Kettle
1.Kettle的介绍:
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle目前包含五个产品:Spoon、Pan、Chef、Kithcen、Encr。
SPOON:是一个图形用户界面,允许你通过图形界面来设计ETL转换过程(Transformation)和任务。
PAN:转换(trasform)执行器;允许你批量运行由Spoon设计的ETL转换 (如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面。
CHEF:允许你创建任务(Job)。 任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了。
KITHCEN:作业(job)执行器;允许你批量使用由Chef设计的任务 (如使用一个时间调度器)。KITCHEN也是一个后台运行的程序。
ENCR:用来加密连接数据库密码与集群时使用的密码
Kettle 下载和部署:
1、我们可以进入 Kettle官网 进行下载,进入之后,下拉页面,看到如图所示;
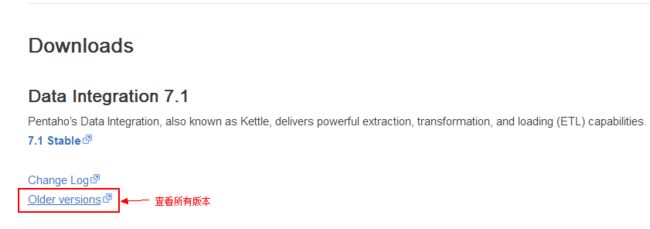
查看所有版本,我们可以看到最新版本已经所有旧版本的Kettle

此处选择7.1版本

2、Kettle 环境配置
由于Kettle是使用Java语言编写的,所有Kettel的运行需要有Java环境,安装JDK,请参考:Linux环境下JDK安装和配置和Windows环境下JDK安装和配置
3、运行Kettle
进入到Kettle目录,如果Kettle部署在windows环境双击Spoon.bat文件启动Kettle,如果是在Linux环境下,则运行spoon.sh文件启动。出现如下界面,则我们的Kettle就安装成功了。

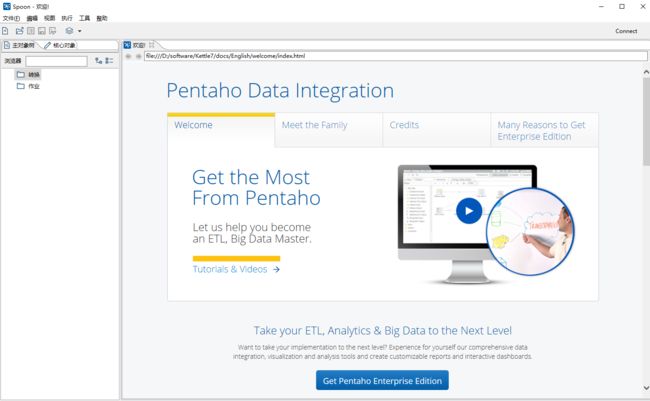
至此,Kettle的下载、环境配置和安装就基本完成了。
2.Kettle入门之二 Kettle应用场景(只增量插入)
在【数据整合】Kettle 应用之一 介绍、安装中我们已经介绍了如何安装Kettle工具。现在我们开始使用Kettle。
Kettle应用场景
示例1:将数据源A库中的某张表的数据插入到数据库B中。
示例2:将数据源A库中的某张表的数据插入更新到数据库B中。
示例3:将数据源A库中的某张表或某几个表中的字段合并后的数据插入到数据库B中。
示例4:将数据源A库中的某两张或多张表级联查询的数据插入到数据库B中的一张表中
在此,我们主要对示例1进行说明。
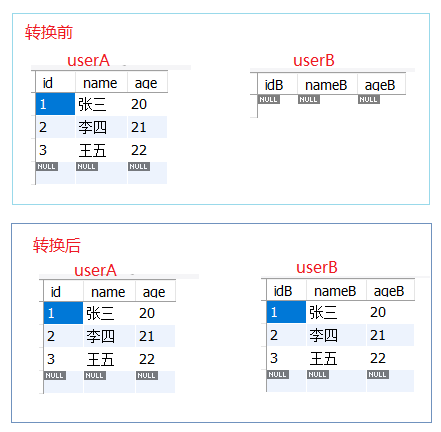
为方便演示,我们在数据库A和数据库B中分别创建表userA和表userB。最终目标为将数据表userA中的数据插入到数据表userB中。
create database testA;
use testA;
create table `userA` (
`id` INT (10) primary key,
`name` VARCHAR (50),
`age` INT (3)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;
insert into userA values (1, '张三', 20);
insert into userA values (2, '李四', 21);
insert into userA values (3, '王五', 22);
create database testB;
use testB;
create table `userB` (
`idB` INT (10) primary key,
`nameB` VARCHAR (50),
`ageB` INT (3)
) ENGINE = InnoDB DEFAULT CHARSET = utf8;
操作步骤
1、运行软件,进入主界面。点击左上角的文件 → 新建 → 转换新建一个转换,并保存,转换的后缀名为ktr。

2、点击面板左侧的主对象树,选择DB连接右键,选择新建或新建数据库连接向导分别创建对数据库A和数据库B的连接。
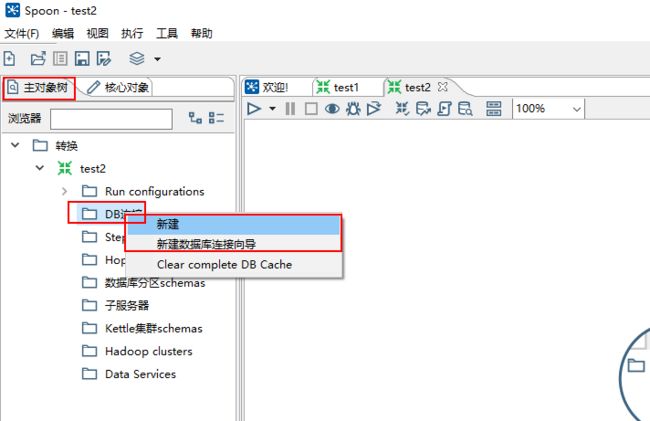

