IO学习笔记整理
1. File类
1.1 File对象的三种创建方式:
File对象是一个抽象的概念,只有被创建出来之后,文件或文件夹才会真正存在
注意:File对象想要创建成功,它的目录必须存在!
import java.io.File; /* 演示三种创建File对象的方式 */ public class FileDemo { public static void main(String[] args) throws Exception { //指定完整路径名的字符串 File f1 = new File("e:/test/a.txt"); //指定父路径名以及子路径名的字符串 File f2 = new File("e:/test", "b.txt"); //指定父路径的File对象以及子路径名的字符串 File f3 = new File(new File("e:/test"), "c.txt"); f1.createNewFile(); f2.createNewFile(); f3.createNewFile(); } }
如果使用的是相对路径(即不以盘符开头),那么默认的是当前项目的路径
1.2 mkdir和createNewFile方法
mkdir和createNewFile两个方法的区别,前者看成文件夹,哪怕写上了后缀,后者看成文件
import java.io.File; /* 演示mkdir和createNewFile的区别 注:如果出现同名的文件以及文件夹,File会首先创建文件! */ public class FileDemo2 { public static void main(String[] args) throws Exception { File file1 = new File("e:/test/a.txt"); File file2 = new File("e:/test/aaa.txt"); //创建一个文本文件 file1.createNewFile(); //创建一个名为aaa.txt的文件夹 file2.mkdir(); } }
在调用delete方法的时候要注意要删除的文件夹不能包含内容,否则就会报错
1.3 renameTo方法
renameTo方法如果在不同路径,就相当于剪切加重命名
import java.io.File; /* 演示rename方法以及剪切的效果 */ public class FileDemo3 { public static void main(String[] args) { File srcFile = new File("e:/test/a.txt"); File destFile = new File("e:/test/b.txt"); //如果源文件和目标文件拥有相同的父目录,那么就是改名操作 //srcFile.renameTo(destFile); //如果两者的父目录不相同,那么就相当于剪切并改名 File destFile2 = new File("e:/test1/b.txt"); srcFile.renameTo(destFile2); } }
1.4 length方法的说明
关于length()方法,如果是文件的话返回文件的字节数,而如果是文件夹的话,是不确定的
import java.io.File; /* 关于length方法的说明 */ public class FileDemo4 { public static void main(String[] args) { //如果是一个文件的话,length方法即返回这个文件的字节数 File f1 = new File("e:/test/a.txt"); System.out.println(f1.length()); //如果是文件夹的话,返回值是不确定的,不一定是0,有时会是别的数字 File f2 = new File("e:/test"); System.out.println(f2.length()); }
}
1.5 listFiles方法
listFiles方法的优点是由于返回的是一个File类型的数组,而File本身有各种各样的方法,因此非常灵活,可以实现各种操作
import java.io.File; import java.io.FilenameFilter; /* 演示listFiles方法,实现找到一个文件夹下一级子目录的所有txt文件,并把文件名打印出来 */ public class FileDemo5 { public static void main(String[] args) { //常规方法 File f = new File("e:/test"); File[] files = f.listFiles(); for (File file : files) { if(file.getName().endsWith(".txt")){ System.out.println(file.getName()); } } System.out.println("<---------------------->"); //使用FileNameFilter过滤出a.txt这个文件 //采用匿名内部类方式 File[] files1 = f.listFiles(new FilenameFilter() { public boolean accept(File dir, String name) { return new File(dir,name).getName().equals("a.txt"); } }); for (File file : files1) { System.out.println(file.getName()); } } }
1.6 递归操作(查找以及删除)
递归地查找某一类文件
