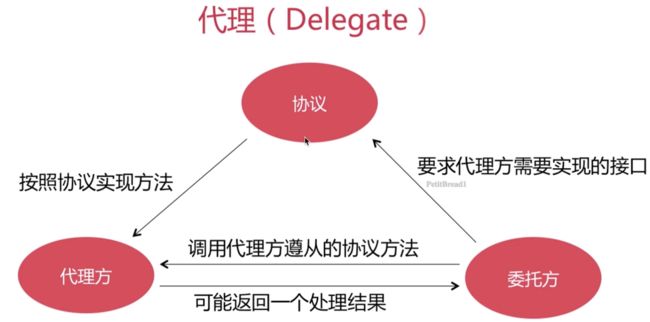
代理
准确的说是一种软件设计模式
iOS当中以@protocol形式提现
传递方式一对一
代理的实现流程
- 一般声明为weak以规避循环引用
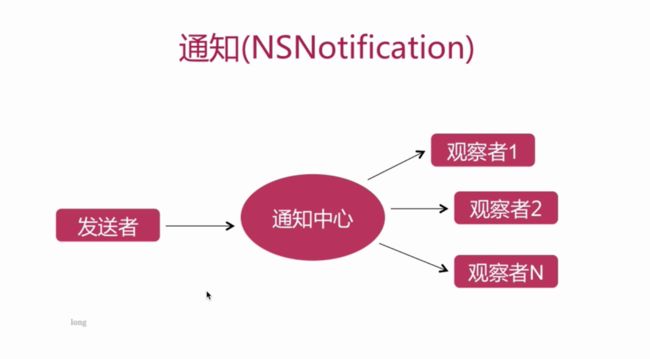
通知
是使用观察者模式来实现用于跨层传递消息的机制
传递方式为一对多
通知的实现流程
KVO
使用 isa-swizzling 来实现KVO
看下图,KVO的实现机制
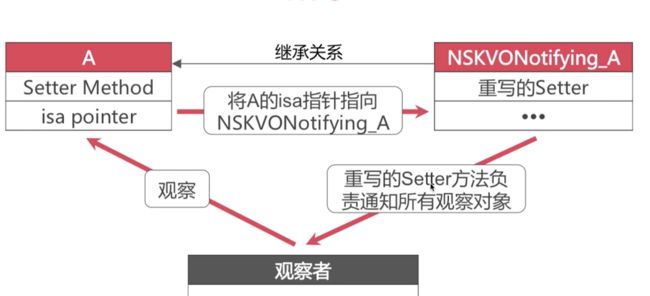
当调用了 addObserver:forkeypath 方法之后,系统会动态创建 NSKVONorifying_A 类,同时将A的isa指针指向NSKVONorifying_A。
代码验证一下KVO_Test

对应断点处可以看到类的变化
子类重写的set方法

*使用setter属性和KVC赋值会触发KVO
*使用成员变量直接赋值不会触发KVO 但可以手动添加一下代码触发
- (void)increase
{
//直接为成员变量赋值
[self willChangeValueForKey:@"value"];
_value += 1;
[self didChangeValueForKey:@"value"];
}
KVC
主要有这俩个方法
-(id)valueForKey:(NSString *)key
-(void)setValue:(id)value forked:(NSString *)key;
通过一副流程图看一下 valueForKey 的实现逻辑

首先系统会判断访问的key是否有对应的getter方法,存在就直接进行调用,不存在就判断实例变量是否存在,通过accessInstanceVariablesDirectly 来判断 ,默认是YES。 如果不存在,会调用 UndefinedKey ,抛出异常.
setValue:(id)value forked:的实现逻辑

KVC 和 KVO
KVC,即是指NSKeyValueCoding,一个非正式的Protocol,提供一种机制来间接访问对象的属性。KVO 就是基于 KVC 实现的关键技术之一。
一个对象拥有某些属性。比如说,一个 Person 对象有一个 name 和一个 address 属性。以 KVC 说法,Person 对象分别有一个value 对应他的 name 和 address 的 key。 key 只是一个字符串,它对应的值可以是任意类型的对象。从最基础的层次上看,KVC有两个方法:一个是设置 key 的值,另一个是获取 key 的值
属性关键字
读写权限
readonly
readwrite
原子性
atomic只对对象属性值的获取保证安全,不对属性的使用保证安全
nonatomic
引用计数
retail/strong
assign 修饰基本数据类型,如 int ,BOOL 等 修饰对象类型时,不改变其引用计数
weak 不改变被修饰对象的引用计数 所指对象在被释放之后会自动置为nil 那么问题来了,weak对象修饰的对象为什么在被释放之后会置为nil?
copy 浅拷贝和深拷贝的概念
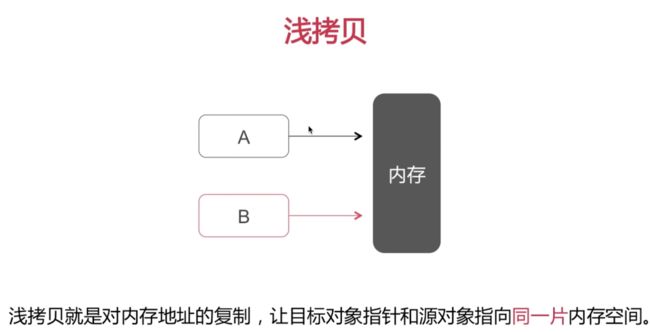

看一下他倆的区分
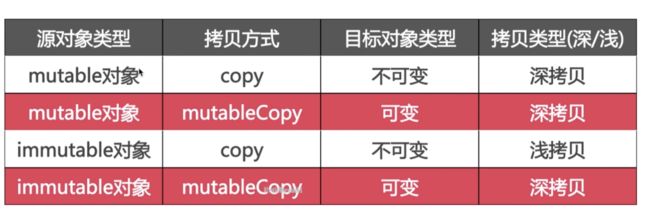
总结下来三点
可变对象的 copy 和mutableCopy都是深拷贝
不可变对象的copy是浅拷贝,mutableCopy是深拷贝
-
copy方法返回的都是不可变对象
提问, 这样写有什么问题 ?@property(copy)NSMutableArray *array?
无论复制过来的是可变还是不可变对象,都是NSArray,当调用方调用 Array 的添加对象和移除对象等操作,对于不可变 Array 就会产生程序异常
总结
1.分类的实现原理 由运行时来决议的,不同分类当中含有同名分类方法,谁最终生效取决于谁最终参与编译。 假如分类当中添加的方法恰好是数组当中的某一个方法的时候,分类方法会覆盖同名数组类方法
2.KVO的实现原理 运用了isa混写技术来为某一个类动态生成了一个子类,然后重写子类的setter方法,用isa指针指向子类
3.怎么为分类添加成员变量 关联对象