选择“新建”选项的操作视图

选择“新建数据库连接向导”选项的操作视图 1

选择“新建数据库连接向导”选项的操作视图 2

选择“新建数据库连接向导”选项的操作视图 3
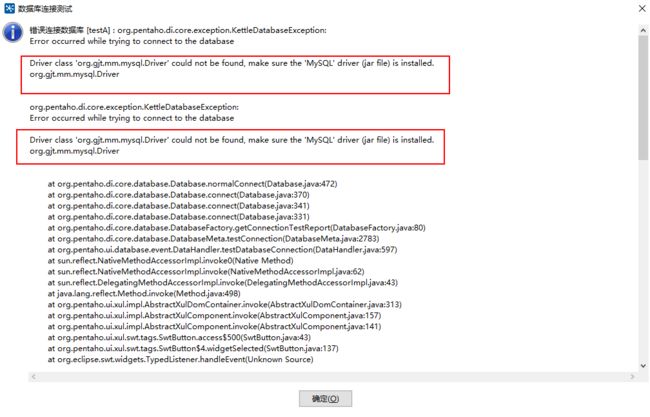
注意:如果在点击测试连接时出现下图所示错误,检查我们的安装目录下的lib中是否有对应数据库连接的jar包文件(如mysql的jar文件:mysql-connector-java-5.1.6-bin.jar),下载对应的jar,放到lib文件夹下,重启kettle软件,即可。
3、点击面板左侧的核心对象,选择输入文件夹下的表输入并把它拖到右侧的编辑区中。

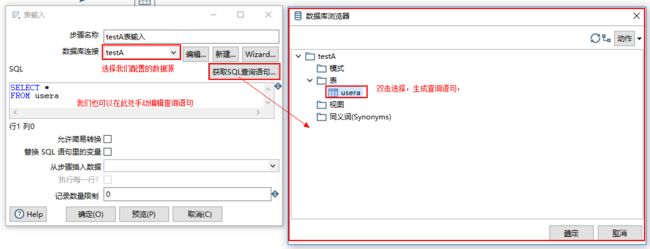
4、双击编辑区的“表输入”图标,编辑数据输入源。
5、点击面板左侧的核心对象,选择转换文件夹下的字段选择并把它拖到右侧的编辑区中。
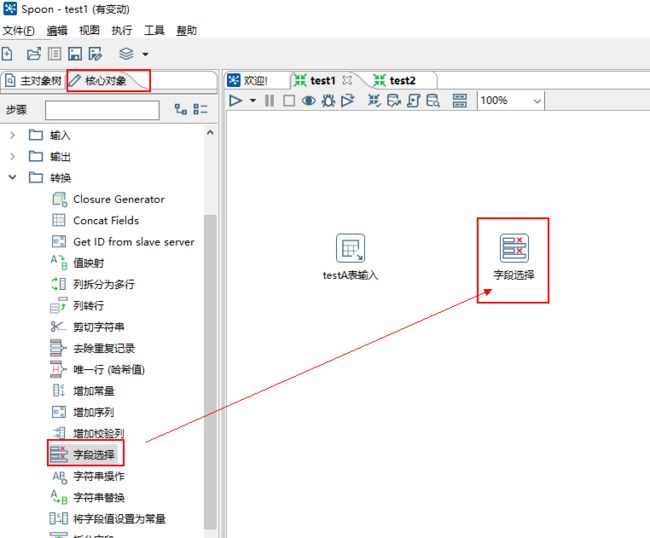
6、按住shift同时鼠标从 “testA表输入”到“字段选择”画一条连接线。

7、双击编辑区的“字段选择”,选择“元数据”面板,点击右侧“获取改变的字段”,将自动列出输入表中所有字段。根据要抽取的目标表中的字段名,给每一个输入字段修改为对应的输出字段。
注意:此时必须在Encoding栏中选择输出库的编码格式

image.png
8、点击面板左侧的核心对象,选择输出文件夹下的表输出并把它拖到右侧的编辑区中,按住shift划线连接 “字段选择”。
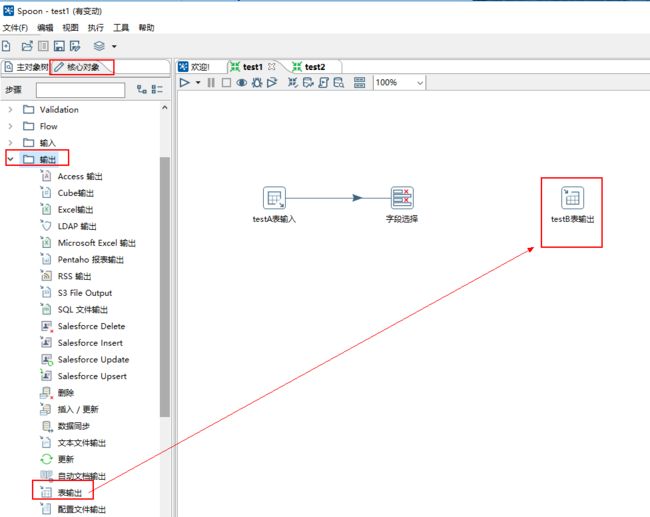
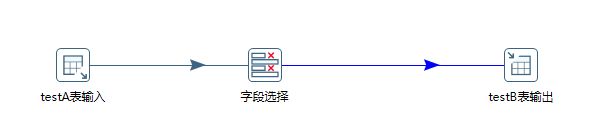
9、双击编辑区的“表输出”图标,编辑数据输出目标。
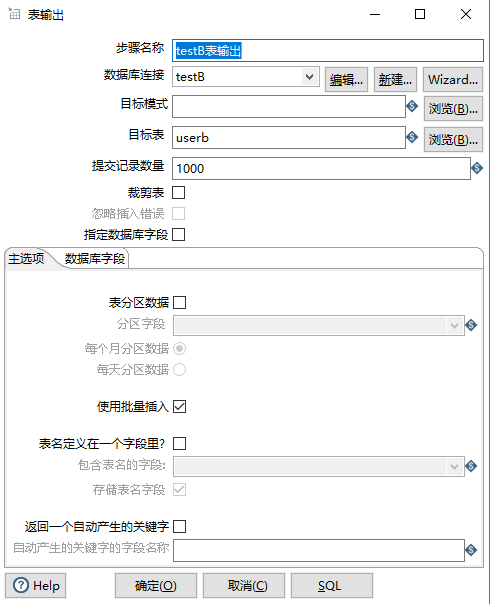
10、然后勾选指定数据库字段,选择数据库字段,点击输入字段映射,映射输入输出关系。