import java.io.File; /* 演示递归地查找jpg文件并将文件名打印出来 */ public class FileRecursiveDemo1 { public static void main(String[] args) { findJPG(new File("e:")); } public static void findJPG(File file){ File[] files = file.listFiles(); for (File f : files) { if(f.isDirectory()){ findJPG(f); } else{ if(f != null && f.getName().toUpperCase().endsWith("JPG")){ System.out.println(f.getName()); } } } } }
递归删除文件夹
import java.io.File; /* 演示递归删除文件夹以及文件夹下所有内容 */ public class FileRecursiceDemo2 { public static void main(String[] args) { deleteDir(new File("e:/test")); } public static void deleteDir(File f){ File[] files = f.listFiles(); for (File file : files) { if(file.isDirectory()){ deleteDir(file); }else{ file.delete(); } } //文件都删除干净后,最后再把文件夹删除即可 f.delete(); } }
2. 输入流和输出流
2.1 java IO框架中各种流的继承及实现图:
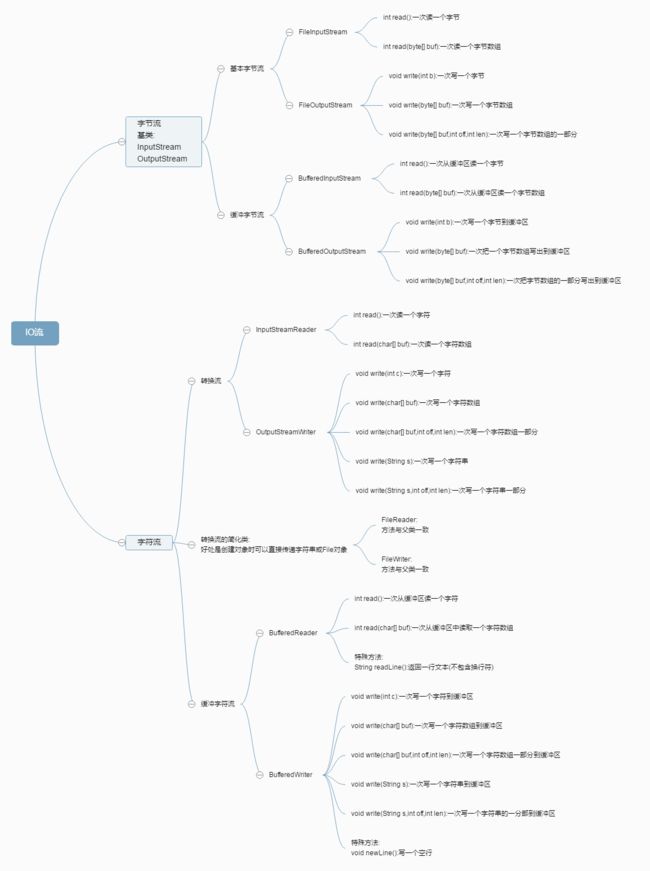
2.2 带异常处理的拷贝程序
基本思路:在try块中执行基本业务逻辑,catch中捕捉异常,记住使用Exception兜底,最后将关流操作放在finally中执行
import java.io.*; /* 演示带完整异常处理的文件拷贝程序 */ public class CopyFileDemo { public static void main(String[] args) { BufferedReader br = null; BufferedWriter bw = null; try { br = new BufferedReader(new FileReader("e:/test/a.txt")); bw = new BufferedWriter(new FileWriter("e:/test/b.txt")); String line = null; while((line = br.readLine()) != null){ bw.write(line); bw.newLine(); } } catch (FileNotFoundException e) { System.out.println("File Not Found !!!"); } catch (IOException e){ System.out.println("IO Exception !!!"); } catch (Exception e){ System.out.println("Unknown Exception !!!"); }finally { if(br != null){ try { br.close(); } catch (IOException e) { } } if(bw != null){ try { bw.close(); } catch (IOException e) { } } } } }
新版try-catch语句,可以将需要关闭的流使用try(){}形式放在小括号内,这样就不用再写finally块就能自动关流了
import java.io.*; /* 演示带完整异常处理的文件拷贝程序升级版 */ public class CopyFileDemo2 { public static void main(String[] args) { try ( BufferedReader br = new BufferedReader(new FileReader("e:/test/a.txt")); BufferedWriter bw = new BufferedWriter(new FileWriter("e:/test/b.txt")); ){ String line = null; while((line = br.readLine()) != null){ bw.write(line); bw.newLine(); } } catch (FileNotFoundException e) { System.out.println("File Not Found !!!"); } catch (IOException e){ System.out.println("IO Exception !!!"); } catch (Exception e){ System.out.println("Unknown Exception"); } } }
2.3 三种方式触发流的关闭
import java.io.BufferedOutputStream; import java.io.FileOutputStream; /* 演示三种方式触发流的关闭 */ public class StreamCloseDemo { public static void main(String[] args) throws Exception { //test1(); //test2(); test3(); } public static void test1() throws Exception { //使用close方法关闭流 BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("e:/test/a.txt")); bos.write("hello world".getBytes()); bos.close(); } public static void test2() throws Exception{ //手动刷新 BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("e:/test/a.txt")); bos.write("hello world".getBytes()); bos.flush(); } public static void test3() throws Exception{ //当写出的字节数大于等于8192的时候,就会自动触发关流 BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("e:/test/a.txt")); bos.write(new byte[8192]); } }
对于第三种方式,对比图如下:
当写出的字节数为8191的时候,文件字节大小为0字节,说明并未关流

而当写出字节数为8192的时候,文件字节正好为8KB,说明写出成功!

2.4 数据流
由于后期在用到hadoop中的时候会涉及到ComparableWritable接口的重写方面的知识,因此这里需要关注,特别关注writeInt方法的底层实现!可以查看这些方法的底层源码!
import java.io.DataInputStream; import java.io.DataOutputStream; import java.io.FileInputStream; import java.io.FileOutputStream; /* 演示数据流的基本方法: 1.数据流具有丰富的API可以读写各种各样的数据类型而不用每次都调用getBytes()方法 2.注意,若用数据流将数据写出到文本文件,则会出现乱码,解决方案是再用read方法读回来 */ public class DataInputOutputStreamDemo { public static void main(String[] args) throws Exception { DataOutputStream dos = new DataOutputStream(new FileOutputStream("e:/test/a.txt")); dos.writeBoolean(true); dos.writeByte(97); dos.writeChar('b'); dos.writeInt(10); dos.writeDouble(3.14); dos.writeUTF("hello world"); //然后用相对应的方法读回来 DataInputStream dis = new DataInputStream(new FileInputStream("e:/test/a.txt")); System.out.println(dis.readBoolean()); System.out.println(dis.readByte()); System.out.println(dis.readChar()); System.out.println(dis.readInt()); System.out.println(dis.readDouble()); System.out.println(dis.readUTF()); } }
WriteInt和ReadInt的源码分析:
// writeInt
public final void writeInt(int v) throws IOException { out.write((v >>> 24) & 0xFF); out.write((v >>> 16) & 0xFF); out.write((v >>> 8) & 0xFF); out.write((v >>> 0) & 0xFF); incCount(4); }
查看了writeInt方法的实现原理,可知,它底层是通过将一个int类型的数据通过无符号右移操作从高位到低位一个一个拿出8位来实现的,而与0xFF进行与运算则保证了,除了这8位,其他位全部都是0,而readInt()方法则正好相反,将所有的获得的4个数字再进行左移操作,再加到一起去即可,具体代码如下:
public final int readInt() throws IOException { int ch1 = in.read(); int ch2 = in.read(); int ch3 = in.read(); int ch4 = in.read(); if ((ch1 | ch2 | ch3 | ch4) < 0) throw new EOFException(); return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0)); }
知道了底层原理之后,自己也可以写字节数组和int值相互转换的方法:
/* 写两个将字节数组与int值相互转换的方法 */ public class MyUtils { public static void main(String[] args) { //进行测试 int b = -256; byte[] bytes = int2Bytes(b); System.out.println(bytes2Int(bytes)); } public static byte[] int2Bytes(int i){ byte[] bytes = new byte[4]; bytes[0] = (byte) (i >> 24); bytes[1] = (byte) (i >> 16); bytes[2] = (byte) (i >> 8); bytes[3] = (byte) (i >> 0); return bytes; } public static int bytes2Int(byte[] bytes){ int i1 = bytes[0] & 0xFF << 24; int i2 = bytes[1] & 0xFF << 16; int i3 = bytes[2] & 0xFF << 8; int i4 = bytes[3] & 0xFF << 0; return i1 + i2 + i3 + i4; } }