注意:如果在点击 输入字段映射 时,提示如下错误:
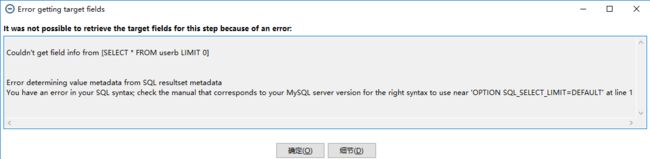
检查我们的数据库驱动jar包版本 mysql-connector-java-5.1.6-bin.jar , 因为测试数据库版本为 MySQL 6.3 , 而使用此版本的数据库驱动包,会在创建数据库连接的时候发送测试语句SET OPTION SQL_SELECT_LIMIT=DEFAULT, 但是5.6及以后的版本都不再支持SET...,此时,我们只需要将驱动版本升级,只需要将数据库驱动版本修改为5.1.22以上即可。
11、因为我们在“字段选择”中修改了每个输入字段对应的输出字段的名称,此处,我们点击猜一猜,将会自动根据字段近似度自动匹配映射关系。

12、到这里,我们最简单的一个提取数据的转换已经建立完成了,点击“校验这个转换”,Kettle会校验并给出简单的报告。没有任何问题。
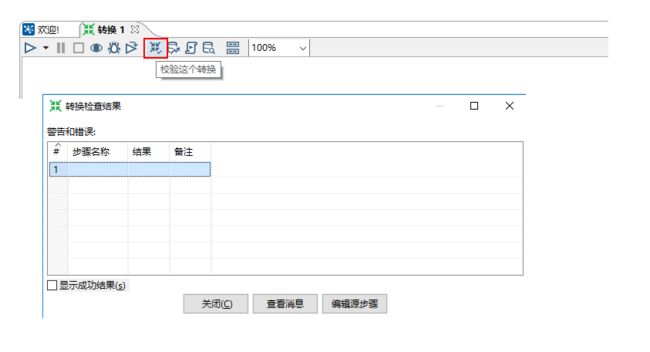
13、点击“运行这个转换”,选择“本地执行”,点击“启动”来执行这个转换。

14、转换成功后,我们可以在控制台中看到如下信息。检查本地数据库,数据库A的userA表中的数据已经全部被导入到了数据库B的userB表中。

注:此示例只适用于目标表为空,或者目标表与源表没有主键冲突的情况
3. Kettle入门之三 Kettle定时任务(GUI)
有时候,需要我们建立的转换任务能够定时执行,那么我们需要怎么办呢?
此时,我们需要建立一个job,来让转换定时执行。
操作步骤
1、运行软件,进入主界面。点击左上角的文件 → 新建 → 作业(J)新建一个作业(job),并保存,作业的后缀名为kjb。
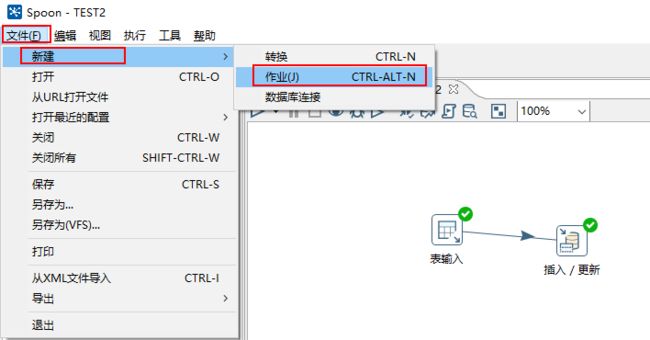
2、点击面板左侧的核心对象,选择通用文件夹下的START和转换并把它拖到右侧的编辑区中,按住shift画线连接“START” 和“转换”。