2.5 打印流
打印流是单向的,只有输出方法,没有读取方法,但是有其特殊的打印方法,并且经过设置可以实现自动关流
import java.io.FileOutputStream; import java.io.PrintWriter; /* 演示打印流的基本操作 */ public class PrintWriterDemo { public static void main(String[] args) throws Exception { //设置成可以自动关流的那种,根据文档可知,自动关流只对println等方法有效 PrintWriter pw = new PrintWriter(new FileOutputStream("e:/test/a.txt"),true); //使用自带的特殊方法 pw.println(10); pw.println(3.14); pw.println("hello world"); } }
2.6 内存流
本质上不涉及到文件的IO,是用数组来实现的,写的时候会写出到一个无名的数组,当调用toByteArray方法时可以返回字节数组
import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; /* 演示内存流的基本方法 */ public class ByteArrayInputOutputStreamDemo { public static void main(String[] args) throws Exception { ByteArrayOutputStream baos = new ByteArrayOutputStream(); baos.write("hello world".getBytes()); byte[] bytes = baos.toByteArray(); System.out.println(new String(bytes)); ByteArrayInputStream bais = new ByteArrayInputStream(bytes); int len = 0; byte[] buf = new byte[1024]; len = bais.read(buf); System.out.println(new String(buf,0,len)); } }
2.7 RandomAccessFile(随机访问文件)
import java.io.RandomAccessFile; /* 演示随机访问文件类: 1.该类相当于是一个巨大的byte数组,即可以读文件又可以写文件 2.具有seek方法可以随便移动指针 3.有只读模式以及正常模式 */ public class RandomAccessFileDemo { public static void main(String[] args) throws Exception { //指定的模式使得它既可以读,又可以写 RandomAccessFile raf = new RandomAccessFile("e:/test/a.txt", "rw"); raf.writeByte(98); raf.writeLong(100L); raf.writeUTF("hello world"); //试验:将指针移动至第9个字节处,查看是否可以读到hello world字符串 raf.seek(9L); System.out.println(raf.readUTF()); } }
2.8 Properties类(配置文件)
此类并不是IO,但是和IO关系很紧密,查看源码可知它是继承自HashTable的,因此可以把它当成map使用
import java.io.FileInputStream; import java.io.FileOutputStream; import java.util.Properties; /* 演示一个简单的配置文件的读取以及更新等操作 */ public class PropertiesDemo { public static void main(String[] args) throws Exception { //先用一个输入流读取已经存在了的配置文件 FileInputStream fis = new FileInputStream("e:/test/prop.txt"); Properties prop = new Properties(); prop.load(fis); System.out.println(prop.getProperty("name")); //进行更新操作,如果不存在,那就是添加 prop.setProperty("id","0001"); //更新的内容还是输出到原来文件中去 //如果不想写上comments的话,可以写null,但是绝对不可以出现中文,否则就会出现乱码 prop.store(new FileOutputStream("e:/test/prop.txt"),null); } }
2.9 对象输出 / 输入流 (ObjectOutputStream / ObjectInputStream)
对象输出流使得对象,这样一个具有立体结构类型的数据能够永久化地保存在磁盘上去,(这一过程就叫做持久化,在之后的大数据学习过程中会反复接触到),这样就使得对象可以脱离程序而存在,该过程就叫做“序列化”,而"反序列化“则正好相反,将一个已经保存在磁盘上的对象再反过来读到内存中
想要序列化一个对象,必须具备这样一个前提,那就是该对象要实现Serializable接口,该接口十分特殊,方法体内没有任何代码,是一个标记性接口,相当于在告诉用户,如果对象要想序列化,就得实现这个接口,不实现它,那就不能用!