3、双击编辑区的“START”图标,设置定时任务。

image.png
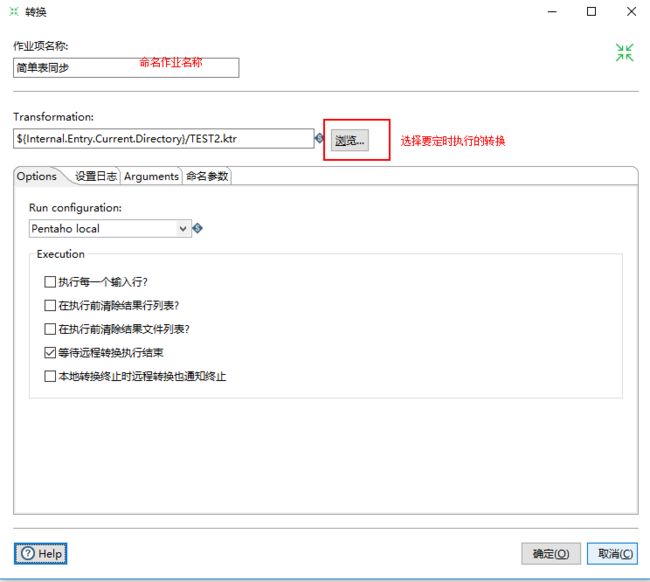
4、双击编辑区的“转换”图标,设置要定时执行的转换。
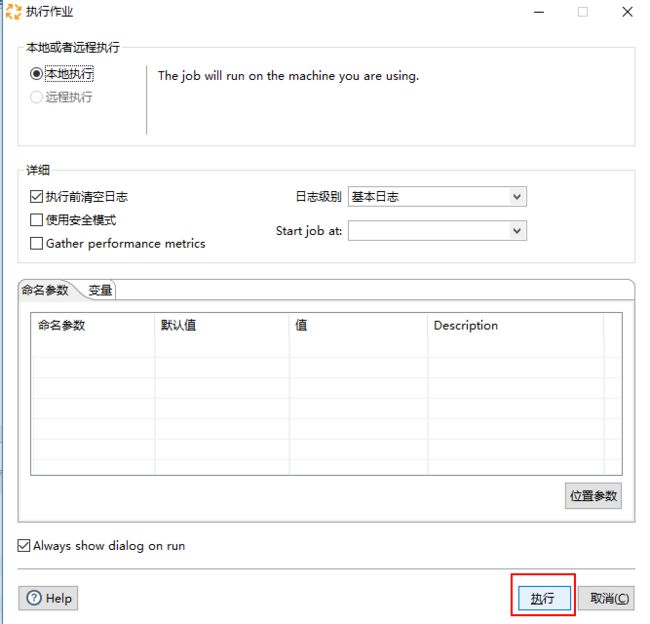
5、点击“Run”,选择“本地执行”,点击“执行”来执行这个转换。

image.png

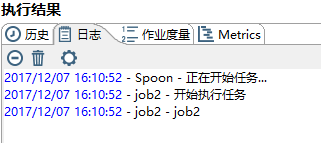
6、等待设置的间隔时间后,正确执行效果如图
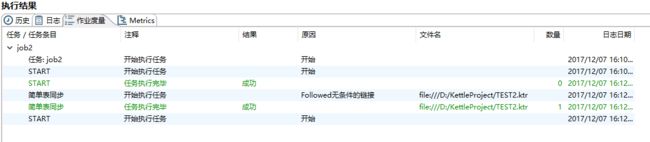

4. Kettle入门之四 Kettle定时任务(后台任务)
前面我们介绍了 Kettle的Spoon的转换和作业定时任务GUI设计方式以及运行,但是在实际应用中,我们需要计划任务是在服务器后台运行。
首先我们需要了解Kettle的Kitchen和Pan
Kitchen——作业(job)执行器 (命令行方式)
Pan——转换(trasform)执行器 (命令行方式)
下面我们将重点讲解经常会用到的 ***作业执行器 Kitchen.bat *** 。
Kitchen 参数说明:
-rep:Repository name 任务包所在存储名
-user:Repository username 执行人
-pass:Repository password 执行人密码
-job:The name of the job to launch 任务包名称
-dir:The directory (don''t forget the leading / or )
-file:The filename (Job XML) to launch
-level:The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 指定日志级别
-log:The logging file to write to 指定日志文件
-listdir:List the directories in the repository 列出指定存储中的目录结构。
-listjobs:List the jobs in the specified directory 列出指定目录下的所有任务
-listrep:List the defined repositories 列出所有的存储
-norep:Don''t log into the repository 不写日志
命令行执行配置方式
1、新建一个bat文件,命名job.bat,然后编辑,输入内容如下:
d: ## Kitchen.bat所在路径盘符
cd D:\software\Kettle7 ## Kitchen.bat所在目录
## 作业(job)文件路径和日志文件路径
## 执行kitchen执行job,并写入日志
kitchen /file:D:\KettleProject\job2.kjb /level:Base>>D:\KettleProject\test.log
注意:确保路径的正确性。
2、双击job.bat,即可运行。
后台运行配置方式
我们已经建立了命令行运行的bat文件,并且已经可以正确执行我们的ETL任务了,但是现在我们在运行bat后,桌面上面会一直存在一个控制台的黑窗口,我们可以使用bat命令中的隐藏窗口的命令。
修改我们的job.bat文件
@echo offif"%1"=="h"goto beginmshta vbscript:createobject("wscript.shell").run("%~nx0 h",0)(window.close)&&exit:begin::d:## Kitchen.bat所在路径盘符cd D:\software\Kettle7## Kitchen.bat所在目录## 作业(job)文件路径和日志文件路径## 执行kitchen执行job,并写入日志kitchen/file:D:\KettleProject\job2.kjb /level:Base>>D:\KettleProject\test.log
在此双击job.bat运行,我们将不会再看到控制台黑窗口继续保留在桌面上,并且等待设置的间隔时间后,我们可以看到日志文件记录。
···
2017/12/07 16:51:26 - Kitchen - Logging is at level : 基本日志
2017/12/07 16:51:26 - Kitchen - Start of run.
2017/12/07 16:51:31 - job2 - 开始执行任务
2017/12/07 16:51:31 - job2 - job2
2017/12/07 16:53:31 - job2 - 开始项[简单表同步]
2017/12/07 16:53:31 - 简单表同步 - Loading transformation from XML file [file:///D:/KettleProject/TEST2.ktr]
2017/12/07 16:53:31 - 简单表同步 - Using run configuration [Pentaho local]
2017/12/07 16:53:31 - 简单表同步 - Using legacy execution engine
2017/12/07 16:53:31 - TEST2 - 为了转换解除补丁开始 [TEST2]
2017/12/07 16:53:32 - 表输入.0 - Finished reading query, closing connection.
2017/12/07 16:53:32 - 表输入.0 - 完成处理 (I=3, O=0, R=0, W=3, U=0, E=0)
2017/12/07 16:53:32 - 插入 / 更新.0 - 完成处理 (I=3, O=0, R=3, W=3, U=1, E=0)
···
5. Kettle入门之五 Kettle应用场景(增量插入和更新)
Kettle应用场景
示例1:将数据源A库中的某张表的数据插入到数据库B中。
示例2:将数据源A库中的某张表的数据插入更新到数据库B中。
示例3:将数据源A库中的某张表或某几个表中的字段合并后的数据插入到数据库B中。
示例4:将数据源A库中的某两张或多张表级联查询的数据插入到数据库B中的一张表中
在此,我们主要对示例2进行说明。
为方便演示,我们在数据库A和数据库B中分别创建表userA和表userB。最终目标为将数据表userA中的数据插入更新到数据表userB中。
createdatabasetestA;usetestA;createtable`userA`(`id`int(10) primarykey,`name`varchar(50),`age`int(3))ENGINE=InnoDBDEFAULTCHARSET=utf8;insertintouserAvalues(1,'张三',25);insertintouserAvalues(2,'李四',29);insertintouserAvalues(3,'王五',28);insertintouserAvalues(4,'赵六',28);createdatabasetestB;usetestB;createtable`userB`(`idB`int(10) primarykey,`nameB`varchar(50),`ageB`int(3))ENGINE=InnoDBDEFAULTCHARSET=utf8;insertintouserBvalues(1,'张三',20);insertintouserBvalues(2,'李四',21);insertintouserBvalues(3,'王五',22);
操作步骤
1、运行软件,进入主界面。点击左上角的文件 → 新建 → 转换新建一个转换,并保存,转换的后缀名为ktr。
2、点击面板左侧的主对象树,选择DB连接右键,选择新建或新建数据库连接向导分别创建对数据库A和数据库B的连接。
选择“新建”选项的操作视图
选择“新建数据库连接向导”选项的操作视图 1
选择“新建数据库连接向导”选项的操作视图 2
选择“新建数据库连接向导”选项的操作视图 3
注意:如果在点击测试连接时出现下图所示错误,检查我们的安装目录下的lib中是否有对应数据库连接的jar包文件(如mysql的jar文件:mysql-connector-java-5.1.6-bin.jar),下载对应的jar,放到lib文件夹下,重启kettle软件,即可。
3、点击面板左侧的核心对象,选择输入文件夹下的表输入并把它拖到右侧的编辑区中。
4、双击编辑区的“表输入”图标,编辑数据输入源。
5、点击面板左侧的核心对象,选择输出文件夹下的插入/更新并把它拖到右侧的编辑区中,按住shift画线连接 “表输入”。
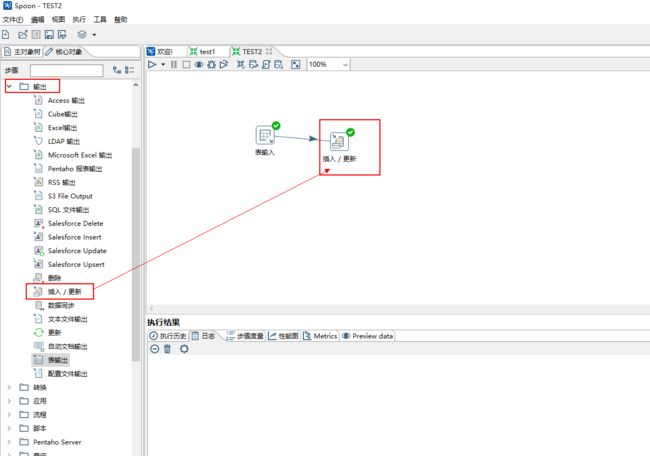
6、双击编辑区的“插入/更新”图标,编辑控件内容。
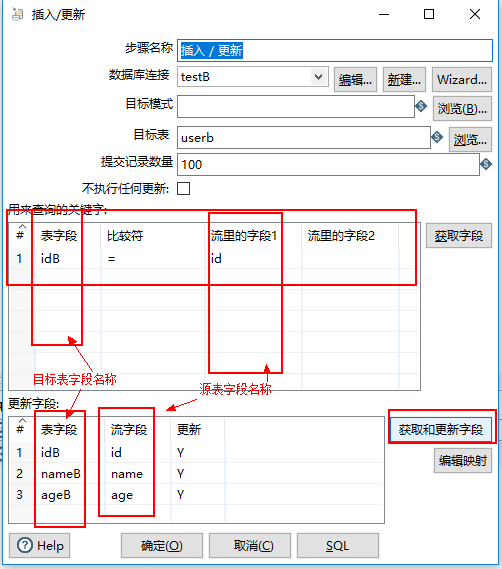
用来查询的关键字,此处只选择主键id,表示这里按照id查询,如果此id存在,则更新数据,若不存在则插入数据。
7、到这里,我们最简单的一个插入/更新数据的转换已经建立完成了,点击“校验这个转换”,Kettle会校验并给出简单的报告。没有任何问题。
8、点击“运行这个转换”,选择“本地执行”,点击“启动”来执行这个转换。
9、转换成功后,我们可以在控制台中看到如下信息。检查本地数据库,数据库A的userA表中的数据已经全部被插入更新到了数据库B的userB表中。