public interface Serializable { }
判断末尾的方法:之前的都要一个结束符,-1或是null,而Object却没有,因此,判断结束条件的方法不一样
需要注意的是:对象流和之前接触到的流判断是否达到文件末尾的方法不一样,由于对象流在写出到文件时,并不会在末尾添加-1或null这样的结束符,因此通过原来的方式判断是否达到文件末尾将不再适用,会抛出EOFException,解决方案是将所有的对象全部放在一个集合中,在反序列化时一次性读取整个集合即可,演示代码如下所示:
/* 演示对象流 演示解决EOFException的方案 */ import java.io.*; import java.util.ArrayList; class Employee implements Serializable { private int id; private String name; public Employee() { } public Employee(int id, String name) { this.id = id; this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "Employee{" + "id=" + id + ", name='" + name + '\'' + '}'; } } public class ObjectStreamDemo { public static void main(String[] args) throws Exception { //serialize(); deSerialize(); } //序列化方法 public static void serialize() throws Exception { //创建100个员工对象将它们放到集合中并持久化保存起来 ArrayList
3. IO的应用
3.1 切割小文件 & 合并小文件
/** * 给定需要进行切割的大文件的文件路径,需要存放小文件的目标文件夹,以及每个小文件的大小 * * @param srcFilePath 源文件的路径 * @param destDir 目标文件夹 * @param size 每个小文件的大小 */ public static void splitFile(String srcFilePath, String destDir, long size){ //先进行判断,只有源文件的大小大于等于小文件大小时,才进行切割 File srcFile = new File(srcFilePath); long srcFileLen = srcFile.length(); if(srcFileLen < size){ System.out.println("Small file's size is larger than source file's size!"); }else{ //判断能够把文件切割成几份 int count = (int) (srcFileLen % size == 0 ? srcFileLen / size : srcFileLen / size + 1); //遍历count变量,如果是最后一个小文件的话,重新计算文件长度 long len = size; for(int i = 0; i < count; i++){ if(srcFileLen % size != 0 && i == count - 1){ len = srcFileLen % size; } copyFile(srcFile,destDir,i,i * size,len); } } } /** * 将切割好的文件进行合并,合并到另一个目录下 * * @param srcDir 源文件夹 * @param destDir 目标文件夹 */ public static void mergeFile(String srcFilePath, String srcDir, String destDir){ String srcFileName = new File(srcFilePath).getName(); FileOutputStream fos = null; try { fos = new FileOutputStream(new File(destDir,srcFileName)); File[] files = new File(srcDir).listFiles(); for (File file : files) { FileInputStream fis = new FileInputStream(file); byte[] buf = new byte[1024 * 8]; int len = 0; while((len = fis.read(buf)) != -1){ fos.write(buf,0,len); } fis.close(); } } catch (FileNotFoundException e) { System.out.println("File Not Found!"); } catch (Exception e){ System.out.println("Unknown Exception!"); } finally { if(fos != null){ try { fos.close(); } catch (IOException e) { } } } } /** * * 单独将拷贝文件方法抽取出来 * * @param srcFile 源文件 * @param destDir 目标文件夹 * @param i 小文件索引 * @param offset 被切割文件的偏移量,即从哪个字节开始切割 * @param len 需要拷贝的小文件的长度 */ public static void copyFile(File srcFile, String destDir, int i, long offset, long len){ RandomAccessFile raf = null; FileOutputStream fos = null; try { raf = new RandomAccessFile(srcFile,"rw"); raf.seek(offset); byte[] buf = new byte[(int) len]; //一次性把数组读满 raf.read(buf); fos = new FileOutputStream(new File(destDir, srcFile.getName() + "_" + i)); fos.write(buf); } catch (FileNotFoundException e) { System.out.println("File Not Found!"); } catch (Exception e){ System.out.println("Unknown Exception!"); } finally { if(raf != null){ try { raf.close(); } catch (IOException e) { } } if(fos != null){ try { fos.close(); } catch (IOException e) { } } } } }