注:此示例适用于插入和更新目标源数据,无法将已经源表中的删除的记录同步到目标表中
need-to-insert-img
6.Kettle入门之六 Kettle应用场景(字段合并)
Kettle应用场景
示例1:将数据源A库中的某张表的数据插入到数据库B中。
示例2:将数据源A库中的某张表的数据插入更新到数据库B中。
示例3:将数据源A库中的某张表或某几个表中的字段合并后的数据插入到数据库B中。
示例4:将数据源A库中的某两张或多张表级联查询的数据插入到数据库B中的一张表中
在此,我们主要对示例3进行说明。
为方便演示,我们在数据库A和数据库B中分别创建表userA和表userB。最终目标为将数据表userA中的字段“surname”和“name”合并后的数据插入到数据表userB中。
createdatabasetestA;usetestA;createtable`userA`(`id`int(10) primarykey,`surname`varchar(10),`name`varchar(50),`age`int(3))ENGINE=InnoDBDEFAULTCHARSET=utf8;insertintouserAvalues(1,'张','三丰',30);insertintouserAvalues(2,'李','四光',28);insertintouserAvalues(3,'王','小米',22);createdatabasetestB;usetestB;createtable`userB`(`idB`int(10) primarykey,`nameB`varchar(50),`ageB`int(3))ENGINE=InnoDBDEFAULTCHARSET=utf8;
操作步骤
1、运行软件,进入主界面。点击左上角的文件 → 新建 → 转换新建一个转换,并保存,转换的后缀名为ktr。
2、点击面板左侧的主对象树,选择DB连接右键,选择新建或新建数据库连接向导分别创建对数据库A和数据库B的连接。
选择“新建”选项的操作视图
选择“新建数据库连接向导”选项的操作视图 1
选择“新建数据库连接向导”选项的操作视图 2
选择“新建数据库连接向导”选项的操作视图 3
注意:如果在点击测试连接时出现下图所示错误,检查我们的安装目录下的lib中是否有对应数据库连接的jar包文件(如mysql的jar文件:mysql-connector-java-5.1.6-bin.jar),下载对应的jar,放到lib文件夹下,重启kettle软件,即可。
3、点击面板左侧的核心对象,选择输入文件夹下的表输入并把它拖到右侧的编辑区中。
4、双击编辑区的“表输入”图标,编辑数据输入源。
5、点击面板左侧的核心对象,选择脚本文件夹下的javaScript脚本并把它拖到右侧的编辑区中,按住shift画线连接 “表输入”。

6、双击编辑区的“javascript脚本”,编辑脚本信息。
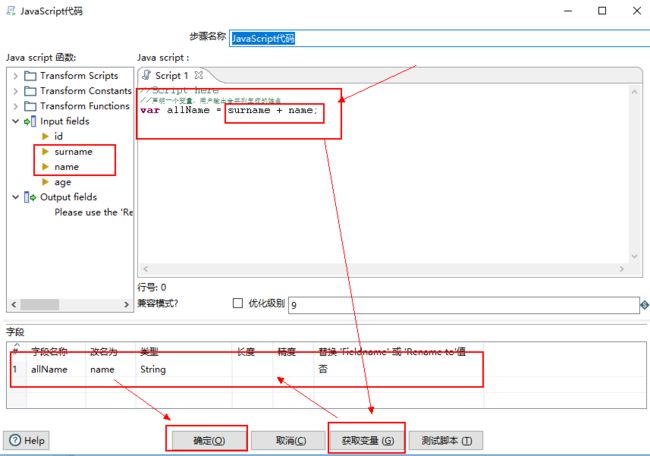
因为我们需要将 “surname ” 和 “name” 合并成一个完整的姓名,所以,我们只需要在 “java script:”下的输入框中录入一下信息。
//声明一个变量,用户输出合并列生成的姓名varallName = surname +name;
然后点击获取变量自动将我们定义的变量输出到字段栏中,我们可以修改字段名称。
7、点击面板左侧的核心对象,选择输出文件夹下的插入/更新并把它拖到右侧的编辑区中,按住shift画线连接 “javaScript脚本”。
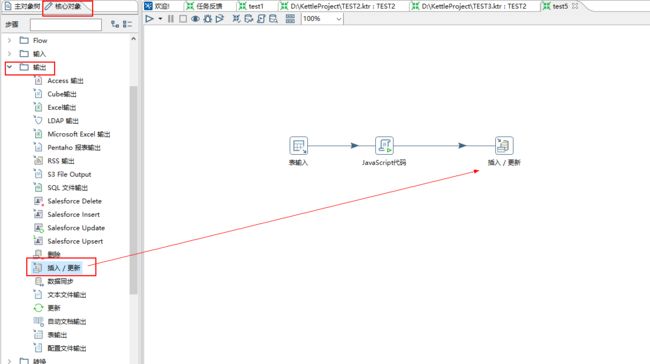
8、双击编辑区的“插入/更新”图标,编辑控件内容。

用来查询的关键字,此处只选择主键id,表示这里按照id查询,如果此id存在,则更新数据,若不存在则插入数据。
9、到这里,我们最简单的一个插入/更新数据的转换已经建立完成了,点击“校验这个转换”,Kettle会校验并给出简单的报告。没有任何问题。
10、点击“运行这个转换”,选择“本地执行”,点击“启动”来执行这个转换。
11、转换成功后,我们可以在控制台中看到如下信息。检查本地数据库,数据库A的userA表中的数据已经全部被插入更新到了数据库B的userB表中。