3.2 归档文件 & 解档文件
简单说明:文件归档过后若想要解档,则必须要知道文件名是什么,以及文件长度是多少,因此,在进行归档操作时,必须写入这些控制字符,然后在解档时先对这些控制字符进行解析,解析完之后才能真正地进行文件的写出
/** * 指定源文件夹,将文件夹下的所有文件夹归档至目标文件夹去 * * @param srcDir 源文件夹 * @param destDir 目标文件夹 */ public static void archiveFile(String srcDir, String destDir){ FileOutputStream fos = null; try { fos = new FileOutputStream(new File(destDir, "archive.dat")); //列出这个文件夹下的文件 File[] files = new File(srcDir).listFiles(); for (File file : files) { if(file.isFile()){ //先写文件名的长度,一个字节存放足够 int fileNameLen = file.getName().length(); fos.write(fileNameLen); //然后写真实的文件名 fos.write(file.getName().getBytes()); //写四个字节的文件内容长度,自己手写一个工具类 fos.write(int2Bytes((int) file.length())); //开始正式拷贝真实的文件 FileInputStream fis = new FileInputStream(file); byte[] buf = new byte[1024 * 8]; int len = 0; while((len = fis.read(buf)) != -1){ fos.write(buf,0,len); } fis.close(); } } } catch (FileNotFoundException e) { System.out.println("File Not Found!"); } catch (Exception e){ System.out.println("Unknown Exception!"); } finally { //关闭资源 if(fos != null){ try { fos.close(); } catch (IOException e) { } } } } /** * 将归好档的文件进行解档操作至目标文件夹中去 * * @param srcDir 已经归好档的文件所在的文件夹 * @param destDir 需要解档到的目标文件夹 * */ public static void unarchiveFile(String srcDir, String destDir) { FileInputStream fis = null; try { fis = new FileInputStream(new File(srcDir,"archive.dat")); //先用read方法读一个字节读出文件名长度的字节 int b = 0; while((b = fis.read()) != -1){ byte[] fileNameBytes = new byte[b]; //读取b长度字节数的文件名数组 fis.read(fileNameBytes); //解析出文件名 String fileName = new String(fileNameBytes); //读取4个字节的byte数组并将其还原回int值表示文件的真实长度 byte[] fileLenBytes = new byte[4]; fis.read(fileLenBytes); int fileLen = bytes2Int(fileLenBytes); //读取fileLen长度的文件真实数据 byte[] fileBytes = new byte[fileLen]; fis.read(fileBytes); FileOutputStream fos = new FileOutputStream(new File(destDir, fileName)); fos.write(fileBytes); fos.close(); } } catch (FileNotFoundException e) { //System.out.println("File Not Found!"); } catch (Exception e){ System.out.println("Unknown Exception!"); } finally { if(fis != null){ try { fis.close(); } catch (IOException e) { } } } } /** * 将一个整型数转换成字节数组 * * @param i 传入的int值 */ public static byte[] int2Bytes(int i){ byte[] bytes = new byte[4]; bytes[0] = (byte) (i >> 24); bytes[1] = (byte) (i >> 16); bytes[2] = (byte) (i >> 8); bytes[3] = (byte) (i >> 0); return bytes; } /** * 将一个字节数组还原成int值 * * @param bytes 长度为4的字节数组 * */ public static int bytes2Int(byte[] bytes){ int i1 = (bytes[0] & 255) << 24; int i2 = (bytes[1] & 255) << 16; int i3 = (bytes[2] & 255) << 8; int i4 = (bytes[3] & 255) << 0; return i1 + i2 + i3 + i4; }