7.Kettle入门之七 Kettle应用场景(多表级联)
Kettle应用场景
示例1:将数据源A库中的某张表的数据插入到数据库B中。
示例2:将数据源A库中的某张表的数据插入更新到数据库B中。
示例3:将数据源A库中的某张表或某几个表中的字段合并后的数据插入到数据库B中。
示例4:将数据源A库中的某两张或多张表级联查询的数据插入到数据库B中的一张表中
在此,我们主要对示例4进行说明。
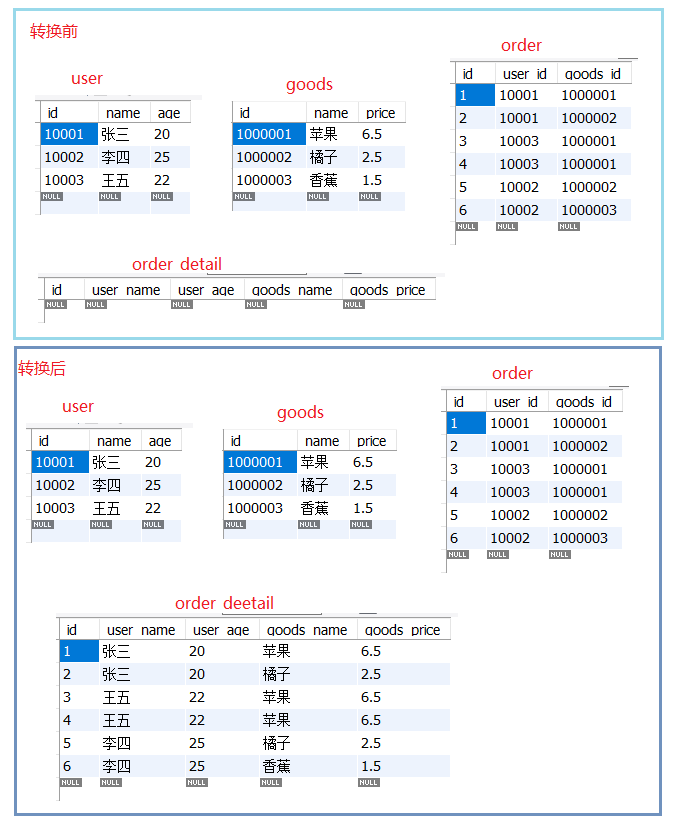
为方便演示,我们在数据库A中创建“用户表”、“商品表”、“订单表”,在数据库B中创建“订单详细信息表”。最终目标为根据用户表、商品表、订单表获取订单详细信息表,最终目标结果如下。
createdatabasetestA;usetestA;-- 用户表createtable`user`(`id`int(10) primarykey,`name`varchar(50),`age`int(3))ENGINE=InnoDBDEFAULTCHARSET=utf8;insertintouservalues(10001,'张三',20);insertintouservalues(10002,'李四',25);insertintouservalues(10003,'王五',22);-- 商品表createtable`goods`(`id`int(10) primarykey,`name`varchar(50),`price`float(16))ENGINE=InnoDBDEFAULTCHARSET=utf8;insertintogoodsvalues(1000001,'苹果',6.5);insertintogoodsvalues(1000002,'橘子',2.5);insertintogoodsvalues(1000003,'香蕉',1.5);-- 订单表createtable`order`(`id`int(10) primarykey,`user_id`varchar(50),`goods_id`int(10))ENGINE=InnoDBDEFAULTCHARSET=utf8;insertinto`order`values(1,10001,1000001);insertinto`order`values(2,10001,1000002);insertinto`order`values(3,10003,1000001);insertinto`order`values(4,10003,1000001);insertinto`order`values(5,10002,1000002);insertinto`order`values(6,10002,1000003);createdatabasetestB;usetestB;-- 订单详情表createtable`order_detail`(`id`int(10) primarykey,`user_name`varchar(50),`user_age`int(3),`goods_name`varchar(50),`goods_price`float(16))ENGINE=InnoDBDEFAULTCHARSET=utf8;
操作步骤
1、运行软件,进入主界面。点击左上角的文件 → 新建 → 转换新建一个转换,并保存,转换的后缀名为ktr。
2、点击面板左侧的主对象树,选择DB连接右键,选择新建或新建数据库连接向导分别创建对数据库A和数据库B的连接。
选择“新建”选项的操作视图
选择“新建数据库连接向导”选项的操作视图 1
选择“新建数据库连接向导”选项的操作视图 2
选择“新建数据库连接向导”选项的操作视图 3
注意:如果在点击测试连接时出现下图所示错误,检查我们的安装目录下的lib中是否有对应数据库连接的jar包文件(如mysql的jar文件:mysql-connector-java-5.1.6-bin.jar),下载对应的jar,放到lib文件夹下,重启kettle软件,即可。
3、点击面板左侧的核心对象,选择输入文件夹下的表输入并把它拖到右侧的编辑区中。
4、双击编辑区的“表输出”图标,编辑数据输入源。此处为多表联合查询,所以表输入我们配置的表为订单表(关联关系表)

5、点击面板左侧的** 核心对象,选择查询 ** 文件夹下的 ** 数据库查询 **,并把它拖到右侧的编辑区中,按住 shift 画线连接 “表输入”,如下图。

6、双击编辑区的“数据库查询”,图标,配置级联查询关系。
配置用户表关联查询:
(1)步骤名称写入“user”,数据库连接选择我们user表所在的数据库,如果数据源未配置,可查看步骤2,进行配置。
(2)选择数据库之后,我们通过“表名”后的 “浏览”按钮,选择我们的关联表“user”。
(3)查询所需关键,即为两表之间的关联字段,操作符根据需要,此处选择 “=”。
(4) 查询表返回的值,即为我们需要通过关联表“user”,获取到的字段。
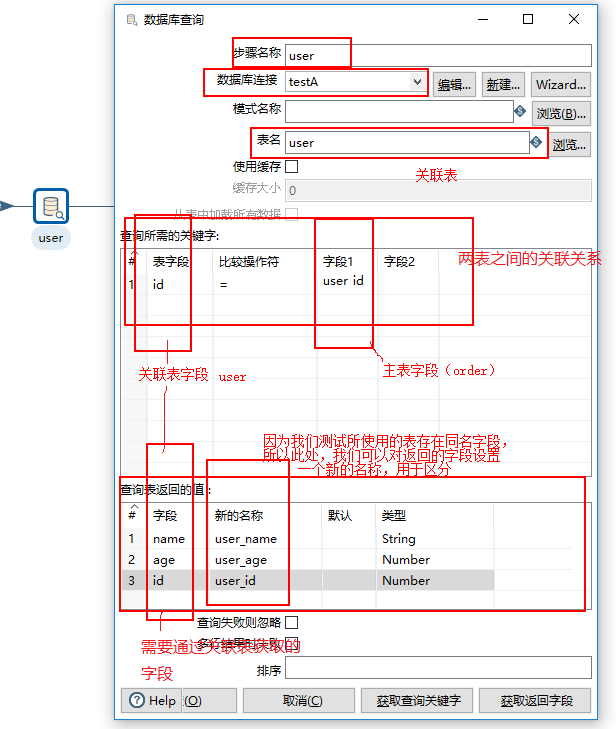
类似的,我们按照上述方法,配置商品表关联查询。

7、点击面板左侧的** 核心对象,选择输出 ** 文件夹下的 ** 插入/更新 **,并把它拖到右侧的编辑区中,按住 shift 画线连接 “数据库查询”(goods),如下图。
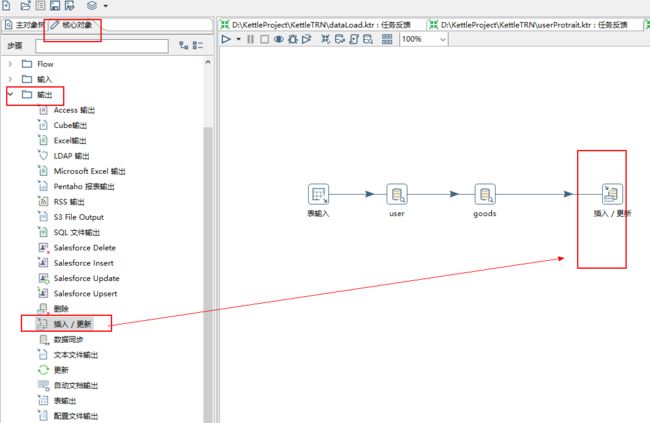
8、双击右侧编辑区的“查询/更新”图标,编辑输出数据对应关系。

用来查询的关键字,此处只选择主键id,表示这里按照id查询,如果此id存在,则更新数据,若不存在则插入数据。
9、到这里,我们最简单的一个级联查询的转换已经建立完成了,点击“校验这个转换”,Kettle会校验并给出简单的报告。没有任何问题。
10、点击“运行这个转换”,选择“本地执行”,点击“启动”来执行这个转换。
11、转换成功后,我们可以在控制台中看到如下信息。检查本地数据库。
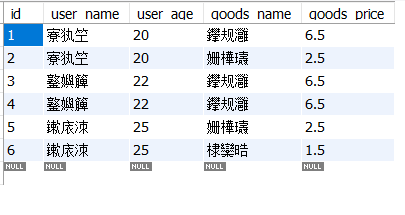

此时,我们看到,虽然我们的数据已经成功提取了,但是中文部分出现了乱码。
我们可以进入主对象树 → DB连接 → testA(数据源) ** ,双击“testA”,选择“高级”,在下方输入set names gbk; **,设置编码格式为gbk,可以根据实际情况设置为其他编码格式。
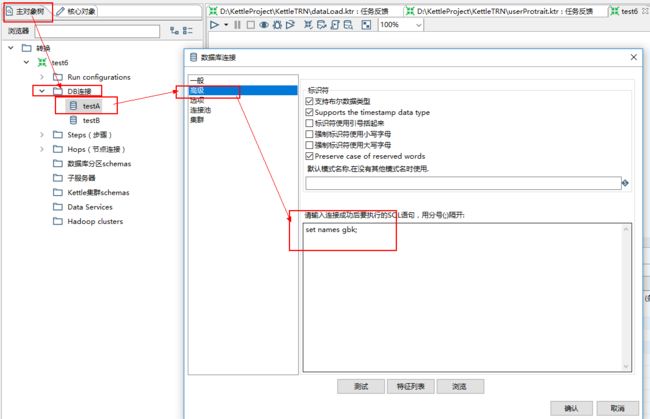
再次启动这个转换,我们可以看到,数据已经正常显示。
注意:
“数据库查询”组件的作用是使用前面“表输入”查询到的一条或多条记录再查询其他表中的数据,其本质类似于我们常用的Master-Detail table query,在查询到主表的某条记录后,自动返回字表中匹配的记录。
“数据库查询”组件的作用相当于左连接查询,我们使用时,需注意